

Amazon DynamoDB is a commonly used database for developers on AWS for handling real-time transactional use cases. It's a fast, NoSQL key-value (KV) storage solution comparable to MongoDB. DynamoDB is often called a "real-time database," as it excels for use cases that demand high-speed transactions at scale.
Despite its speed for online transactional (OLTP) workloads, DynamoDB is not suited for online analytical (OLAP) workloads. It is highly efficient with point lookups and short-range scans thanks to its indexing and document storage properties, but it was not designed to support wide scans and aggregations typically required for analytics.
Here we will explore 3 ways to leverage the AWS ecosystem to augment DynamoDB for real-time analytics use cases. We'll discuss some ways to generate filtered aggregates on AWS infrastructure and access that data from user-facing applications. If you're already using DynamoDB as an OLTP data store and want to use the data you already have to build real-time analytics, you're in the right place.
Technical requirements for real-time analytics
In the context of app development, "real-time analytics" generally means "analytical features exposed to end users". This can be described as "user-facing analytics" and can include live dashboards, real-time personalization, fraud and anomaly detection, or other real-time analytics use cases.
Real-time, user-facing analytics must completely satisfy five technical requirements to be feasible in a production application:
- Low Query Latency. Request to the analytics service must respond in milliseconds to avoid degrading the user experience. DynamoDB can easily achieve <10 ms latency for transactional workloads but will struggle to serve analytical queries at that speed.
- High Query Complexity. Due to the nature of analytics use cases, queries may involve high levels of complexity. DynamoDB is built for point lookups. It is not built to perform long-running filtered aggregates at scale. Increasing query complexity compounds latency issues with DynamoDB.
- High Data Freshness. Also described as "end-to-end latency", data freshness is critically important for user-facing analytics applications that must avoid providing outdated information. Data should be no more than a few seconds old, if not fresher. DynamoDB is exceptionally fast in both write and read operations, but only for transactional use cases. Attempting to run complex aggregating queries over fresh transactional data still results in high end-to-end latency due to read-side performance issues.
- High Query Concurrency. Unlike traditional business intelligence use cases, user-facing analytics must satisfy the high levels of query concurrency that you'd also find in conventional transactional use cases. DynamoDB is massively concurrent for point queries, but the issues present above will hinder concurrency for any type of analytical workload.
- High Data Retention. As distinguished from stream processing use cases, real-time analytics systems must also be able to access - either in raw form or via running aggregates - long-term historical data. DynamoDB can quickly access historical data so long as it is properly partitioned and sorted, but attempting to aggregate many items across partitions will impact performance.
DynamoDB is a real-time transactional database. It is optimized for point lookups and small-range scans using a partition key, and for this transactional use case, it is massively concurrent on sub-second read/writes.
DynamoDB is not an analytical database, and because aggregates performed within analytics queries generally involve wide-range scans across multiple partitions, its performance at scale will not extend to real-time analytics use cases.
But, when DynamoDB is combined with other technologies in the AWS ecosystem, it can become a part of a cost-effective and performant real-time analytics service.
If you want to go beyond simple key value lookups and build full real time analytics on top of DynamoDB events, it helps to think about the ingestion layer as much as the database itself. This guide on real time data ingestion walks through common streaming patterns that pair DynamoDB Streams with analytical storage so you can choose the right pipeline for your AWS architecture.
In the following use cases, we will leverage DynamoDB Streams, a change-data-capture (CDC) that exposes real-time updates to DynamoDB tables to downstream services. We'll subscribe to a DynamoDB Stream and continuously update aggregates in our analytics service using a few different approaches:
- DynamoDB + Lambda + DynamoDB. In this use case, we'll use a simple AWS Lambda to calculate aggregates and write them back into another DynamoDB table.
- DynamoDB + Lambda + ElastiCache for Redis. In this use case, we'll use a very similar approach to the above, except we'll write our aggregates to ElastiCache for Redis instead of back to DynamoDB. Using Redis as a KV store will allow for low-latency lookup from our client application.
- DynamoDB + Tinybird. In this use case, we'll deploy Tinybird on AWS and leverage Tinybird's native DynamoDB Connector to backfill historical data from DynamoDB and stream upserts into Tinybird's high-performance real-time analytics service. We can then use Tinybird to publish analytics APIs that integrate into our application.
Use DynamoDB + Lambda + DynamoDB
Aggregates generally involve wide scans across partitions, a use case that DynamoDB struggles with. If we pre-calculate the aggregates externally and write them back into DynamoDB, however, we can shrink our scan size in the database and use DynamoDB more effectively.
Here we'll use AWS Lambda to calculate initial aggregates from a DynamoDB table and write them into a new table, then subscribe to updates from DynamoDB Streams on the original table to incrementally recalculate the aggregates and write them in the aggregate table.
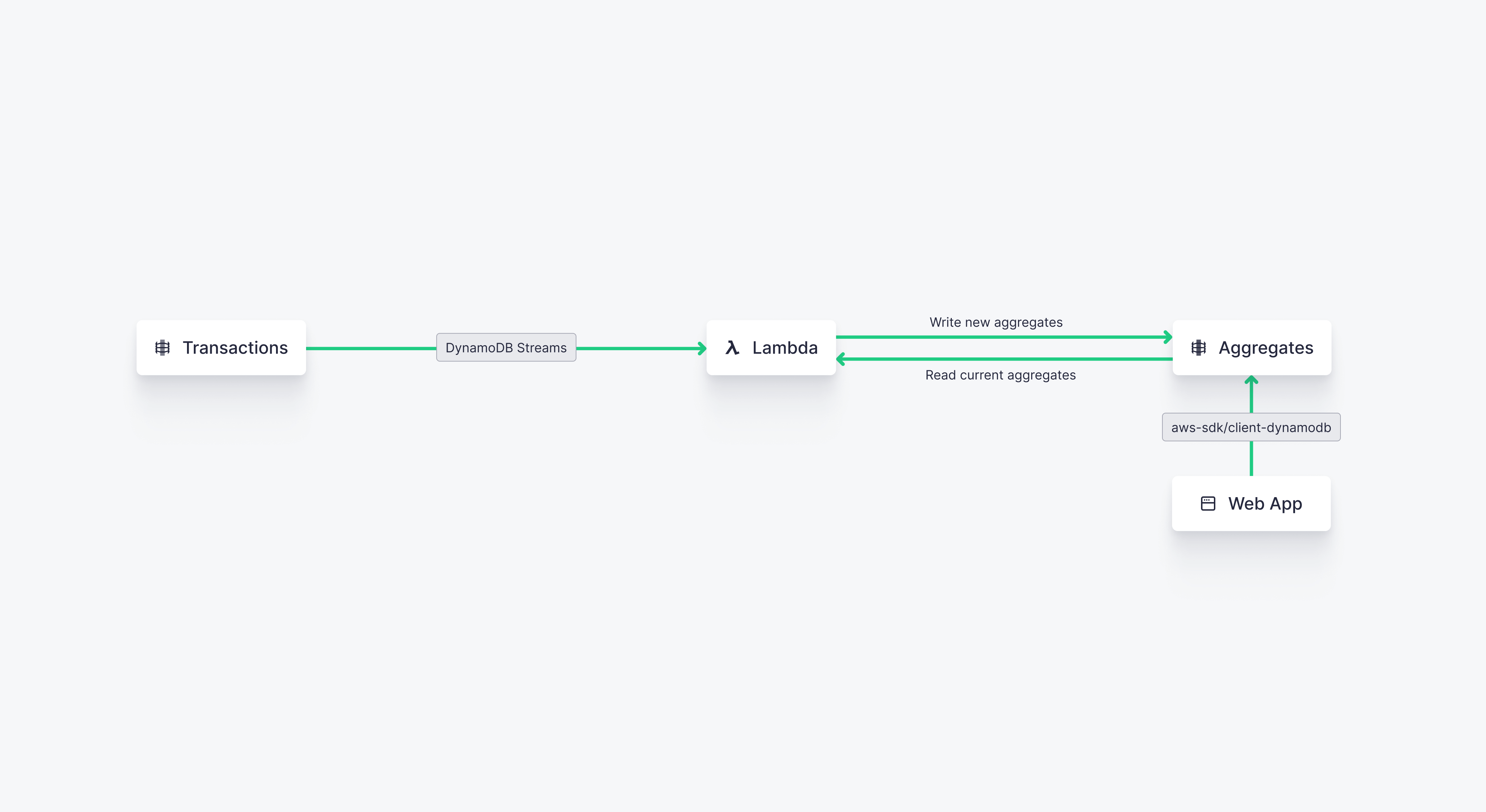
In this example use case, imagine we are building an online multiplayer game and we want to show each gamer - in real time - how their score on various levels compares to other gamers. We continuously update the scores for each gamer and each level in a DynamoDB table, and then aggregate scores across all gamers for each level in a subsequent aggregates table.
Suppose we have a table called GameScores that looks like this:
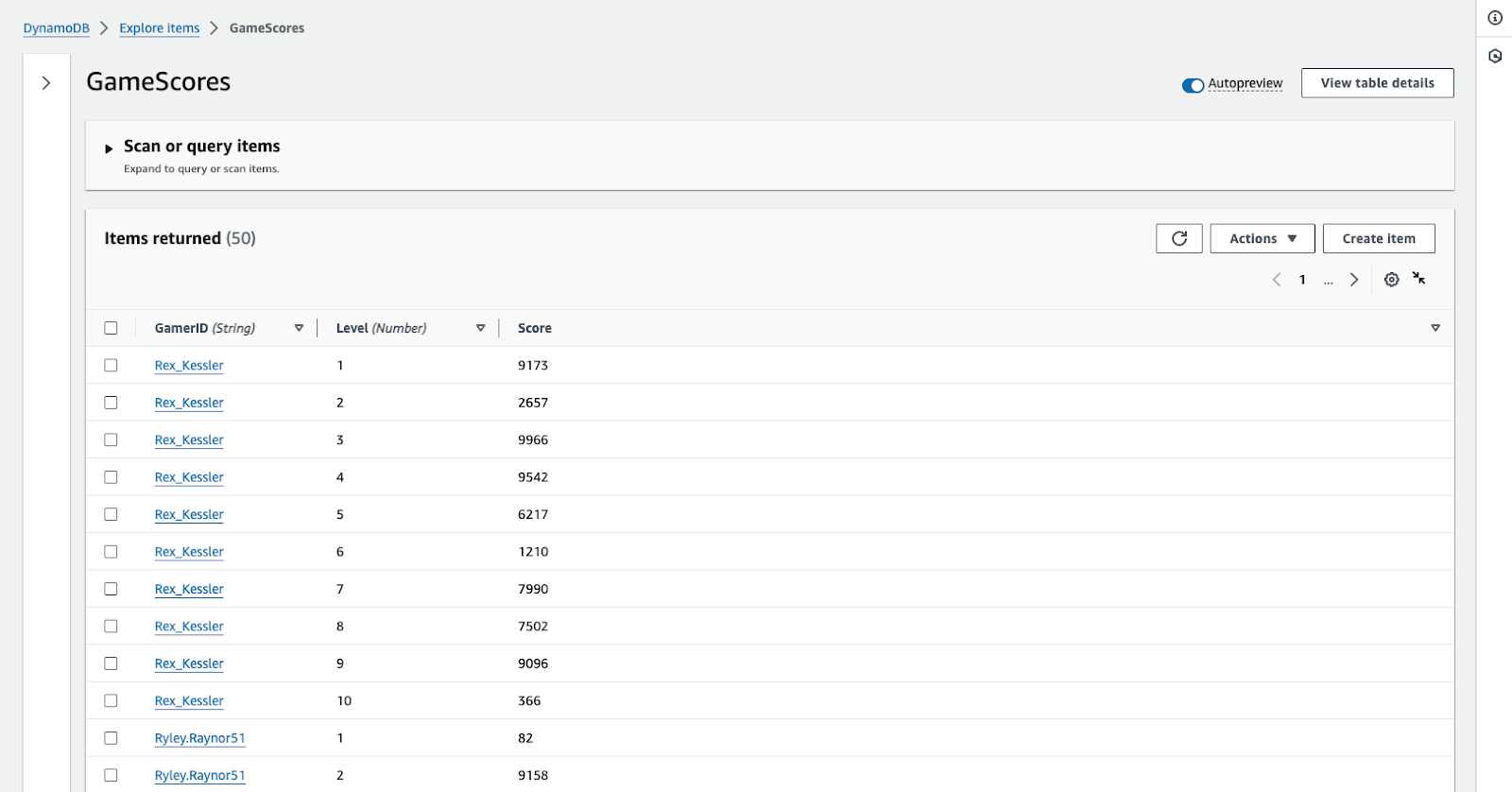
We can create a Lambda that calculates the average score for each of the 10 levels. Something like this:
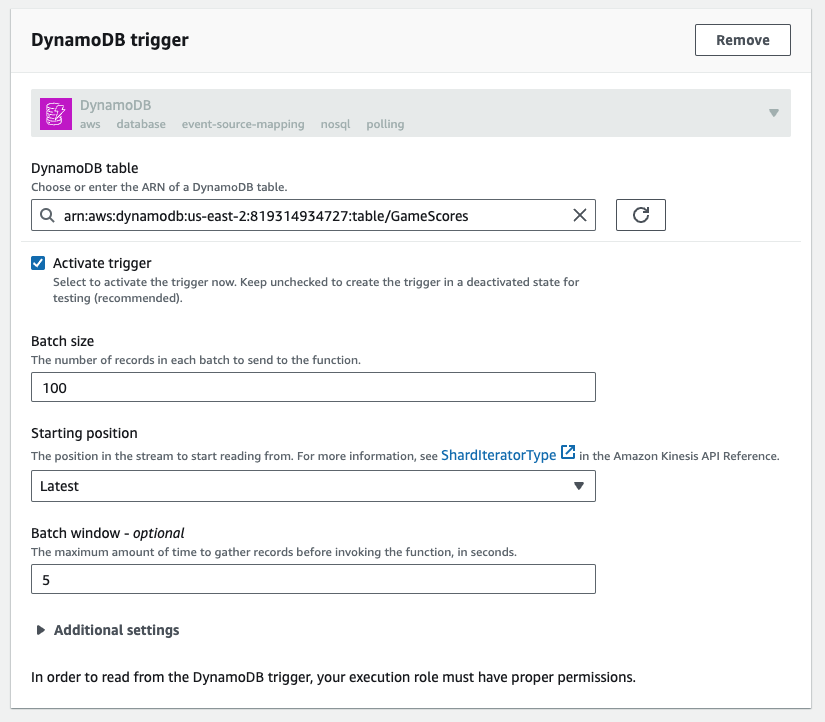
Then we can set up a trigger to run this Lambda function based on updates from the GameScores DynamoDB table. With the configuration below, we're running the Lambda every time we get 100 new updates, or every 5 seconds. You could tweak these settings depending on how fresh you need your aggregates to be.
As the Lambda function gets triggered, we'll end up with aggregates in our new DynamoDB table, AggregatedScores.
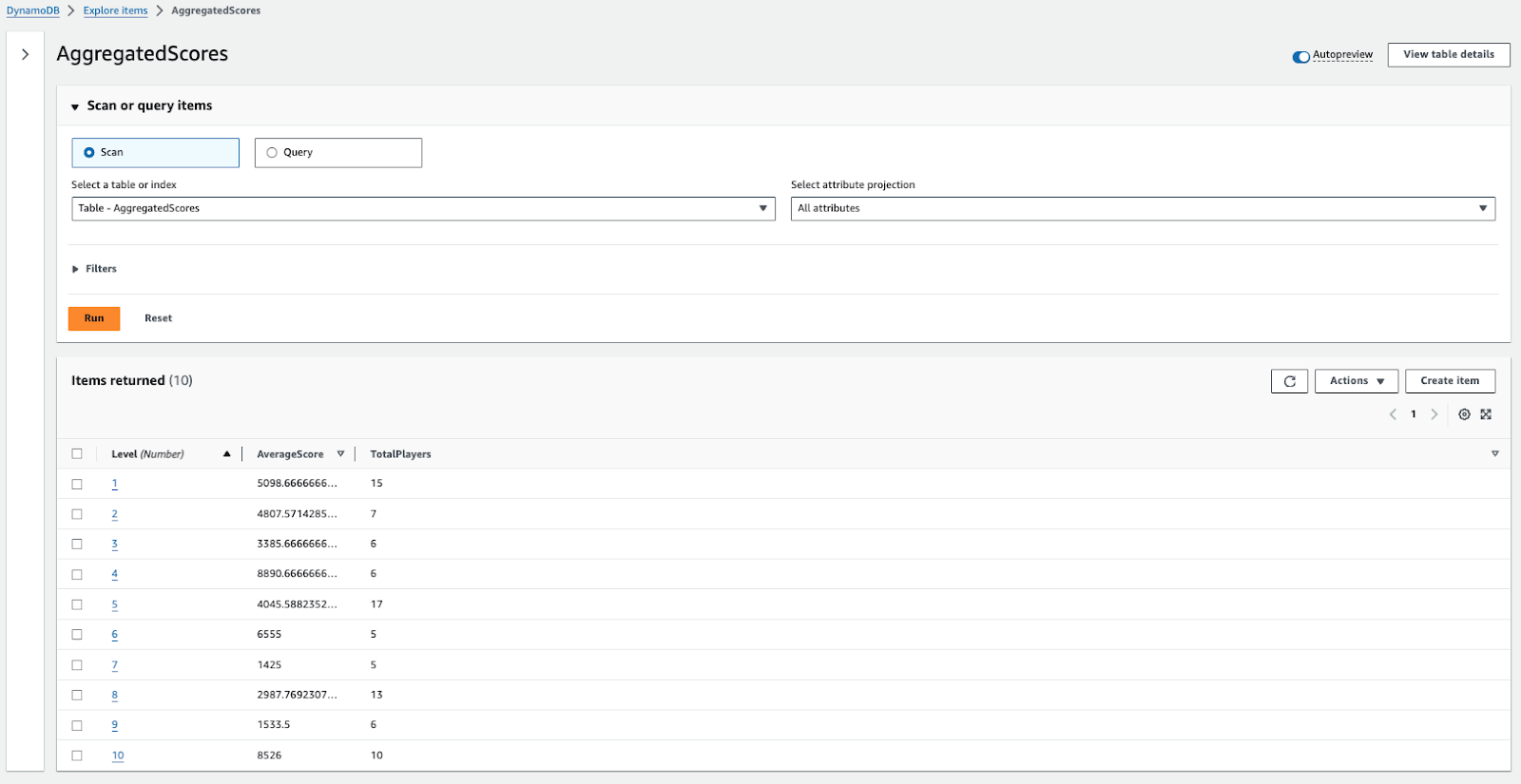
We can then query this table from within our backend to build an API for our user-facing dashboards, and since it will only ever have 10 items, the queries should return very quickly.
Pros
- This is a nice, compact approach for computing basic aggregates via serverless functions
- Stores aggregates in DynamoDB, so if you're comfortable with the database you can keep the same interface to your applications
- Lambda invocations happen quickly (and batching can be configured) to keep high data freshness
- As long as the aggregate table remains small, query latency should be very low
Cons
- This won't work for more complex aggregates that exceed the compute performance of a serverless function, and every new use case will require an additional Lambda and set of DynamoDB tables.
- As the number of items in the aggregates table increases, query latency will increase, so the total number of aggregates must be kept low.
- There's no ability to dynamically calculate aggregates, for example by time period, unless you add new keys to the aggregate table, which has the above impact of increasing query latency
- You need to ensure your DynamoDB tables have sufficient read/write capacity and that your Lambda function can handle the throughput.
- You have very little flexibility over what you can build on top of the resulting aggregates table since everything is pre-aggregated.
Use DynamoDB + Lambda + ElastiCache for Redis
This approach uses key-value store Redis to store aggregates in memory, which promises very fast updates to our user-facing analytics. In effect, we're using Redis to cache our aggregates and Lambda to keep them up to date based on changes to the DynamoDB table.
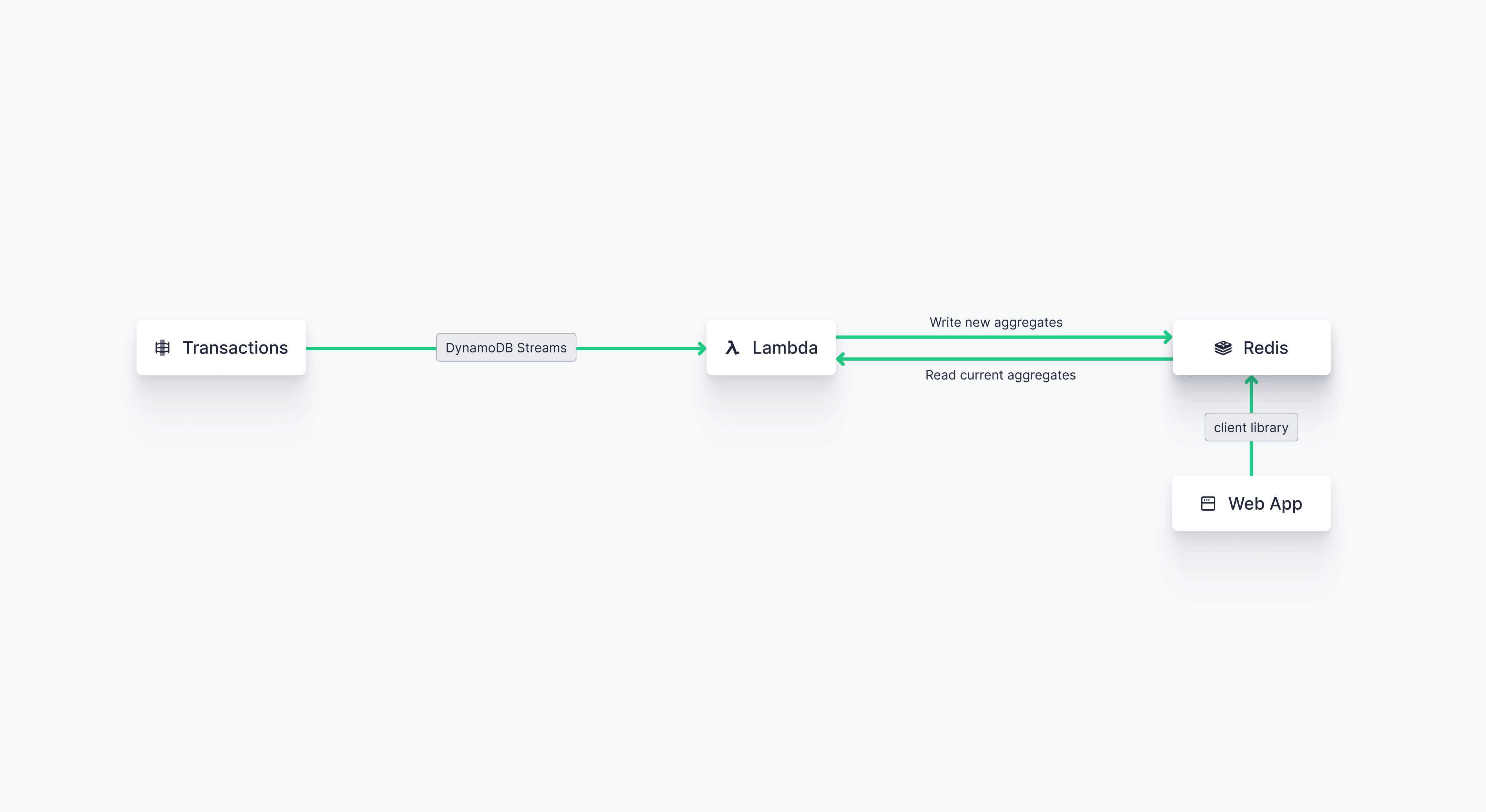
And because Redis has built-in pub/sub functionality, we can notify the user-facing web application of changes to our aggregates so that the data displayed in the application is always fresh.
You can then deploy a Lambda on the same VPC with code that looks something like this:
This will look very similar to the code from the prior approach, except in this case, we're reading and writing the aggregates from and to our Redis cache instead of a DynamoDB table.
This approach benefits from the Redis pub/sub functionality, such that any web app subscribed to updates from the cache can instantly receive updates to the calculated aggregates. There's the added benefit of flexibility; you can use this approach with any web framework that includes a Redis client library.
Pros
- Serverless, fast, and flexible
- Stores aggregates in Redis which provides a fast lookup from the client side and wide support across many web frameworks
- Lambda invocations happen quickly (and batching can be configured) to keep high data freshness
- Query latency should remain very low as long as you're doing specific KV lookups from Redis
Cons
- Same problem as above: aggregates are pre-computed and can't be accessed dynamically
- Can be challenging to backfill large, existing DynamoDB tables into Redis aggregates
- Lambda is still performing the ETL, which can become expensive as complexity grows.
Use DynamoDB + Tinybird
The above two approaches are minimally viable for static user-facing analytics on top of an existing DynamoDB table, but the cons described can become pretty glaring in a production setting. You're running an ETL on a serverless compute instance, and if the Lambda fails or the aggregation logic becomes complex, you'll have to babysit that Lambda function to make sure it can effectively handle the load.
A more ideal approach would be to perform an "extract-load-transform" (ELT) approach, where you land data from the DynamoDB table in an external database optimized for user-facing analytics, and transform the data using analytical SQL queries.
Tinybird is well suited for this approach, and you get the added benefit of Tinybird's managed DynamoDB Connector which handles the initial backfill in addition to continuous CDC updates from DynamoDB streams.
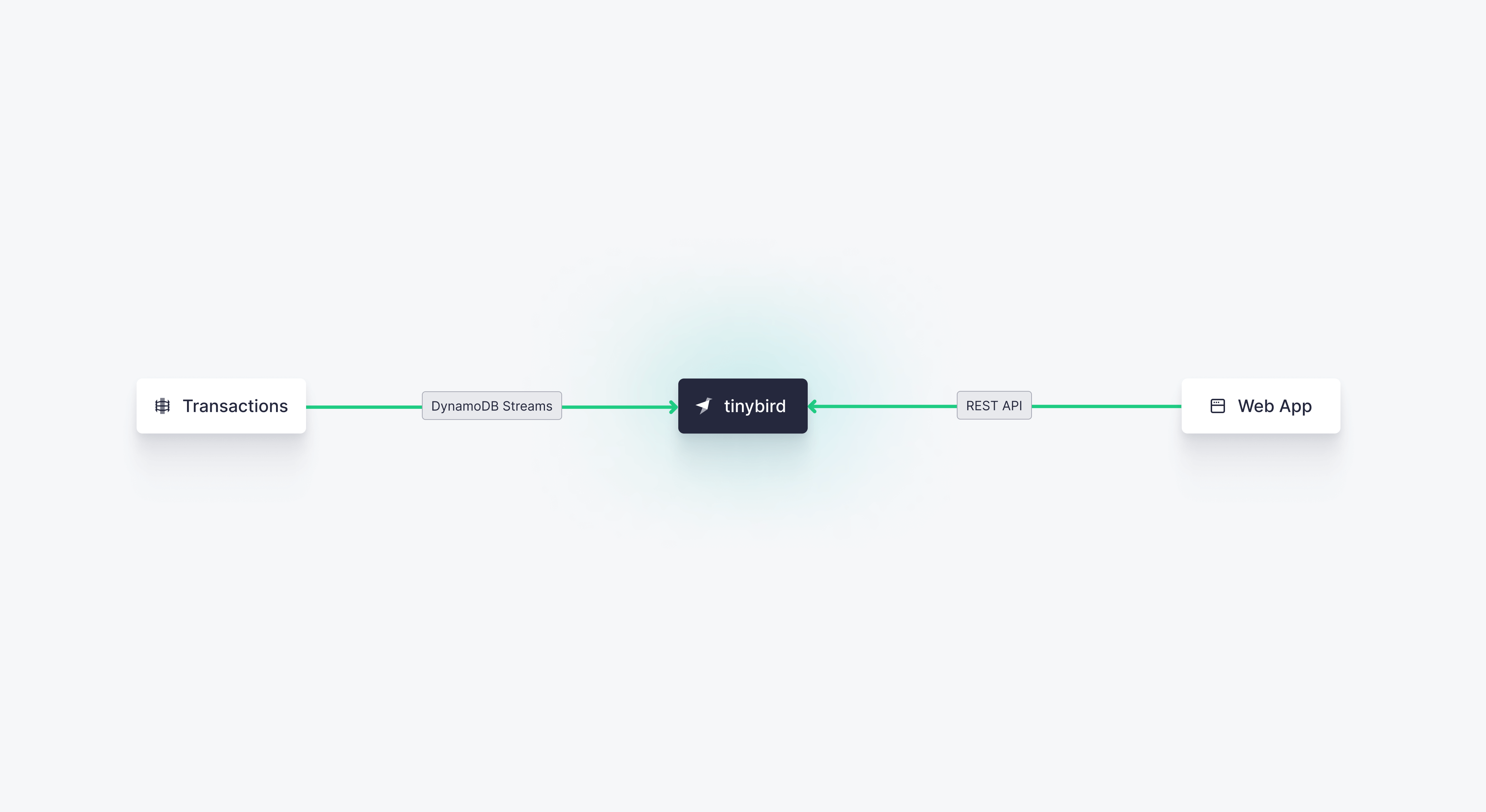
To get started with this approach, first make sure that you have enabled both Point-in-Time Recovery (PITR) for DynamoDB and DynamoDB Streams. Tinybird will use the former to perform an initial backfill, and the latter to manage streaming CDC updates.
Initialize your Tinybird Workspace
You can create a free Tinybird account and set up a Workspace in your AWS region:
You can use Tinybird's CLI the rest of the way. Install the CLI in a Python virtual environment with
Then authenticate to your Workspace using the user admin token you can get from your Workspace:
Go ahead and initialize an empty Tinybird data project:
Connect DynamoDB to Tinybird
Create a connection to DynamoDB with:
You'll be prompted to open the AWS Console where you'll create an IAM policy to allow Tinybird to read from your DynamoDB Stream. Tinybird will automatically generate the policy code, you just need to add your DynamoDB table name and the name of an S3 Bucket that Tinybird can use to backfill data from DynamoDB using PITR (which needs to be enabled).
An example policy JSON looks like this:
You'll then be prompted to create a Role that Tinybird can assume, and attach that policy. Paste the ARN for that role into the CLI and provide a name for the connection (e.g. DynamoDBGameScores), and Tinybird will create the connection to DynamoDB.
Create a Tinybird Data Source from DynamoDB
Once you've established the DynamoDB connection, you can define a table in Tinybird to store the replicated GameScores table. Whereas DynamoDB has limited support for data types, Tinybird allows support for many different data types, allowing you to define your schema.
An example Tinybird Data Source schema (defined in a .datasource file), could look like this:
Push this Data Source to the Tinybird server with:
Tinybird will begin backfilling a snapshot of the DynamoDB table. Once the backfill is complete, Tinybird will continually receive change streams from the DynamoDB Stream and keep the state of the Tinybird Data Source matched to the DynamoDB table with a few seconds of latency (or less).
From there, generating aggregates is as simple as writing SQL. With Tinybird, you can even use templating to define dynamic query parameters in your Pipes.
Create a Pipe file called gamer_score_percentile.pipe in the /pipes directory of your Tinybird data project and paste the following code:
Push this to the Tinybird server with:
Here's the best part: When you push this to Tinybird, it is instantly published as a dynamic REST Endpoint. You can supply values for the gamer_id and level query parameters, and get your response in JSON. For example:
returns:
Note that this query took all of 5 milliseconds to run on Tinybird, so performance is not an issue.
Pros
- Serverless and very fast (<5 ms query latency in our example)
- Provides an interface to query DynamoDB tables with SQL
- Tinybird automatically handles both backfill and CDC upserts
- Aggregates can easily be calculated at query time using Tinybird, which is optimized for these kinds of queries
- Infinitely flexible. Tinybird provides an SQL interface to calculate any necessary aggregates, including a templating language for dynamic filtering and advanced logic.
- Easy to integrate with any web app, as queries are instantly published as named, dynamic REST endpoints.
Cons
- Incurs some added storage costs, as the DynamoDB table is replicated into Tinybird
- Tinybird can be deployed on AWS regions but is separate from AWS management console (though Tinybird can be purchased within the AWS Marketplace)
Wrap-up and resources
Here we've provided instructions for three ways to build a real-time analytics pipeline with DynamoDB. While the first two approaches provide a very basic way to calculate static aggregates within the AWS ecosystem, the final approach provides simplicity, flexibility, and performance by pairing Tinybird with DynamoDB using Tinybird's native DynamoDB Connector.
Tinybird is a data platform for building real-time, user-facing analytics. Companies like Vercel, Canva, FanDuel, and more use Tinybird to unify data from various data sources - including DynamoDB - and build real-time analytics APIs with SQL.
Get started with Tinybird
To start building with Tinybird, sign up for a free account. The Build Plan includes 10 GB of storage and 1,000 daily API requests, with no credit card required and no time limit.
For more information on building real-time analytics on DynamoDB with Tinybird, check out these resources: