Parquet ingestion via URL¶
Parquet file ingestion via URL is now 10 times faster for large Parquet files (hundreds of megabytes). Performance gains may vary based on compression levels and the number of row groups. This optimization significantly enhances the process of backfilling historical data.
Support for Alter API to make a column Nullable and to drop columns¶
We've improved the Data Sources API > Alter endpoint, adding the ability to make a column Nullable and also be able to drop columns. This feature is particularly useful when you need to change the schema of a Data Source.
- To make a column nullable using the CLI, change the type of the column adding the Nullable type to the old one in the datafile, and push it using the
--forceoption. - To drop a column, simply remove it from the schema definition. You can't remove columns that are part of the primary or partition key.
Support DEFAULT creating a new Data Source from schema¶
When a new Data Source is generated by defining the schema, you can now add DEFAULT values to the fields:
SCHEMA >
`name` String `json:$.name`,
`city` String `json:$.city` DEFAULT 'New York',
`number` Int32 `json:$.number` DEFAULT 8
Once created, you can view the DEFAULT value from the Schema tab in the Data Source details view.
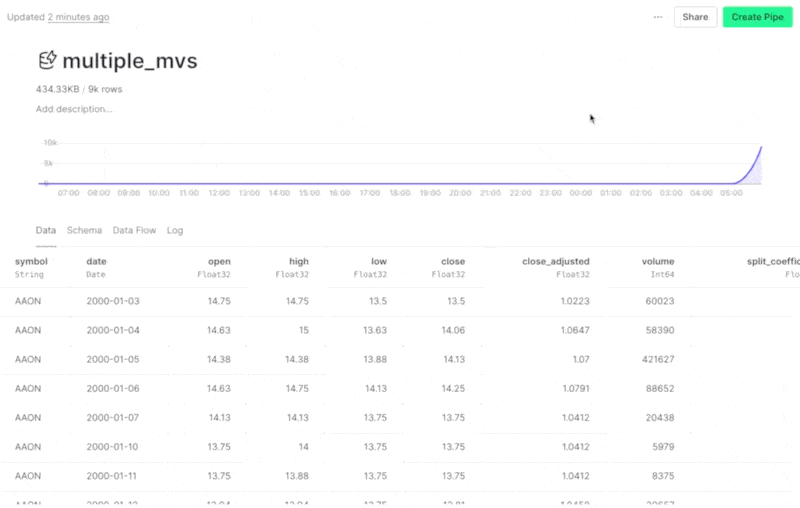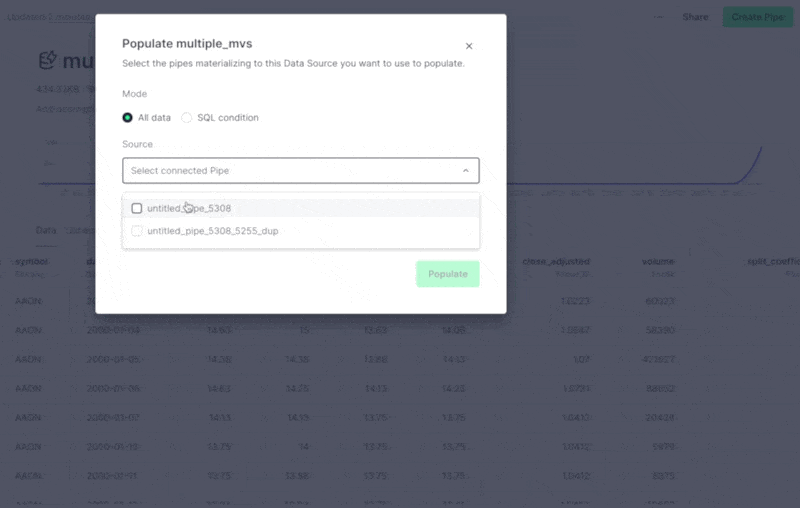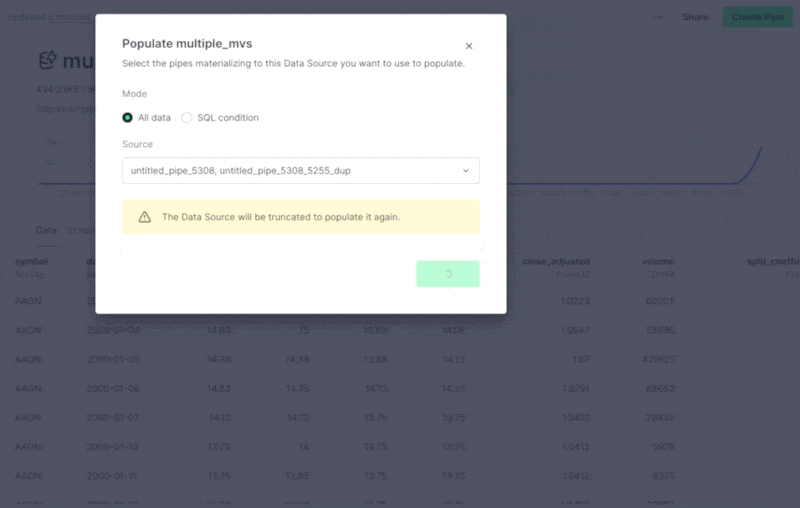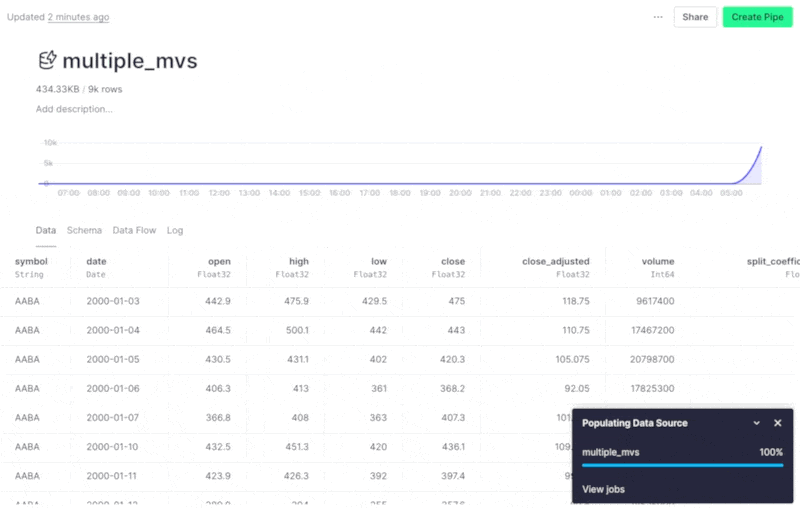
Populate a Data Source from multiple materializations in the UI¶
There are some cases where you need to populate a Data Source from multiple materializations. Now, you can do this directly from the UI! When you select Populate from the Data Source options, you can select more than one materialization to populate the Data Source.
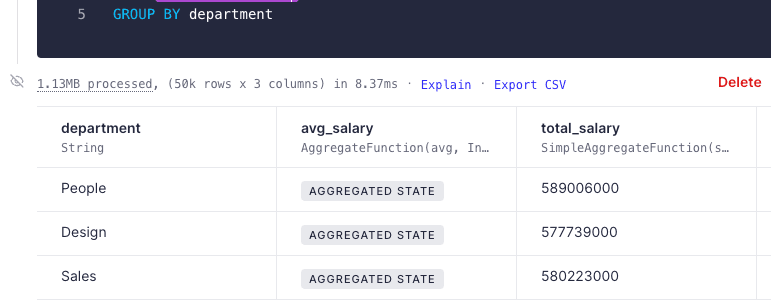
No more gibberish aggregated state!¶
We no longer show the intermediate state of aggregated columns in materialized Data Sources. This data is stored in a format unsuitable for human reading. While we haven't checked with extraterrestrial beings from outer worlds, we suspect they wouldn't be able to decipher it either. This was creating confusion among our users, especially those of you seeing these sets of random characters for the first time. Sorry about that.
Now, we show a label that better conveys that the aggregated state needs to be compacted later at query time. Hover over the label, and you'll find a hint about the function you should use at query time, and a link to our guide explaining how state works in Materialized Views.
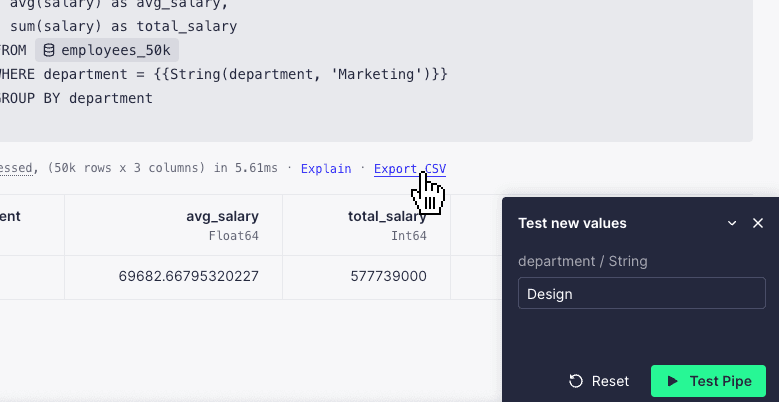
Export CSV using custom parameter values¶
You can now export CSV using custom values for your Pipe parameters. To do this, enter the "Test new values" mode, apply the value you want to explore, and select "Export CSV". ✨
Small improvements or bug fixes¶
We've improved the observability on Copy Pipes and API Endpoint query errors. Processed bytes from failed operations with code 4xx, such as timeouts or memory usage limits, are now also included in datasource_ops_log and pipe_stats Service Data Sources.