Most applications tend to be built around a “transactional” core. Buy a thingamajig. Cancel a whoosiwatsie. Edit a whatchamacallit. You might be booking flights, posting bird pics on Insta, or patronizing the local Syrian restaurant for lunch (tabouleh, anyone?). While CRUD transactions are the foundation of applications, many are now are starting to offer (or see user demand for) analytical experiences: travellers want to see price change history to find the best time to fly, content creators want to see post engagement to know what content performs best, and restaurants want to know which dishes just hit right on a Friday evening.
You can choose from many different databases to handle these CRUD workloads. Much like we all have a favorite kombucha flavor (right?), we tend to have an ol’ faithful database that we call upon time and time again. For me, it’s a split between Postgres and DynamoDB. Both highly capable, with a few differences that push me one way or the other depending on what I’m building. If you’re already building on AWS, have no particular need for the “relational” aspect of Postgres, and dream of scaling your app higher than the peak of Everest, DynamoDB is a great choice. It will grow with you from zero to world domination, and have pretty minimal operational overhead along the way.
DynamoDB exists to serve these kinds of CRUD operations and deliver a consistently fast user experience at any scale. And it does that exceedingly well. But, databases tend to be built for a specific use case or usage pattern. It's a lot to expect that one database can handle every single workload. Some are optimized for fast, frequent operations on individual records. While others are optimized for crunching huge aggregations over billions of rows. And while many databases are functionally capable of doing both, they are highly optimized for one or the other (or try to optimize for both and do neither amazingly). DynamoDB is no exception.
There is no argument that DynamoDB is an infinitely capable database for OLTP workloads. But the design decisions to make it so performant for that workload make it unsuitable for other workloads, namely online analytical processing (OLAP) workloads. And that’s made obvious in that it doesn’t even try to support them; you can’t run aggregations within the DynamoDB API.
There are several patterns for supporting analytical workloads on top of DynamoDB. In this post, I'll focus on building an architecture that demands both transactional and analytical workloads, how to combine DynamoDB and Tinybird to achieve this, and how each of these databases is optimized for their specific workload.
Understanding our requirements
To help tie this architecture together, let's pretend I’m building a corporate travel booking app. I won’t be going through code here, but if you want to see how it's actually built, check out the travel booking demo repo.
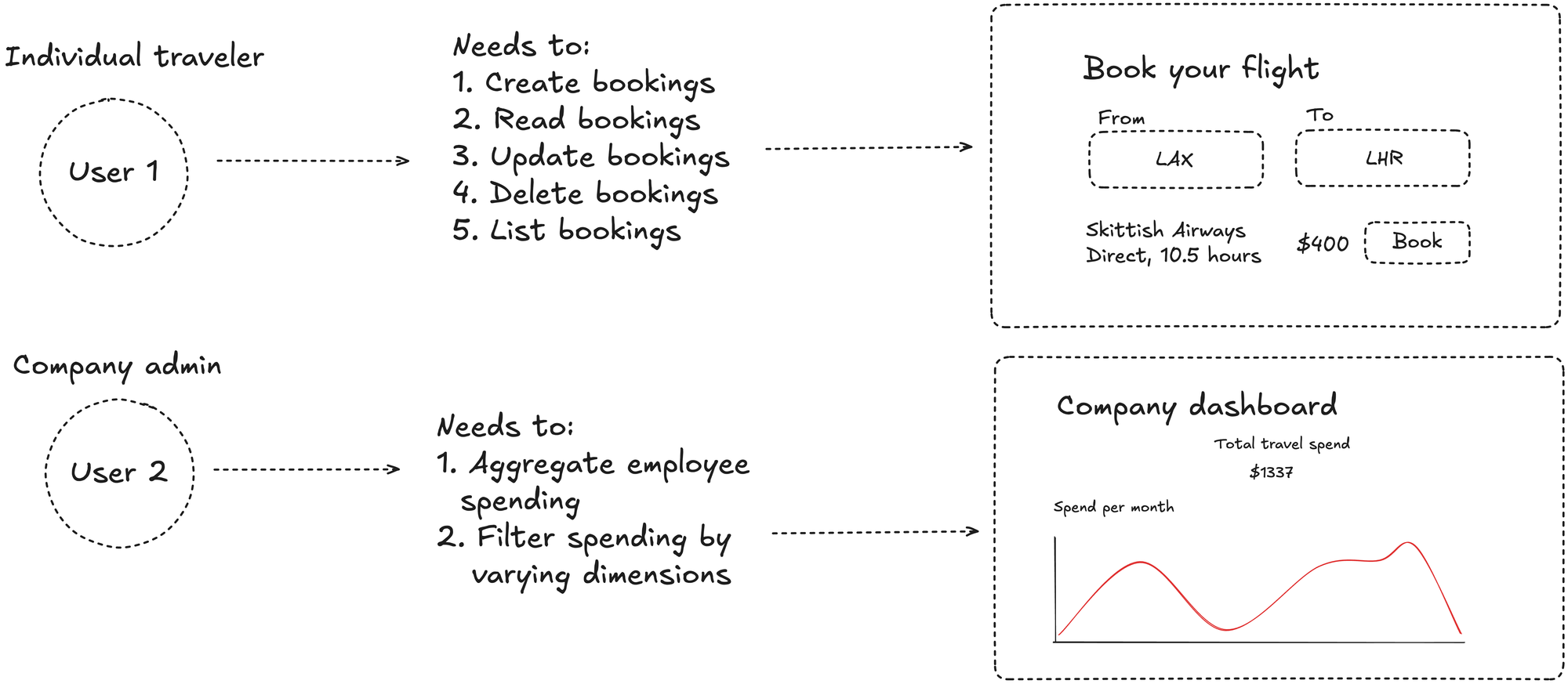
Consider two different types of users with different requirements:
(User 1) An individual corporate traveler who needs to…
- Create a new booking
- Read an existing booking
- Update an existing booking
- Delete or cancel an existing booking
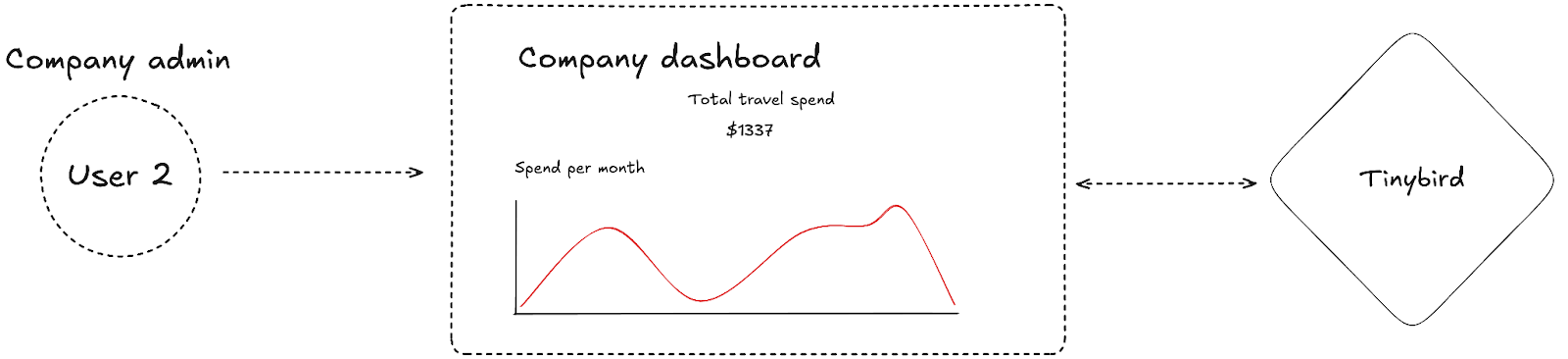
- List my bookings
(User 2) A company administrator responsible for corporate travel spending who needs to…
- Aggregate employee spending
- Filter spending by varying dimensions, such as time, travel method, etc.
You might not be building a travel app, but most applications likely have similar requirements: multiple types of users with different requirements, some transactional, some analytical.
I have two kinds of users, and each of those users has a different job to do that requires different access patterns to the data in our app. User 1 is primarily transactional, needing to use app features that are satisfied by our standard “CRUDL” operations. However, User 2 has primarily analytical needs, looking in aggregate over the data to understand what is and has happened.
Using the right tool for the job
Our application has both transactional and analytical needs. In both cases, we want to support many concurrently active users, high ingestion throughput, and low latency reads, so we need to make tooling choices accordingly. We'll use Amazon DynamoDB to handle our transactional access patterns, while Tinybird will cover the user-facing, analytical workloads.
Each of these databases is uniquely optimized for the job at hand. DynamoDB is purpose-built for individual record level operations. Creating, reading, updating, and deleting entries is super fast and, importantly, maintains consistent performance at any scale for these kinds of operations.
On the other hand, Tinybird is purpose-built to handle fast, fresh, and frequent access to data for analytical queries. Data is ingested in real-time as a continuous stream, made immediately available to query, and sorted to support highly efficient filtering, data skipping, and aggregating.
How DynamoDB handles transactional workloads
Let’s first focus on the standard "CRUDL" operations to satisfy the core functionality of our app.
In our example, these were:
- (C) create a booking
- (R) read a booking
- (U) update a booking
- (D) delete a booking
- (L) list several bookings
These operations underpin the core, day-to-day usage of our app. As a user moves through the app, different views will need to call these to display data to the user. Users tend to navigate back and forth quite a lot, so it’s pretty likely that every user will make many calls to our read and list endpoints. Create, update, and delete endpoints are likely accessed less frequently, but are perhaps more important, as these operations are effectively tied to a successful outcome of our app, and thus, revenue. If they are slow, we risk losing a user due to the poor experience, and if they fail, we don’t actually complete the business transaction, and everyone loses. So, we need great performance, we need to handle frequent access, and we need durability.
We also know that, in this access pattern, there are consistent parameters we’ll be using to find relevant records. Each booking has a unique ID, and each booking belongs to a company (which also has a unique ID). We’ll always use one, or both, of these keys to access this data.
This makes Amazon DynamoDB a perfect fit for our use case.
Again, DynamoDB is not only performant, but its performance is consistent and predictable as it scales. If we design our app to achieve a particular latency for each operation, we should be able to maintain that latency whether we have 100 records or 10 billion. This is super important for guaranteeing the quality of our user experience.
That consistency is made possible by certain design decisions that dictate what you can and can’t do in DynamoDB. Two of the most important constraints are:
- Every single record must include a primary key
- You (almost) always need to query using the primary key
Handily, our needs fall within those constraints.
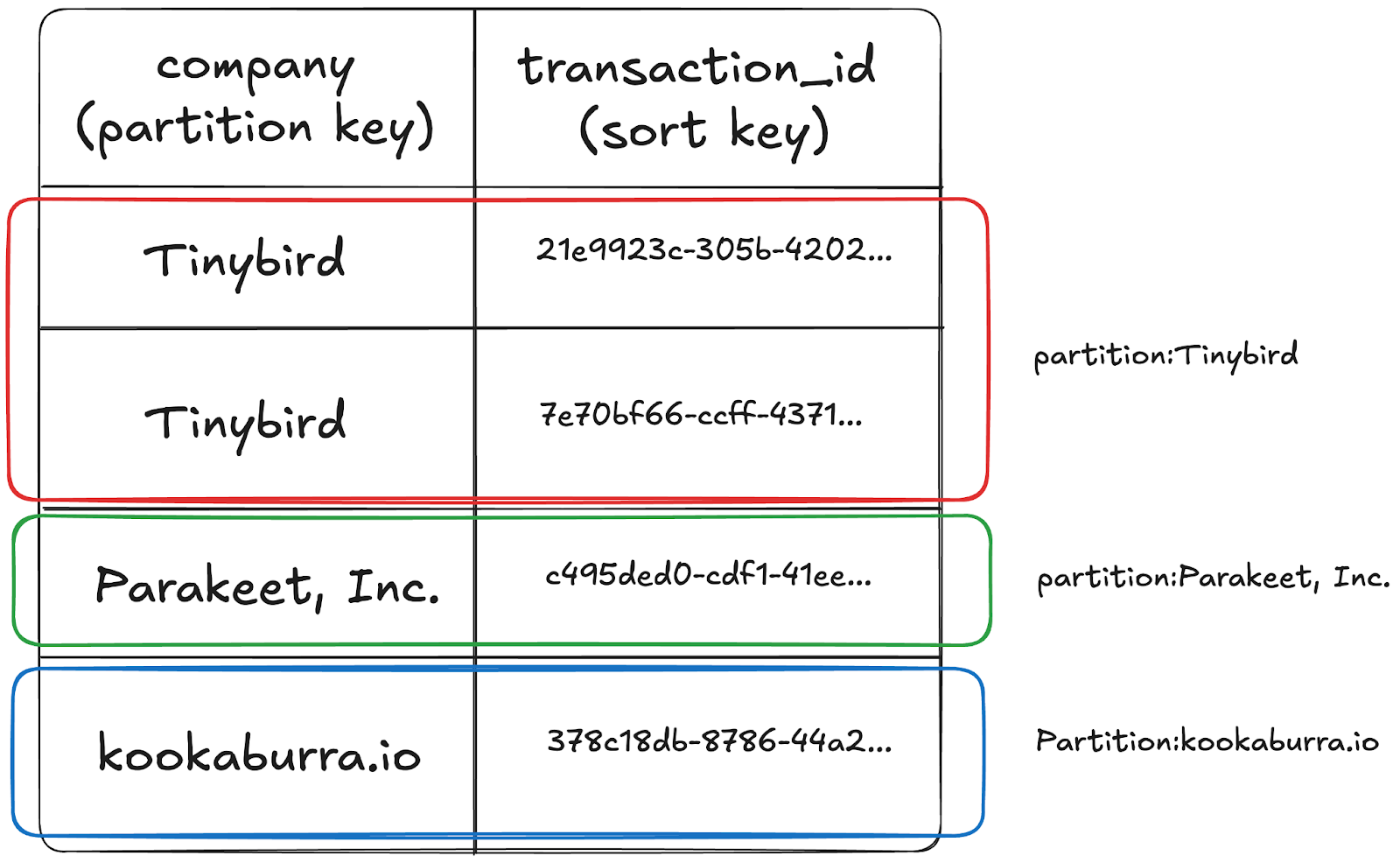
Let’s look at some dummy data for our corporate travel app. The partition key (customer) is the enterprise that made the booking, while the sort key (transaction_id) is a ULID that is unique to the transaction. ULIDs are attractive as sort keys since they provide both uniqueness and time-based sortability.
For performance, all we need to think about is the partition key and sort key. They are used by DynamoDB to physically store our data in an optimal way. Data will be separated by the partition key value into partitions, and then sorted within the partition by the sort key.
DynamoDB achieves its consistent, predictable performance by scaling horizontally using these partitions. New partitions are created automatically as records are inserted with distinct partition key values.
Importantly, requests for records are immediately routed to the correct partition. This is why you are almost always required to use the primary key when querying data. Without it, DynamoDB couldn't short-circuit requests to the correct partition, which would degrade performance.
These two design considerations impose some limitations and can make it difficult to change access patterns in the future. But, assuming your use case fits within these bounds, DynamoDB can be hard to beat as a near-infinitely scalable transactional database.
In the case of our travel booking app, we can fit perfectly into this model. To see the latest 10 transactions for a particular company, we can use the Query operation with the primary key (company) and a limit of 10, to read a contiguous block of records from the partition (our sort-key is a ULID, which has a time component, meaning the data is effectively ordered by time within the partition). To read specific bookings, we can use GetItem with company and transaction_id to retrieve a single record.
How Tinybird solves for our analytical workloads
DynamoDB’s storage optimizations make these CRUDL style operations super fast, and we can take advantage of secondary indexes if we want to access records by different attributes. But what if we want to do some big aggregations across many records?
Aggregations aren’t a function that DynamoDB was built to handle, as it has no aggregation functionality out of the box. This is where Tinybird complements DynamoDB to round out our architecture.
Tinybird is fundamentally an analytical database, built to handle analytics in a similar context to DynamoDB: applications with many users running concurrent queries, very high data throughput, and very low latency demands.
In DynamoDB parlance, we can think of Tinybird as a secondary index for analytics. However, unlike a secondary index, the queries run in Tinybird do not create load in DynamoDB. Tinybird connects to DynamoDB and creates a stateful, synchronized replica of data inside Tinybird. I’ll explain exactly how that ingestion piece works later.
Similar to DynamoDB, Tinybird also uses partition keys and sorting keys. However, unlike DynamoDB’s semi-structured key-value data model, Tinybird stores data in a well-structured, columnar model.
Let’s first take a look at the columnar storage model. A record has a set of attributes or fields, and in a transactional database, we store the whole record together, making it super easy to find and read an individual record. However, for analytical purposes, we rarely want to look at whole records, and even less at only a single record at a time. Typically, we want to know aggregated information about specific attributes of many records. With columnar storage, records are split up into their attributes, so that attribute values are stored together. This means we can very efficiently scan all values of one column, without reading any unneeded attributes.
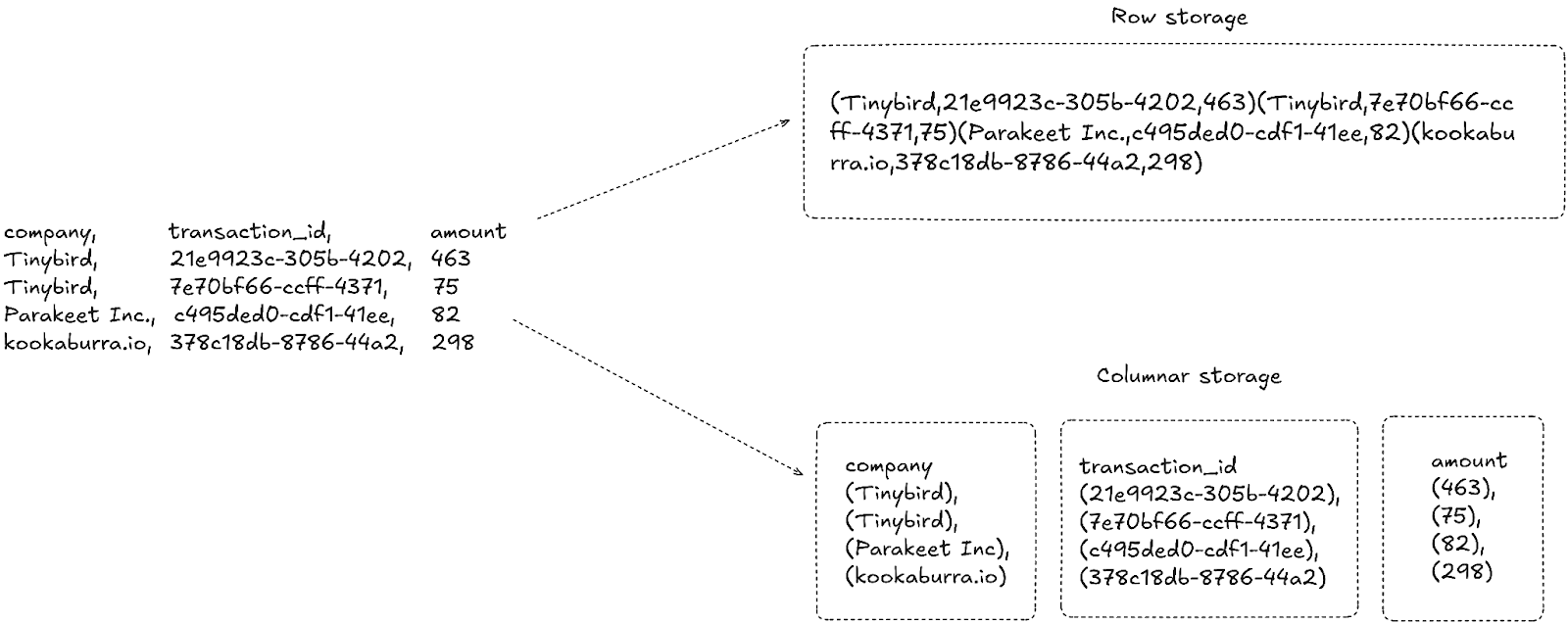
In our travel booking example, we want to be able to aggregate the sum of travel costs. In this case, we only really care about using the amount column, not the entire record. Tinybird stores all of the amount values together sequentially, meaning a query like sum(amount) can avoid reading any data other than the amount values.

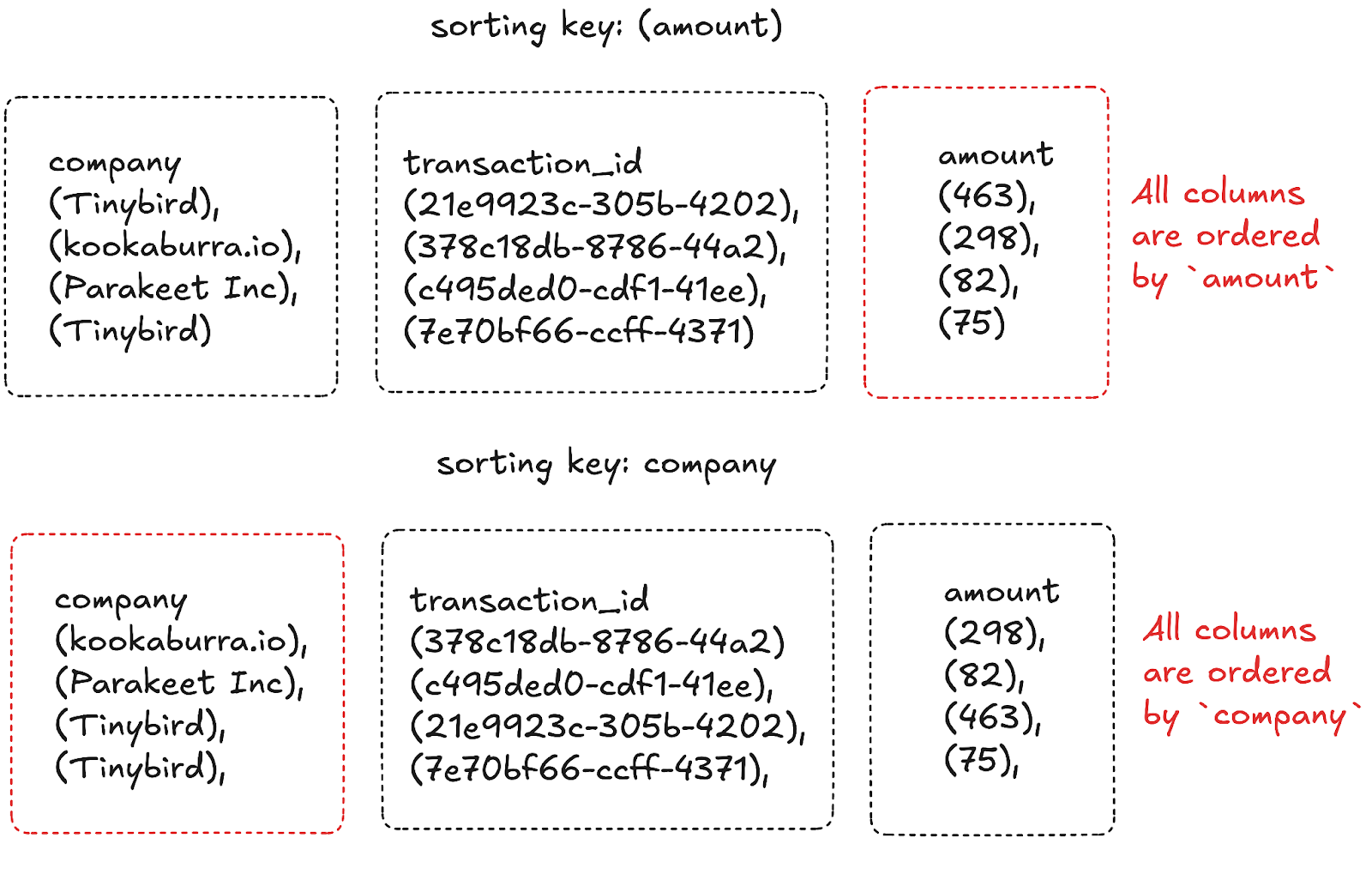
Beyond column-oriented storage, Tinybird also has the concept of partition and sorting keys, and they behave very similarly to DynamoDB. A partition key defines the physical separation of data into partitions to keep related data close together. Sorting keys define how data is sorted within those partitions. These keys further enhance the efficiency of scans by allowing the database to skip even more data during reads. There are two somewhat subtle but important differences between how these keys function in Tinybird versus DynamoDB:
- In DynamoDB, a partition key is absolutely necessary, while a sorting key is optional, and the partition key typically has the biggest impact on performance. In Tinybird, the sorting key is almost always the most important factor for performance, and the partition key is generally only of particular concern at extreme scale.
- In Tinybird, there is no strict requirement to use either the partition key or sorting key in queries, but it is heavily encouraged for efficient data skipping.
In our travel booking example, we probably don’t want to simply sum(amount) across all companies. More likely, we’ll want to sum(amount) WHERE company = ‘Tinybird’ based on who the user is. If we used a sorting key of amount, scanning the amount column would be super inefficient because we don’t know what values we can skip. However, if we use a sorting key of company then our index knows that values between position X and Y satisfy the where company =’Tinybird’ condition, so we can skip straight to position X, scan all the way through to position Y, then stop.
DynamoDB trades analytical capability for peak transactional performance, and Tinybird does the exact inverse, sacrificing transactional capabilities for optimized analytical performance. For example, using columnar storage makes single-row access significantly less performant as each column value must be sought on disk separately, and then recombined to create the full row.
In this architecture, we’re combining two technologies with clearly separated duties to get the absolute best of both worlds in terms of cost and performance.
How Tinybird syncs DynamoDB
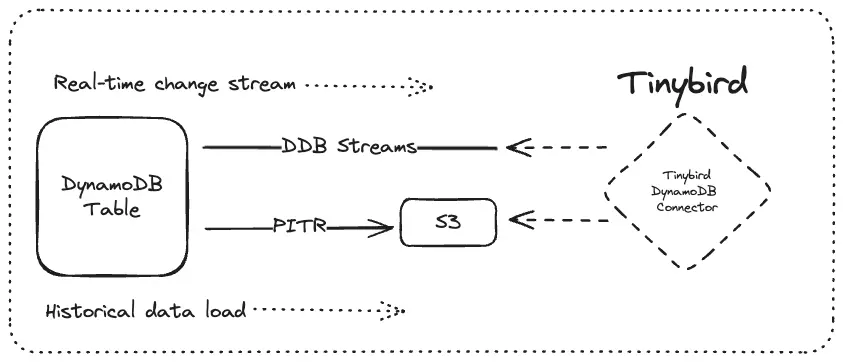
Tinybird has a native connector for DynamoDB, which lets us sync DynamoDB tables without the need for external ETL tooling and keep our architecture minimal.
The native connector uses two features of DynamoDB: DynamoDB Streams and PITR (point in time recovery). The DynamoDB Streams API provides access to a continuous change stream capturing every change to a DynamoDB table. PITR is a way to export an entire DynamoDB table to files in S3.
When Tinybird connects to a DynamoDB table, it begins by triggering a PITR export. This export creates a dump of the DynamoDB table’s current state as a set of files in S3. Tinybird then ingests these files in bulk to seed the initial state of the table with existing data.
Once the historical data is loaded, Tinybird subscribes to the DynamoDB Streams change stream. Tinybird consumes all produced change events, inserting them into a raw append log of change operations. To handle updates, Tinybird takes the partition and sort key fields from the DynamoDB records and collapses existing records down to the latest. For deletes, records are marked with a tombstone and evicted. These operations happen automatically without user interaction, meaning that the resulting Tinybird table can be queried as a stateful copy of the source DynamoDB table with only a few seconds of lag.
The full architecture
By complementing DynamoDB with Tinybird, we can solve both sets of user demands, supporting our future scale expectations, while minimizing the overall architectural complexity. We’re using two databases that are specialized for their respective jobs that, while different, share many of the same characteristics that make it easier to adapt our existing knowledge without learning a totally new paradigm.
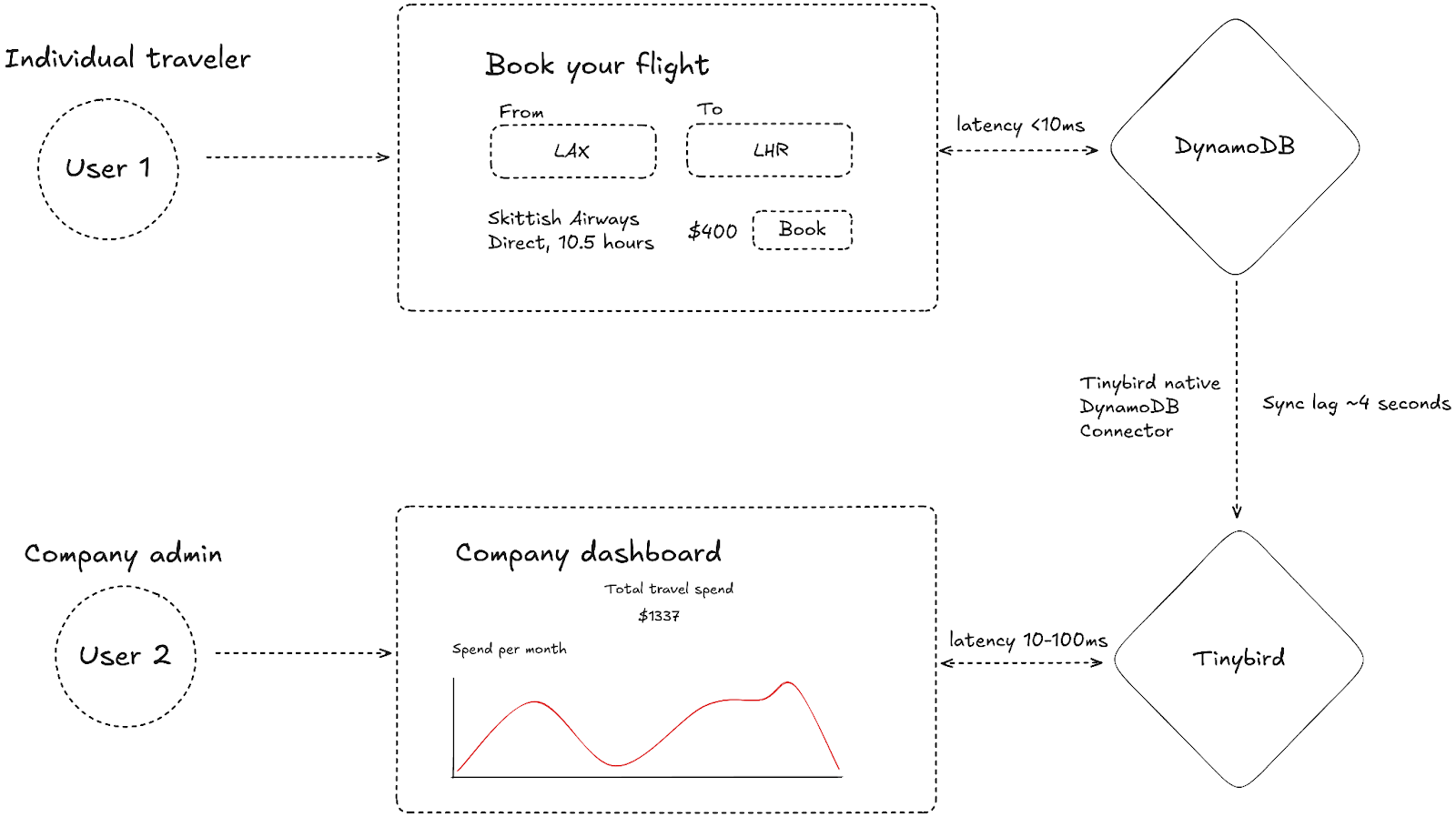
Diverse user requirements have a habit of creating messy architecture, which leads to sprawling infrastructure and brittle integrations. This makes it harder to build, slower to ship, and changes feel like wading through a goopy mess.
Choosing the right tools for the job helps to keep architectures simple, and keep you moving fast.
As we like to say:
Speed Wins.











