

Ever tried to show millions of viewers real-time stats about how many other people like them are watching the same event? It's a bit like trying to count grains of sand while they're being poured into your bucket. Fun times! Let's look at how to build this without breaking the bank (or your sanity).
The Challenge: Fan Engagement at Massive Scale
Imagine you're streaming a major live event and want to show each viewer some engaging stats:
- How many people in their state are watching?
- How many fans of their team are tuned in?
- What's the total viewer count in their country?
- What's the global audience size?
Sounds simple? Well, here's the catch - you need to handle:
- 3.3M concurrent viewers
- 350,000 events/second
- 17 GB/minute of incoming data
- Globally distributed
- And keep it all fresh within an average of 5 seconds (we're optimizing for cost here!)
Drawing inspiration from how FOX Sports built their near real-time internal analytics at massive scale, we're going to take it a step further. While their architecture excelled at delivering internal BI analytics, we want to extend it to power real-time viewer segmentation and engagement features for millions of concurrent viewers. We'll show you how to build upon their robust foundation to create engaging, personalized experiences.
The AWS Well-Architected Solution
First, let's look at how you might build this with AWS services. It follows AWS Well-Architected principles to ensure reliability and scale:
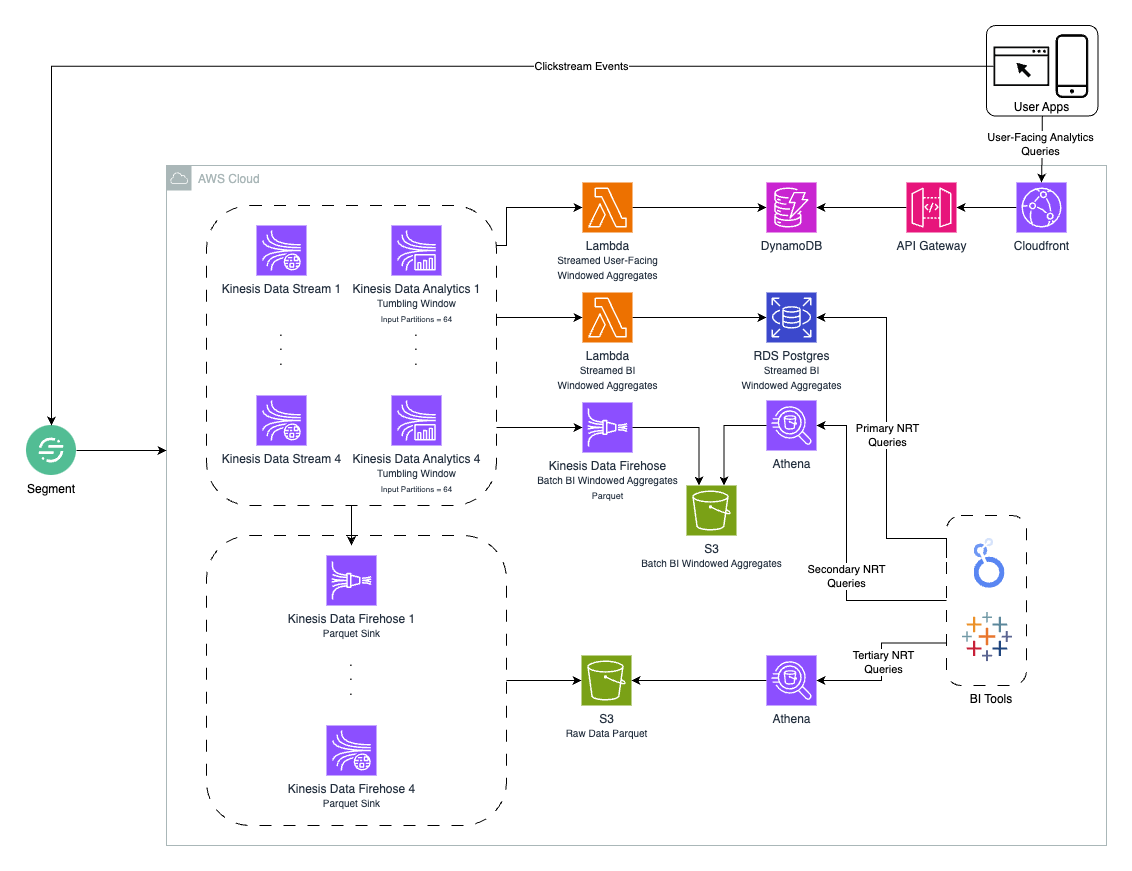
An architecture that separates concerns for reliability and scale while keeping costs in check
Component Design & Optimization
The architecture is carefully tuned to balance performance, reliability, and cost. Each choice introduces additional complexity but serves a specific performance or cost goal:
Infrastructure Choices
- Kinesis Data Streams with on-demand capacity handles unpredictable traffic patterns with 1ms ingestion latency
- Lightweight Lambda functions (128MB) provide 100ms processing time for JSON handling while keeping costs low
- CloudFront Functions reduce latency to single-digit milliseconds for JWT validation compared to Lambda@Edge
- HTTP API instead of REST API cuts request latency by 60% for simple authentication needs
Request Optimization
- JWT validation at CloudFront enables request coalescing, critical for handling traffic spikes
- Reduces backend load from millions to thousands of requests per second
- Without this optimization, DynamoDB costs would be 3-4x higher with potential throughput issues
- Each layer adds complexity but is necessary for cost management at scale
Storage Strategy
- Hot path: DynamoDB delivers consistent sub-10ms reads for real-time data
- Cloudfront provides low double-digit latencies via globally distributed PoPs
- Cold path: S3 with Parquet format (7:1 compression ratio) optimizes for analytical queries
- Geographic partitioning reduces Athena query costs by up to 90% for location-based analytics
- Each storage tier requires different access patterns and maintenance strategies
Operational Efficiency
- 4-hour runtime window for streaming components saves 80% on Kinesis costs
- 30-day data retention balancing analysis needs with storage costs
- 10-second cache TTL cuts backend requests by 95% while maintaining reasonable freshness
- Each optimization requires careful monitoring and adjustment
Data Flow
- User actions hit Kinesis Data Streams (4 of them!)
- Kinesis Analytics does the real-time number crunching
- Then things get interesting:
- Need instant stats? That's the DynamoDB path (read more about this approach here)
- Building dashboards? Off to RDS Postgres and JSON in S3 + Athena you go
- Want historical analysis? Parquet on S3 and Athena have your back
By the Numbers
Here's what you can expect performance-wise:
Near Real-time Stats (User App Path):
- Freshness: 1-11 seconds
- Query Response: 26-103 milliseconds (thank you, caching!)
Streaming Analytics (BI Tool Path):
- Freshness: 1 minute
- Query Response: 505ms
Batch Analytics Path (BI Tool Path):
- Freshness: 1 minute
- Query Response: 2.5 seconds
Ad-Hoc Analytics Path:
- Freshness: ~6. minutes
- Query Response: 35 seconds
And it'll cost you about $1,588.30 (we'll break down those numbers in detail later).
The Tinybird Approach
Remember that complex AWS architecture we just looked at? Here's the same thing with Tinybird:
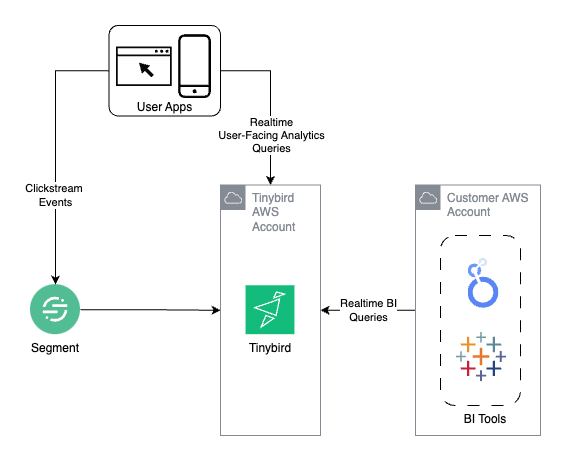
Not a typo - it's really that simple! And here's the kicker:
Performance Characteristics
- Consistent performance whether you're querying last minute's or last month's data
Near Real-time Stats (User App Path):
- Freshness: 2-3 seconds
- Query Response: 10-25 milliseconds
Optimized Aggregate Analytics (BI Tool Path):
- Freshness: 3 seconds
- Query Response: 1 second
Ad-Hoc Analytics (BI Tool Path):
- Freshness: 2 seconds
- Query Response: 6 seconds
Operational Benefits and Cost Efficiency
Simplified Total Cost of Ownership
- No separate paths needed for real-time vs historical data
- Fewer moving parts means fewer things to break
- Simpler architecture makes troubleshooting a breeze
- When something goes wrong, you're not playing detective across multiple services
Rapid Development and Iteration
- Need a new feature? Just write SQL
- Want to transform data differently? SQL
- Need to expose a new API endpoint? You guessed it - SQL
Streamlined Feature Development
Want to add new analytics? Let's see how it works in both approaches:
AWS Approach:
- Modify Kinesis Analytics application
- Update Lambda functions
- Add new DynamoDB tables/indexes
- Update the streaming aggregates in Postgres
- Modify the batch processing pipeline
- Test each component separately
- Hope everything still works together
Tinybird Approach:
Then publish it as an API endpoint. Done!
How much does it cost?
Total Monthly Cost: $1,270.91
That’s 20% less than the AWS Well-Architected Solution! To be fair, all the costs are estimated based on the expected workloads and the current published prices for both AWS and Tinybird but, even within the margins of error the Tinybird implementation puts less strain on your budget. Run this for an entire month and the differences are even more dramatic.
Implementation Considerations
| Go With AWS If: | Pick Tinybird When: |
|---|---|
| You're already deep in the AWS ecosystem | You want sub-second query latency without the headache |
| Your team dreams in Lambda functions | Your team prefers writing SQL to managing infrastructure |
| You need very specific control over data storage locations | You need to iterate quickly on new analytics features |
| You enjoy building and maintaining complex pipelines (hey, some people do!) | You don't want to manage numerous moving parts |
The Bottom Line
Both approaches can handle the scale - that's not the question. The real decision comes down to what you value more: operational and architectural simplicity or operational and architectural uniformity. If you're building something new, Tinybird's approach lets you move faster and sleep easier. But if you're heavily invested in AWS services, their solution, while more complex, might fit better into your existing workflow.
Appendix
Detailed Cost estimates
The costs for both approaches are based on published on-demand pricing - both platforms offer discounts if you're willing to commit long-term.