Build a lambda architecture in Tinybird¶
In this guide, you'll learn a useful alternative processing pattern for when the typical Tinybird flow doesn't fit.
This page introduces a useful data processing pattern for when the typical Tinybird flow (Data Source --> incremental transformation through Materialized Views --> and API Endpoint publication) doesn't fit. Sometimes, the way Materialized Views work means you need to use Copy Pipes to create the intermediate Data Sources that will keep your API Endpoints performant.
The ideal Tinybird flow¶
You ingest data (usually streamed in, but can also be in batch), transform it using SQL, and serve the results of the queries via parameterizable API Endpoints. Tinybird provides freshness, low latency, and high concurrency: Your data is ready to be queried as soon as it arrives.

Sometimes, transforming the data at query time isn't ideal. Some operations - doing aggregations, or extracting fields from JSON - are better if done at ingest time, then you can query that prepared data. Materialized Views are perfect for this kind of situation. They're triggered at ingest time and create intermediate tables (Data Sources in Tinybird lingo) to keep your API Endpoints performance super efficient.
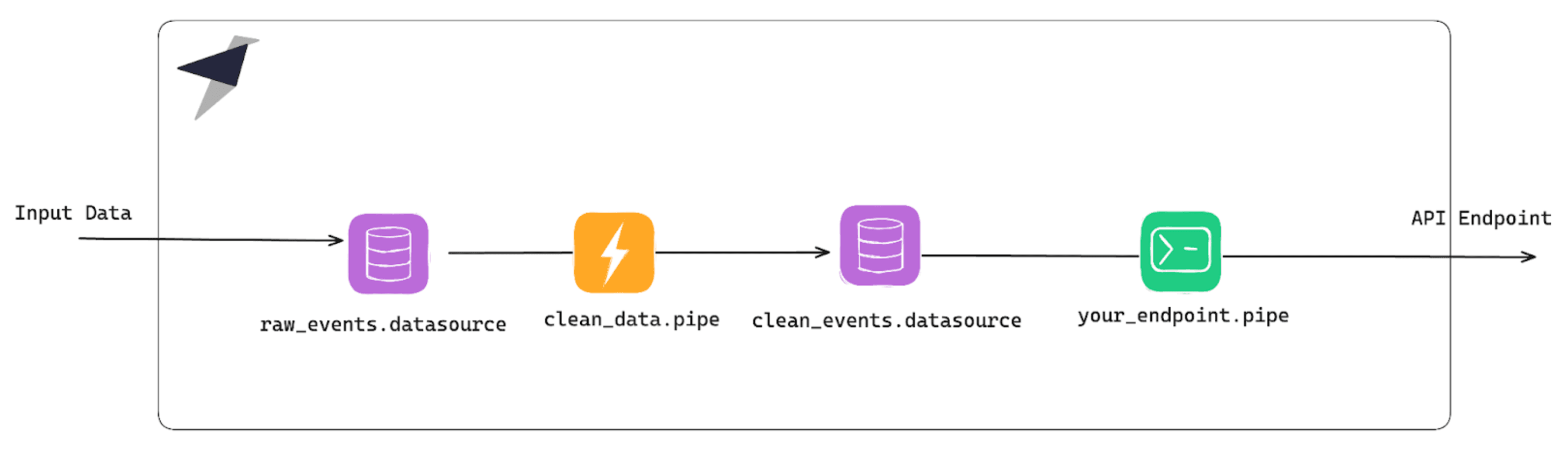
The best practice for this approach is usually having a Materialized View (MV) per use case:
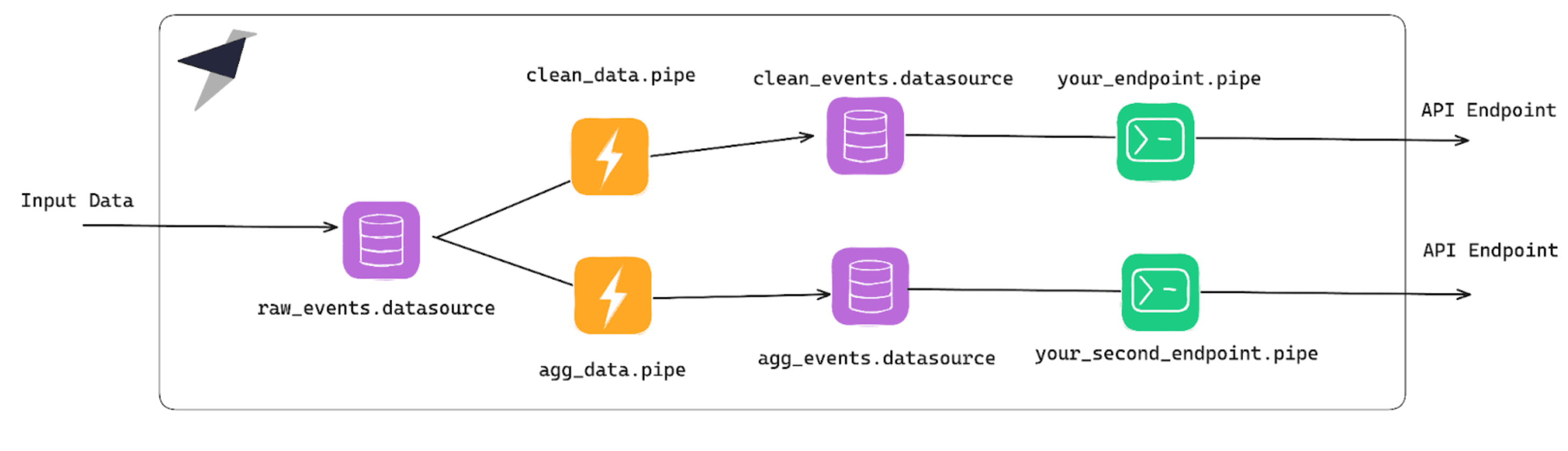
If your use case fits in these first two paragraphs, stop reading. No need to over-engineer it.
When the ideal flow isn't enough¶
There are some cases where you may need intermediate Data Sources (tables) and Materialized Views don't fit.
- Most common: Things like Window Functions where you need to check the whole table to make calculations.
- Fairly common: Needing an Aggregation MV over a deduplication table (ReplacingMergeTree).
- Scenarios where Materialized Views fit but aren't super efficient (hey
uniqState). - And lastly, one of the hardest problems in syncing OLTP and OLAP databases: Change data capture (CDC).
Want to know more about why Materialized Views don't work in these cases? Read the docs.
As an example, let's look at the Aggregation Materialized Views over deduplication DS scenario.
Deduplication in Tinybird happens asynchronously, during merges, which you can't force in Tinybird. That's why you always have to add FINAL or the -Merge combinator when querying.
Plus, Materialized Views only see the block of data that is being processed at the time, so when materializing an aggregation, it will process any new row, no matter if it was a new id or a duplicated id. That's why this pattern fails.
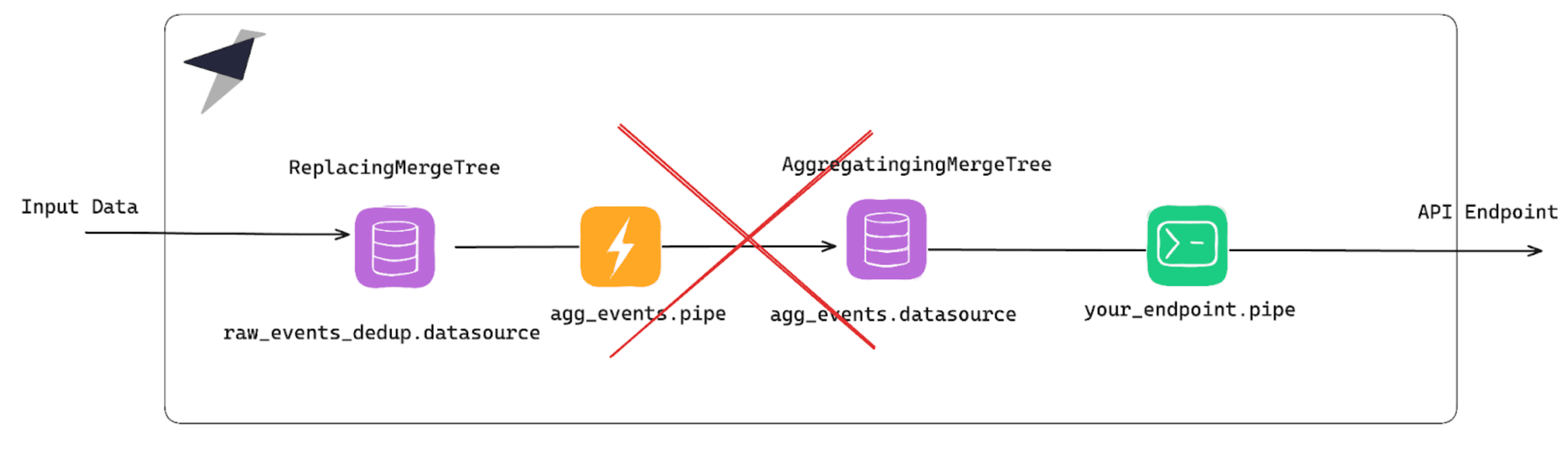
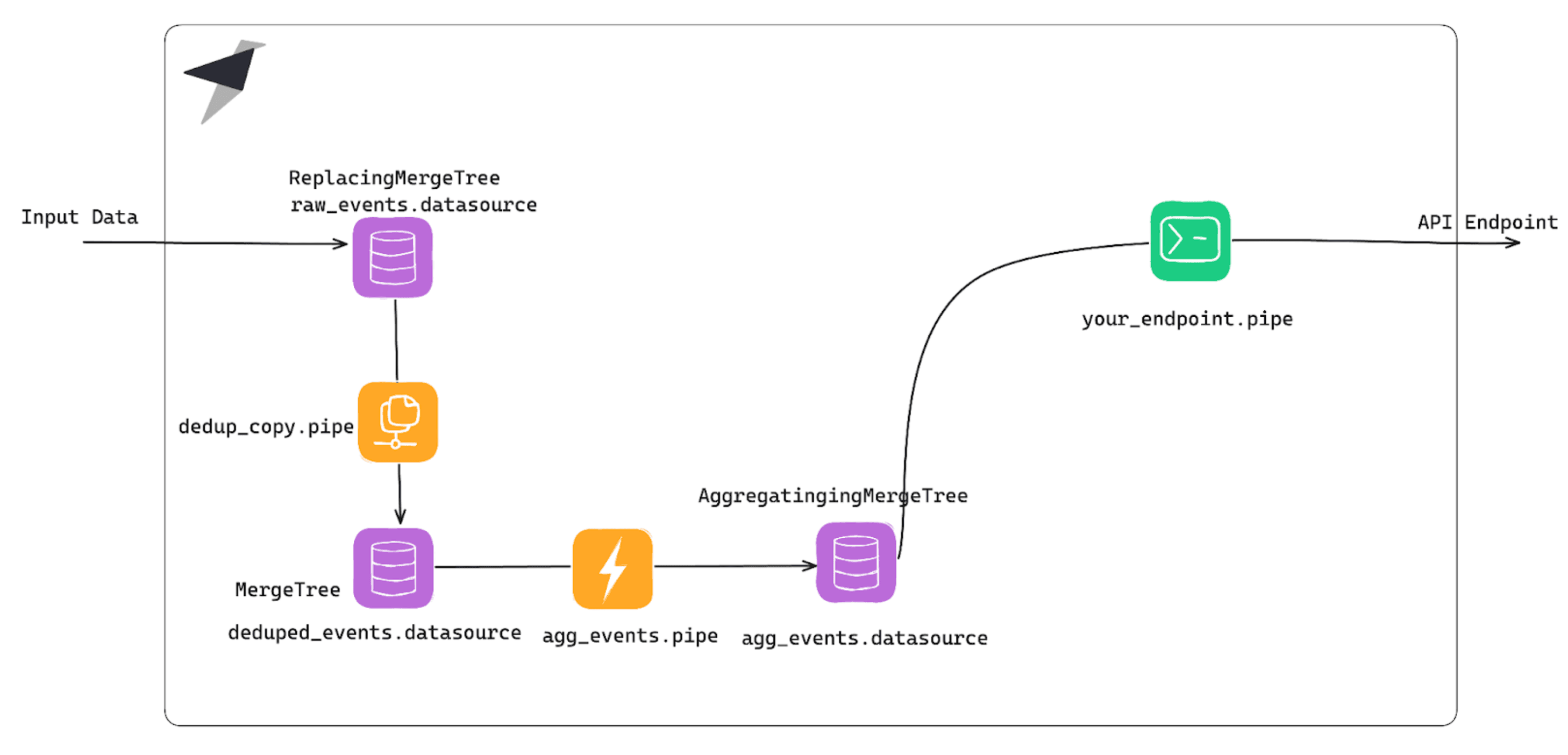
Solution: Use an alternative architecture with Copy Pipes¶
Tinybird has another kind of Pipe that will help here: Copy Pipes.
At a high level, they're a helpful INSERT INTO SELECT, and they can be set to execute following a cron expression. You write your query, and (either on a recurring basis or on demand), the Copy Pipe appends the result in a different table.
So, in this example, you can have a clean, deduplicated snapshot of your data, with the correct Sorting Keys, and can use it to materialize:
Avoid loss of freshness¶
"But if you recreate the snapshot every hour/day/whatever... Aren't you losing freshness?" Yes - you're right. That's when the lambda architecture comes into play:
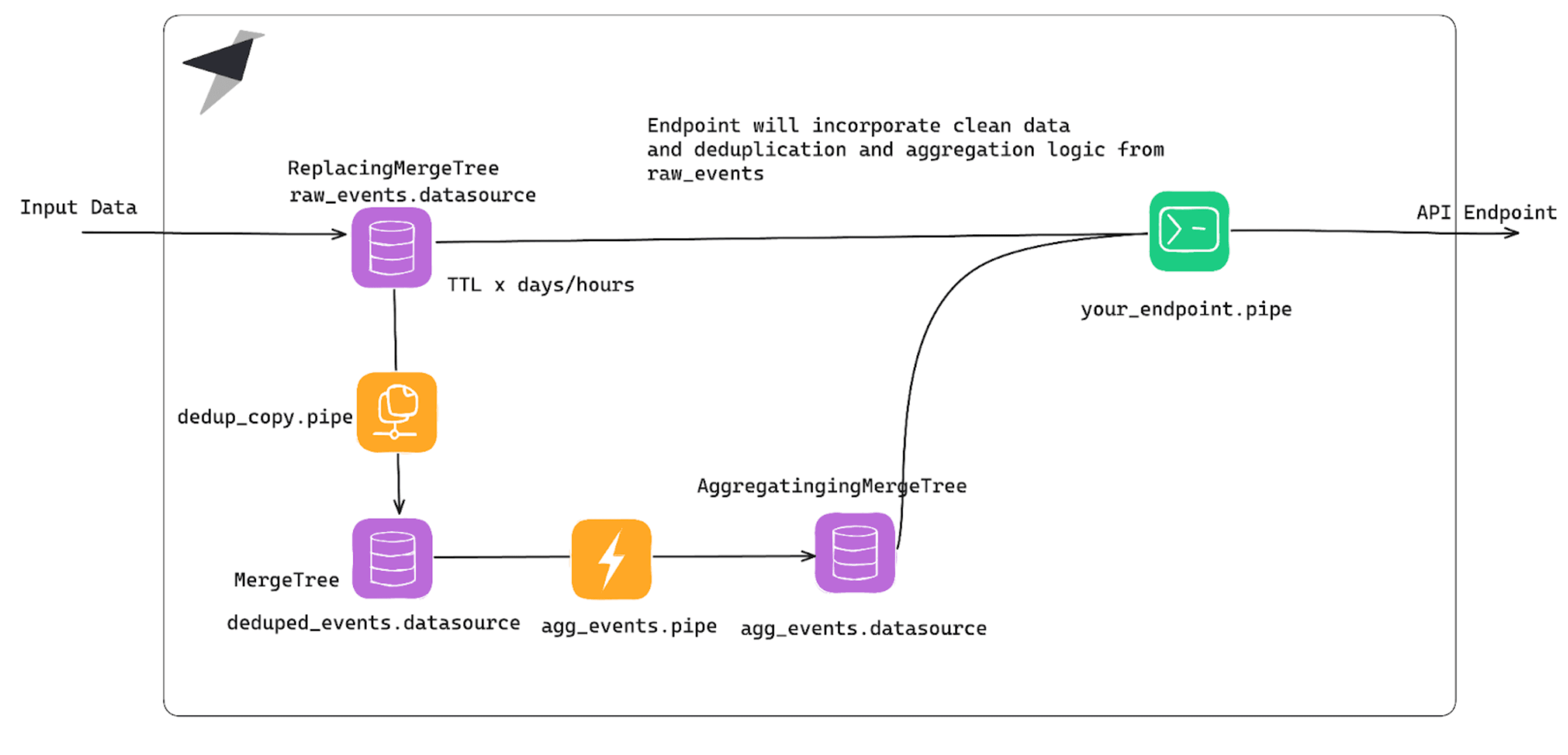
You'll be combining the already-prepared data with the same operations over the fresh data being ingested at that moment. This means you end up with higher performance despite quite complex logic over both fresh and old data.
Next steps¶
- Check an example implementation of a CDC use case with this architecture.
- Read more about Copy Pipes.
- Read more about Materialized Views.