Lambda CDC processing with Tinybird¶
This guide outlines a practical implementation of CDC processing with Tinybird using a lambda approach. It produces an API that returns the freshest deduplicated view of the data by combining a scheduled batch job with new rows since the last batch.
This is more complex than a simple deduplication query or Materialized View, recommended as an optimization where the dataset or processing SLAs demand it.
Prerequisites¶
This is a read-through guide, explaining an example, so you don't need an active Workspace to try it out in. Use the concepts and apply them to your own scenario.
To understand the guide, you'll need familiarity with Change Data Capture concepts and Tinybird deduplication strategies.
Data characteristics¶
This implementation focuses on fast filtering and aggregation of slowly-changing dimensions over a long history with high cardinality.
The test dataset is a Postgres Debezium CDC to Kafka with an event history of tens of millions of updates into ~5M active records, receiving up to 75k new events per hour. Tinybird provides low-latency, high-concurrency responses with real-time data freshness. In this example, CDC Source is configured as partial mode, i.e. only new and changed records are sent as data and deletes as a null. In full CDC you would get the old and new data in each change, which can be very helpful in OLAP processing.
The test dataset exhibits high cardinality over many years, optimized for ElasticSearch with nested JSON arrays. Updates are sparse over data dimensions and time, leading to specific decisions in this implementation. It is also worth noting that the JSON is up to 100kB per document, but for the analysis only a small part is needed.
Any given primary key of the upstream data source can be deleted or the Kafka topic compacted or reloaded, resulting in many 'null' records to handle.
Solution features¶
- Lambda processing architecture
- Split data + deletes table processing
- Null events as deletes by Kafka partition key
- Batch + speed layer CDC upsert
- Full data history table
- Full delete history table
- Batch table with good sorting keys
- Latest data as reusable API
Solution technical commentary¶
This implementation doesn't use AggregatingMergeTree or ReplacingMergeTree due to sorting key limitations. Instead, it uses a MergeTree table with subquery deduplication. The data history and delete tables are split to avoid bloat and null processing, improving performance.
It focuses on the Kafka event timestamp and partition key for deduplication. Various Tinybird functions are used for JSON extraction, avoiding nulls to speed up processing.
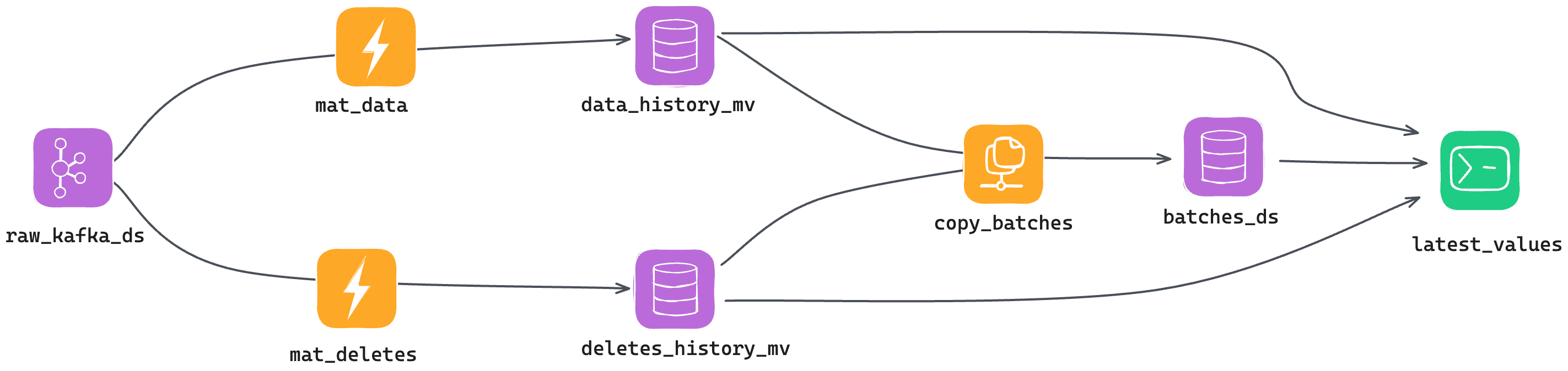
Data pipeline lineage¶
- Raw Kafka Table
<raw_kafka_ds> - Initial Materialized Views
- Data History extraction
<mat_data> - Delete History extraction
<mat_deletes>
- Data History extraction
- Historical Data Sources
- All insert/update events
<data_history_mv> - All delete events
<deletes_history_mv>
- All insert/update events
- Batching Copy Pipe
<copy_batches> - Batches Data Source
<batches_ds> - Lambda 'Upsert' API
<latest_data>
Landing Data Source¶
Where the CDC events from the Kafka topic are consumed:
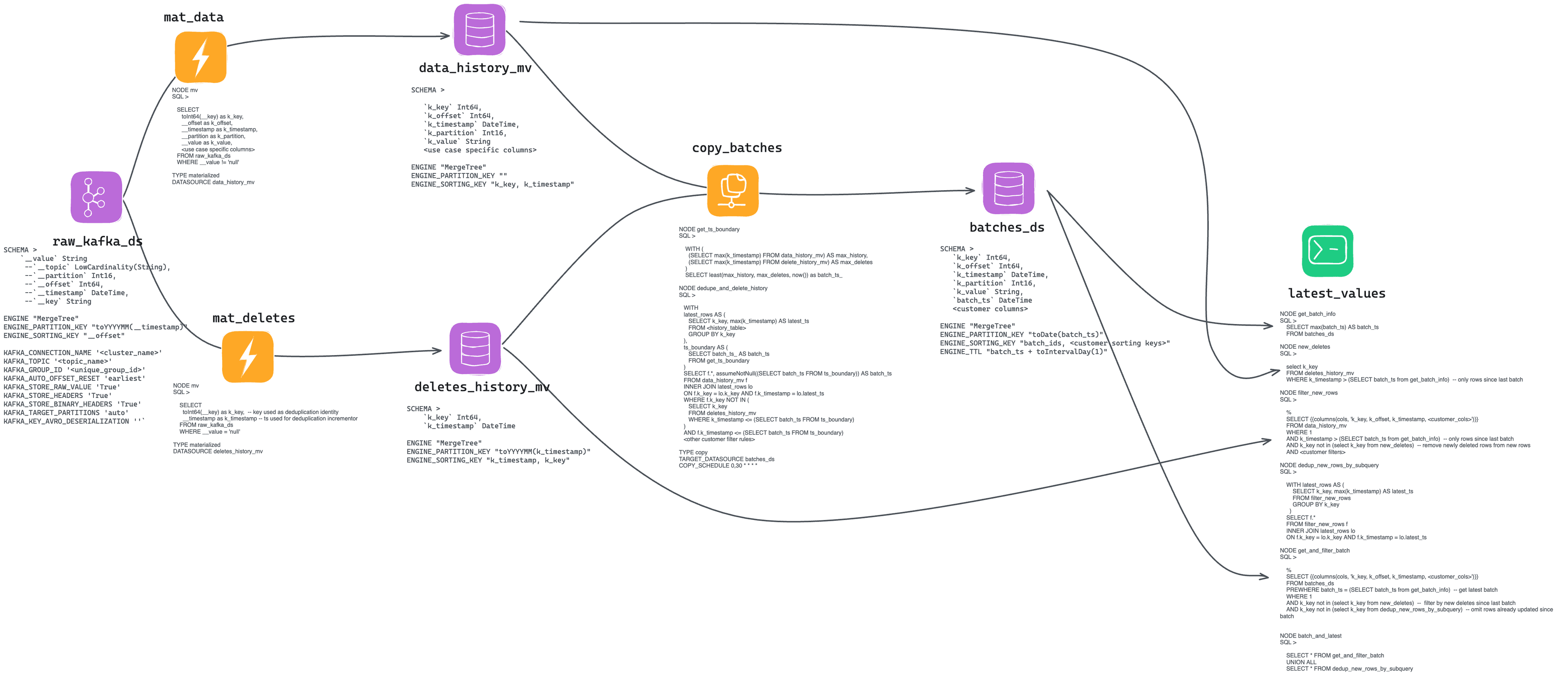
raw_kafka_ds.datasource
SCHEMA >
`__value` String
--`__topic` LowCardinality(String),
--`__partition` Int16,
--`__offset` Int64,
--`__timestamp` DateTime,
--`__key` String
ENGINE "MergeTree"
ENGINE_PARTITION_KEY "toYYYYMM(__timestamp)"
ENGINE_SORTING_KEY "__offset"
KAFKA_CONNECTION_NAME '<cluster_name>'
KAFKA_TOPIC '<topic_name>'
KAFKA_GROUP_ID '<unique_group_id>'
KAFKA_AUTO_OFFSET_RESET 'earliest'
KAFKA_STORE_RAW_VALUE 'True'
KAFKA_STORE_HEADERS 'True'
KAFKA_STORE_BINARY_HEADERS 'True'
KAFKA_TARGET_PARTITIONS 'auto'
KAFKA_KEY_AVRO_DESERIALIZATION ''
Helpful notes and top tips for your own implementation:
- The other Kafka metadata fields (commented above) like
__timestampetc. are automatically added by Tinybird's Kafka connector. - Always increment the
KAFKA_GROUP_IDif you reprocess the topic! - The
__valuemay benullin the case of aDELETEfor many CDC setups, so don't parse the JSON values in the raw table. - You can get the operation (
INSERT,UPDATE,DELETE...) from theKAFKA_STORE_HEADERSfor many CDC sources and read them in the__headersfield, though you don't need it for this implementation asINSERTandUPDATEare equivalent for our purposes, andDELETEis always thenullrecord. - The sorting key should definitely be
__offsetor__partition. CDC Data can often have high density bursts of activity, which results in a lot of changes being written in a short time window. For this reason it's often better to partition and sortraw_kafka_dsdata by__partitionand /or__offsetto avoid the skew of using__timestamp. - Remember that you have to pair the
__keywith the__offsetto get a unique pairing, as each partition has its own offsets. This is why__timestampis a good boundary for multi-partition topics. - This implementation doesn't set a TTL as it only partially processes the
__valueschema for the given use case. If you want to create other tables out of it you'd need the data source. This also allows reprocessing if you decide you need something else out of the raw JSON. - You could optionally run a delete operation on every
__offsetbefore the__offsetof the first__valuethat isn't anullin each Partition, which would effectively truncate the table of all old compactions. This can be done in the CLI with atb datasource truncate <ds_name>command. Remember to filter by partitions with no active ingest.
Full data history¶
This section contains all the INSERT and UPDATE operations.
To generate the Materialized View you'd first need a Pipe that will result in the data_history_mv Data Source:
mat_data.pipe
NODE mv
SQL >
SELECT
toInt64(__key) as k_key,
__offset as k_offset,
__timestamp as k_timestamp,
__partition as k_partition,
__value as k_value,
<use case specific columns>
FROM raw_kafka_ds
WHERE __value != 'null'
TYPE materialized
DATASOURCE data_history_mv
Notes:
- This example treats
__keyand__timestampas the primary concern, and then parses out all the various fields the customer wants. - You want this table to have the same extracted columns as the batch table, as the Lambda process UNIONs them.
- Use the various Tinybird functions for JSON extraction, and avoid Nullable fields as it slows processing and bloats tables.
Here is the Data Source definition of the MV:
data_history_mv.datasource
SCHEMA > `k_key` Int64, `k_offset` Int64, `k_timestamp` DateTime, `k_partition` Int16, `k_value` String <use case specific columns> ENGINE "MergeTree" ENGINE_PARTITION_KEY "toYYYYMM(k_timestamp)" ENGINE_SORTING_KEY "k_key, k_timestamp"
Helpful notes:
__timestampand__keyare critical for lambda processing, so while they aren't low cardinality they are the permanent filters in later queries.- Because this example mostly cares about quick access to the most recent events, it uses
k_timestampfor partitioning. - This example keeps the raw JSON of the rest of the record in
k_valueagainst some field being wanted for later indexing. You can ignore the column in daily processing, and use it for backfill without reprocessing the entire raw topic again if you need to later. You can obviously partially extract from this for stable column indexing. - Additional sorting keys for customer queries aren't retained because you need offset and key here, however other approaches could be considered if necessary.
- All other columns are based on fields extracted from the kafka
__valueJSON. - If the sorting key columns for customer queries were limited to columns that did not change during a CDC update, then a
ReplacingMergeTreemay work here. However customer updates are often over required columns including date fields making it impractical.
Deletes history¶
This section contains the DELETE operations.
As above, you need a Pipe to get the deletes and materialize them:
mat_deletes.datasource
NODE mv
SQL >
SELECT
toInt64(__key) as k_key, -- key used as deduplication identity
__timestamp as k_timestamp -- ts used for deduplication incrementor
FROM raw_kafka_ds
WHERE __value = 'null'
TYPE materialized
DATASOURCE deletes_history_mv
Helpful notes:
- Nothing fancy - just parses out the null records by tracking the
__key. - Note converting to Int64 instead of String for better performance, as you know the key and offset are auto-incrementing integers from Postgres and Kafka respectively. This may not always be true for other CDC sources.
It results into a table with all the deletes:
deletes_history_mv.datasource
SCHEMA >
`k_key` Int64,
`k_timestamp` DateTime
ENGINE "MergeTree"
ENGINE_PARTITION_KEY "toYYYYMM(k_timestamp)"
ENGINE_SORTING_KEY "k_timestamp, k_key"
Notes:
- Sorting key order is deliberate. You want to be able to fetch only the
__timestamps since the last batch was run for lambda processing, and then you want the__keys that are to be deleted from the dataset as a list for delete processing. - You don't need to have a separate deletes table for an efficient implementation, however if you have a lot of deletes (such as in compacted and reloaded Kafka Topics for CDC) then you may find this more efficient at the cost of a little more implementation complexity. A recommended approach is to start with a single history table including both data and deletes and then optimize later if necessary.
Consolidation batches¶
Using Copy Pipes, you can generate snapshots of the state of the original table at several points in time. This will help you speed up compute later, only having to account for changes that arrived since last snapshot/batch happened.
copy_batches.pipe
NODE get_ts_boundary
SQL >
WITH (
(SELECT max(k_timestamp) FROM data_history_mv) AS max_history,
(SELECT max(k_timestamp) FROM delete_history_mv) AS max_deletes
)
SELECT least(max_history, max_deletes, now()) as batch_ts_
NODE dedupe_and_delete_history
SQL >
WITH
latest_rows AS (
SELECT k_key, max(k_timestamp) AS latest_ts
FROM <history_table>
GROUP BY k_key
),
ts_boundary AS (
SELECT batch_ts_ AS batch_ts
FROM get_ts_boundary
)
SELECT f.*, assumeNotNull((SELECT batch_ts FROM ts_boundary)) AS batch_ts
FROM data_history_mv f
INNER JOIN latest_rows lo
ON f.k_key = lo.k_key AND f.k_timestamp = lo.latest_ts
WHERE f.k_key NOT IN (
SELECT k_key
FROM deletes_history_mv
WHERE k_timestamp <= (SELECT batch_ts FROM ts_boundary)
)
AND f.k_timestamp <= (SELECT batch_ts FROM ts_boundary)
<other customer filter rules>
TYPE copy
TARGET_DATASOURCE batches_ds
COPY_SCHEDULE 0,30 * * * *
Notes:
- You use the slowest data processing stream as the batch timestamp boundary, in case one of the Kafka partitions is lagging and other typical stream processing challenges.
- This example uses a subquery and self-join to deduplicate because testing showed it as performing the best over the dataset used. Each dataset will have unique characteristics that may drive a different approach such as
LIMIT 1 BYetc. - Note the deduplication method works fine in batch, but is the same as the lambda as well.
- The schedule should be adjusted to match the customer cadence requirements.
- Note that this example uses
<=in the row selection here, and>in the selection later to ensure it doesn't duplicate the boundary row.
batches_ds.datasource
SCHEMA > `k_key` Int64, `k_offset` Int64, `k_timestamp` DateTime, `k_partition` Int16, `k_value` String, `batch_ts` DateTime <customer columns> ENGINE "MergeTree" ENGINE_PARTITION_KEY "toDate(batch_ts)" ENGINE_SORTING_KEY "batch_ids, <customer sorting keys>" ENGINE_TTL "batch_ts + toIntervalDay(1)"
Notes:
- You can't use a TTL to simply keep the last 3 versions, so you must pick a date and monitor that batches are running as expected (Tinybird won't consider the whole table in a TTL query, just that row).
- This Table forms the bulk of the rows used for the actual query process, so it's important that the sorting keys are optimized for data results.
- The
batch_idremains at the head of the sorting key so you can quickly select the latest batch for use. - The
batch_idis a simple timestamp boundary of all rows across all Partitions included in the batch, including all Deletes already applied to the batch. This is important when understanding the logic of the Lambda processing later. - Partition key is by day on the
batch_tsso you can read as few rows as possible, but all sequentially. - Analysis of the customer sorting keys may yield good optimization information, such as a need for controlling index granularity if they handle a lot of multi-tenant data, for example.
Lambda Pipe¶
Lastly, you get the latest snapshot plus all the changes since then, and consolidate. This API Endpoint can also be used as a "view" so that other Pipes query it.
latest_values.pipe
NODE get_batch_info
SQL >
SELECT max(batch_ts) AS batch_ts
FROM batches_ds
NODE new_deletes
SQL >
select k_key
FROM deletes_history_mv
WHERE k_timestamp > (SELECT batch_ts from get_batch_info) -- only rows since last batch
NODE filter_new_rows
SQL >
%
SELECT {{columns(cols, 'k_key, k_offset, k_timestamp, <customer_cols>')}}
FROM data_history_mv
WHERE 1
AND k_timestamp > (SELECT batch_ts from get_batch_info) -- only rows since last batch
AND k_key not in (select k_key from new_deletes) -- remove newly deleted rows from new rows
AND <customer filters>
NODE dedup_new_rows_by_subquery
SQL >
WITH latest_rows AS (
SELECT k_key, max(k_timestamp) AS latest_ts
FROM filter_new_rows
GROUP BY k_key
)
SELECT f.*
FROM filter_new_rows f
INNER JOIN latest_rows lo
ON f.k_key = lo.k_key AND f.k_timestamp = lo.latest_ts
NODE get_and_filter_batch
SQL >
%
SELECT {{columns(cols, 'k_key, k_offset, k_timestamp, <customer_cols>')}}
FROM batches_ds
PREWHERE batch_ts = (SELECT batch_ts from get_batch_info) -- get latest batch
WHERE 1
AND k_key not in (select k_key from new_deletes) -- filter by new deletes since last batch
AND k_key not in (select k_key from dedup_new_rows_by_subquery) -- omit rows already updated since batch
NODE batch_and_latest
SQL >
SELECT * FROM get_and_filter_batch
UNION ALL
SELECT * FROM dedup_new_rows_by_subquery
Notes:
- This is a longer Pipe which is published as an API.
- It starts by determining which batch to use, which also gives you the boundary timestamp. It then fetches and processes all new rows since the selected batch, including deletes processing and deduplication. It then backfills this with all other rows from the batch, and UNIONs the results.
- It uses the same deduplication strategy as the batch processing Pipe for consistency of results.
- Note the use of the
columnsParameter. This then defaults to returning all columns, but a user can specify a subset to reduce the data fetched and processed. - This API can then be called as a Data Source by other Pipes, which can also use the same parameter names to pass through filters like columns or other customer filters that may be required.
Conclusion¶
This image explains, in detail, the full overview of this approach: A Kafka Data Source, two Materialized Views to keep track of changes and deletes, a Copy Pipe to deduplicate in batches, and a Pipe to combine all Data Sources.
Possible improvements¶
This example deliberately kept the full history, but you could speed up and store less data if the history Materialized Views are ReplacingMergeTree, or if you add a TTL long enough to be sure the changes have been incorporated to the batch Data Source.
Alternatives¶
A simpler way of achieving the latest view¶
This example is solving for many peculiarities of the test dataset, like not having a simple key for deduplication, and a large number of delete operations bloating the resulting tables. As a comparison, here's a solution you can use when your CDC case is very simple.
It's possibly less formant (since you need to extract fields at query time, filter deletes over the whole data source...) but easier and perfectly functional if volumes aren't too big. Just define the Kafka Data Source as a ReplacingMergeTree (or create a MV from raw), query with FINAL, and exclude deletes:
raw_kafka_ds_rmt.datasource
SCHEMA >
`__value` String
--`__topic` LowCardinality(String),
--`__partition` Int16,
--`__offset` Int64,
--`__timestamp` DateTime,
--`__key` String
ENGINE "ReplacingMergeTree"
ENGINE_PARTITION_KEY ""
ENGINE_SORTING_KEY "__key"
ENGINE_VER "__offset" --or "__timestamp"
An example query to consolidate latest updates and exclude duplicates:
raw_kafka_ds_rmt.datasource
SELECT * , JSONExtract(__value, 'field', type) as field --this for every field FROM raw_kafka_ds_rmt FINAL WHERE __value!='null'
Next steps¶
- Read more about using a lambda approach in your Tinybird architecture.
- Understand Tinybird deduplication strategies.