Working with DynamoDB Single-Table Design¶
Single-Table Design is a common pattern recommended by AWS in which different table schemas are stored in the same table. Single-table design makes it easier to support many-to-many relationships and avoid the need for JOINs, which DynamoDB doesn't support.
Single-Table Design is a good pattern for DynamoDB, but it's not optimal for analytics. To achieve higher performance in Tinybird, normalize data from DynamoDB into multiple tables that support the access patterns of your analytical queries.
The normalization process is achieved entirely within Tinybird by ingesting the raw DynamoDB data into a landing Data Source and then creating Materialized Views to extract items into separate tables.
This guide assumes you're familiar with DynamoDB, Tinybird, creating DynamoDB Data Sources in Tinybird, and Materialized Views.
Example DynamoDB Table¶
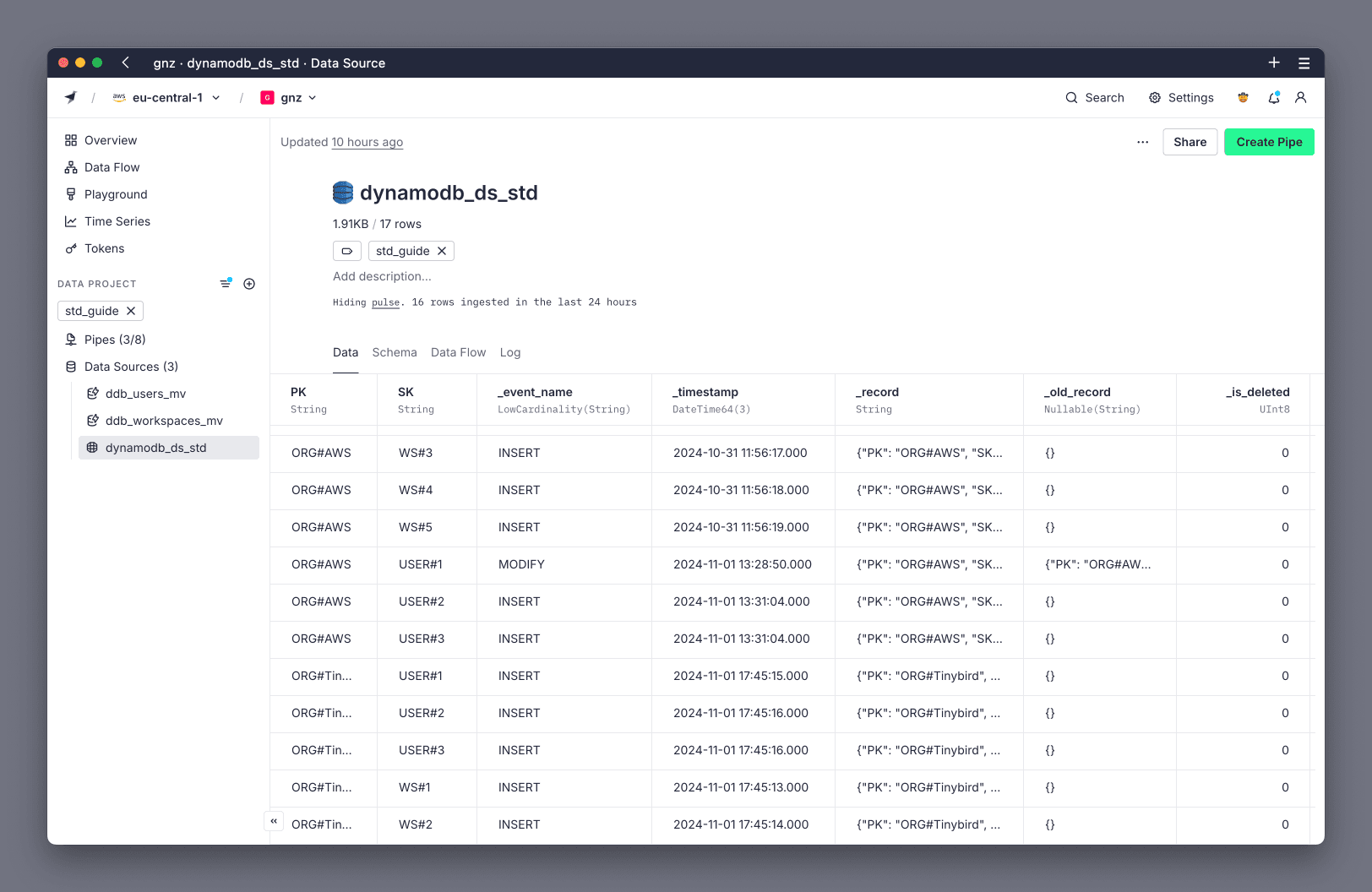
For example, if Tinybird metadata were stored in DynamoDB using Single-Table Design, the table might look like this:
- Partition Key:
Org#Org_name, example values: Org#AWS or Org#Tinybird. - Sort Key:
Item_type#Id, example values: USER#1 or WS#2. - Attributes: the information stored for each kind of item, like user email or Workspace cores.
Create the DynamoDB Data Source¶
Use the DynamoDB Connector to ingest your DynamoDB table into a Data Source.
Rather than defining all columns in this landing Data Source, set only the Partition Key (PK) and Sort Key (SK) columns. The rest of the attributes are stored in the _record column as JSON. You don't need to define the _record column in the schema, as it's created automatically.
SCHEMA > `PK` String `json:$.Org#Org_name`, `SK` String `json:$.Item_type#Id` ENGINE "ReplacingMergeTree" ENGINE_SORTING_KEY "PK, SK" ENGINE_VER "_timestamp" ENGINE_IS_DELETED "_is_deleted" IMPORT_SERVICE 'dynamodb' IMPORT_CONNECTION_NAME <your_connection_name> IMPORT_TABLE_ARN <your_table_arn> IMPORT_EXPORT_BUCKET <your_dynamodb_export_bucket>
The following image shows how data looks. The DynamoDB Connector creates some additional rows, such as _timestamp, that aren't in the .datasource file:
Use a Pipe to filter and extract items¶
Data is now be available in your landing Data Source. However, you need to use the JSONExtract function to access attributes from the _record column. To optimize performance, use Materialized Views to extract and store item types in separate Data Sources with their own schemas.
Create a Pipe, use the PK and SK columns as needed to filter for a particular item type, and parse the attributes from the JSON in _record column.
The example table has User and Workspace items, requiring a total of two Materialized Views, one for each item type.

To extract the Workspace items, the Pipe uses the SK to filter for Workspace items, and parses the attributes from the JSON in _record column. For example:
SELECT
toLowCardinality(splitByChar('#', PK)[2]) org,
toUInt32(splitByChar('#', SK)[2]) workspace_id,
JSONExtractString(_record,'ws_name') ws_name,
toUInt16(JSONExtractUInt(_record,'cores')) cores,
JSONExtractUInt(_record,'storage_tb') storage_tb,
_record,
_old_record,
_timestamp,
_is_deleted
FROM dynamodb_ds_std
WHERE splitByChar('#', SK)[1] = 'WS'
Create the Materialized Views¶
Create a Materialized View from the Pipe to store the extracted data in a new Data Source.
The Materialized View must use the ReplacingMergeTree engine to handle the deduplication of rows, supporting updates and deletes from DynamoDB. Use the following engine settings and configure them as needed for your table:
ENGINE "ReplacingMergeTree": the ReplacingMergeTree engine is used to deduplicate rows.ENGINE_SORTING_KEY "key1, key2": the columns used to identify unique items, can be one or more columns, typically the part of the PK and SK that is not idetifying Item type.ENGINE_VER "_timestamp": the column used to identify the most recent row for each key.ENGINE_IS_DELETED "_is_deleted": the column used to identify if a row has been deleted.
For example, the Materialized View for the Workspace items uses the following schema and engine settings:
SCHEMA >
`org` LowCardinality(String),
`workspace_id` UInt32,
`ws_name` String,
`cores` UInt16,
`storage_tb` UInt64,
`_record` String,
`_old_record` Nullable(String),
`_timestamp` DateTime64(3),
`_is_deleted` UInt8
ENGINE "ReplacingMergeTree"
ENGINE_SORTING_KEY "org, workspace_id"
ENGINE_VER "_timestamp"
ENGINE_IS_DELETED "_is_deleted"
Repeat the same process for each item type.
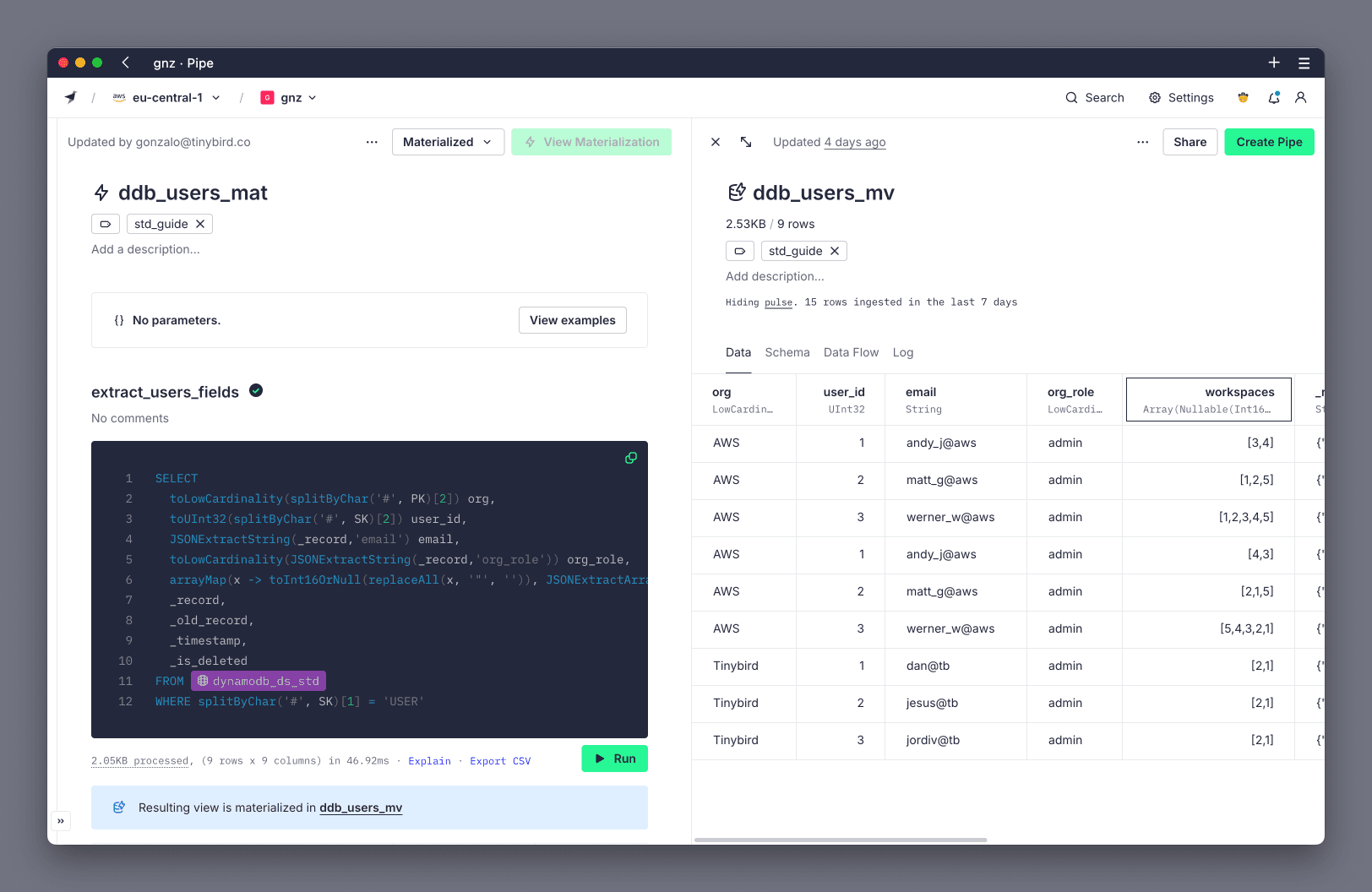
You have now your Data Sources with the extracted columns ready to be queried.
Review performance gains¶
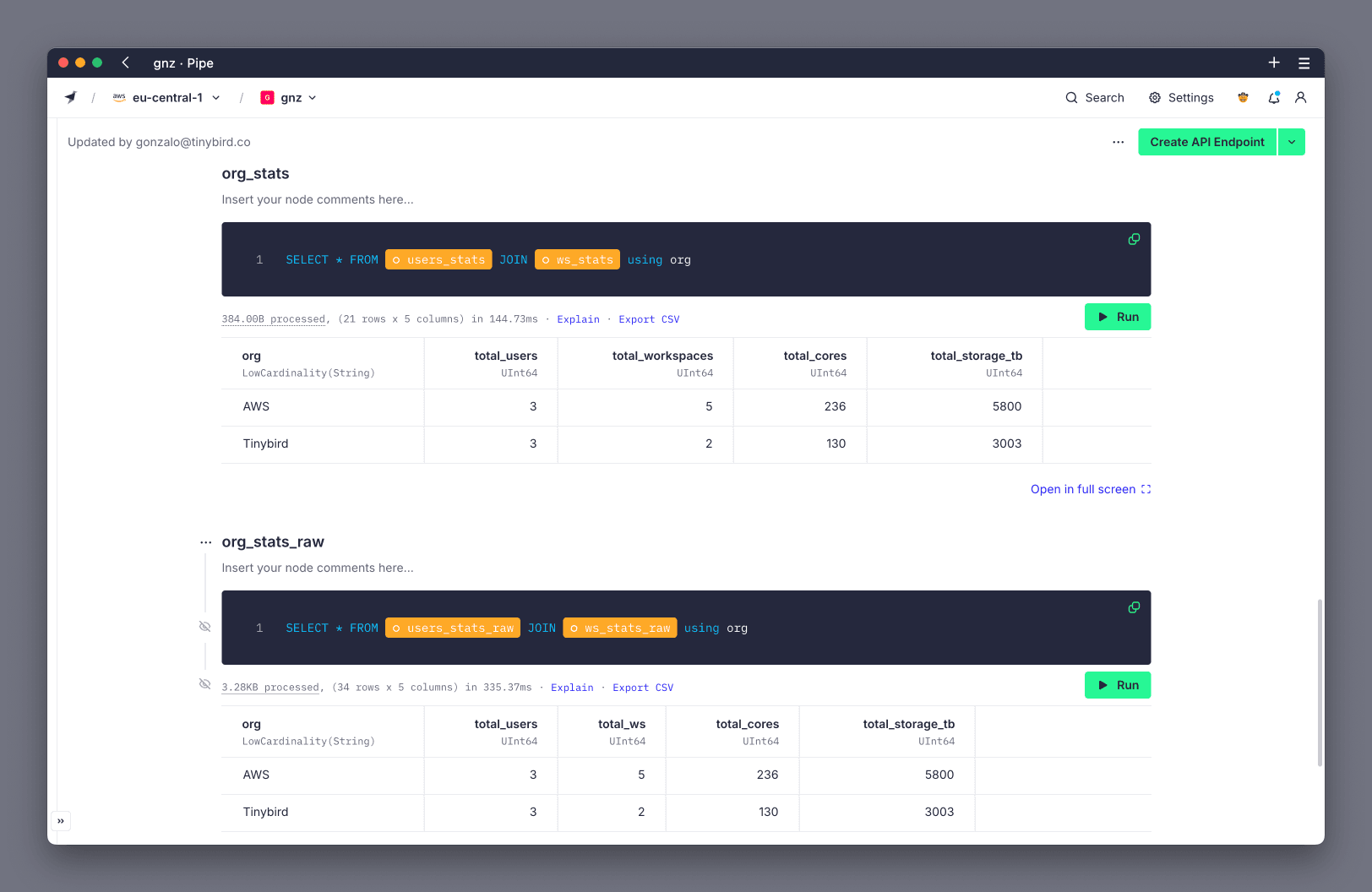
This process offers significant performance gains over querying the landing Data Source. To demonstrate this, you can use a Playground to compare the performance of querying the raw data vs the extracted data.
For the example table, the following queries aggregate the total number of users, workspaces, cores, and storage per organization using the unoptimized raw data and the optimized extracted data. The query over raw data took 335 ms, while the query over the extracted data took 144 ms, for a 2.3x improvement.
NODE users_stats
SQL >
SELECT org, count() total_users
FROM ddb_users_mv FINAL
GROUP BY org
NODE ws_stats
SQL >
SELECT org, count() total_workspaces, sum(cores) total_cores, sum(storage_tb) total_storage_tb
FROM ddb_workspaces_mv FINAL
GROUP BY org
NODE users_stats_raw
SQL >
SELECT
toLowCardinality(splitByChar('#', PK)[2]) org,
count() total_users
FROM dynamodb_ds_std FINAL
WHERE splitByChar('#', SK)[1] = 'USER'
GROUP BY org
NODE ws_stats_raw
SQL >
SELECT
toLowCardinality(splitByChar('#', PK)[2]) org,
count() total_ws,
sum(toUInt16(JSONExtractUInt(_record,'cores'))) total_cores,
sum(JSONExtractUInt(_record,'storage_tb')) total_storage_tb
FROM dynamodb_ds_std FINAL
WHERE splitByChar('#', SK)[1] = 'WS'
GROUP BY org
NODE org_stats
SQL >
SELECT * FROM users_stats JOIN ws_stats using org
NODE org_stats_raw
SQL >
SELECT * FROM users_stats_raw JOIN ws_stats_raw using org
This is how the outcome looks in Tinybird: