Very few people enjoy trying a new database. Maybe you like tinkering with new tech for your hobby projects, but when selecting a database for a production application, you don't want to dig deep into the internals of some niche open-source DBMS with 37 GitHub stars. You just want something that works.
Most developers, given the option, will choose Postgres, MySQL, or MongoDB as their next database regardless of the use case. These databases are familiar, well-supported, and can solve a decently wide range of database problems.
But when it comes to real-time analytics, these databases usually won't work. They're not built for real-time data ingestion, analytical workloads, big aggregates, complex joins, and/or column-based filtering even at a relatively modest scale.
There are three databases that I think are best for real-time analytics, and those are ClickHouse, Apache Druid, and Apache Pinot.
I'll explain why they're great databases for real-time analytics, and how you can approach deployment and maintenance to simplify development over these highly specialized pieces of tech.
What is real-time analytics?
We can't talk about databases for a use case without understanding the use case for the database.
I've already written a good definitive guide to real-time analytics. If you have the time, I recommend you read it. If you need the TL;DR, here it is:
Real-time analytics is the process of capturing real-time data, transforming it, and exposing the transformed result set to the end user in a matter of seconds or less.
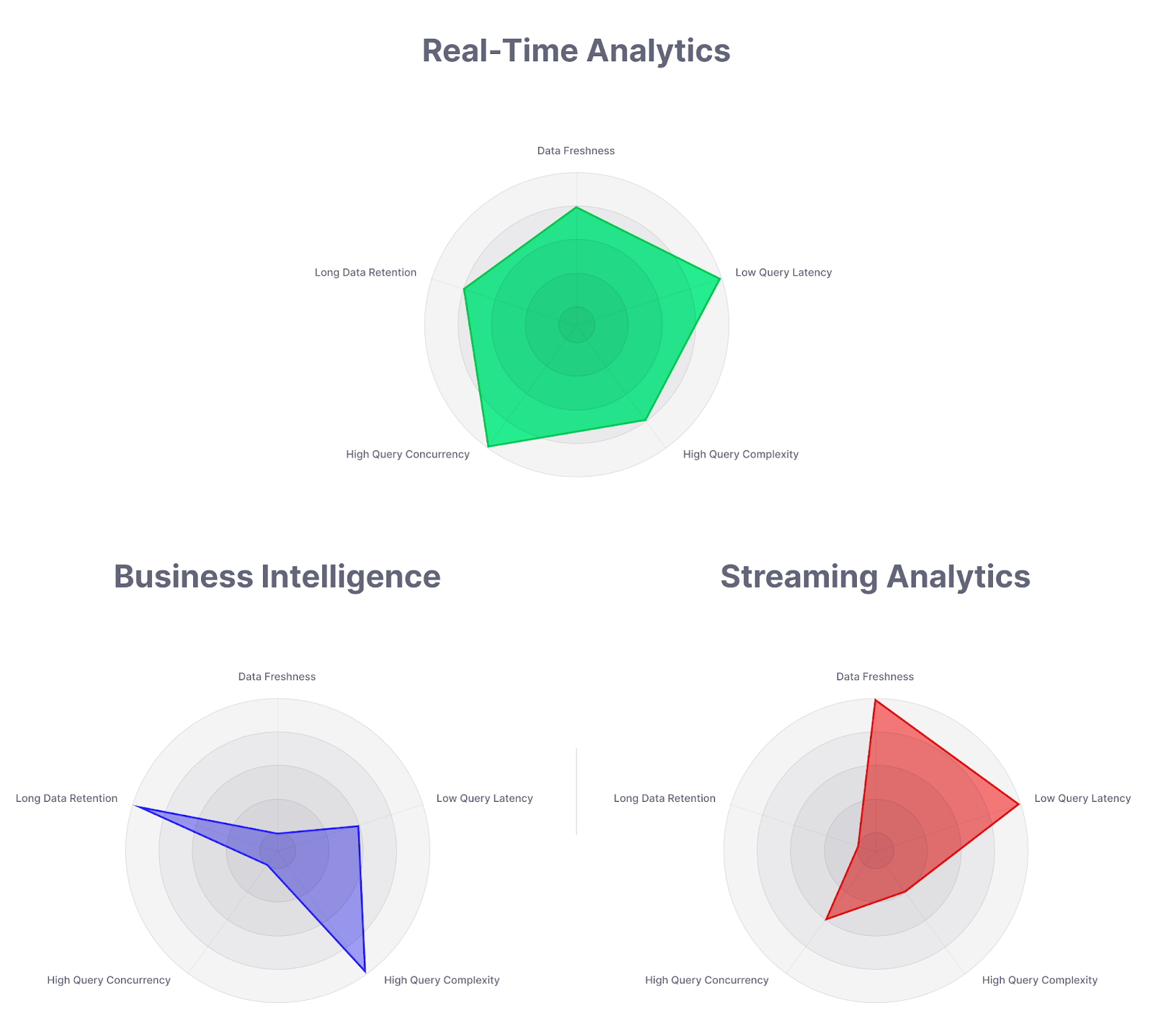
There are five core facets to real-time analytics, and a real-time analytics database must support all of them:
- High Data Freshness. Streaming data must be written and available for querying in seconds or less (without impacting read performance).
- Low Query Latency. Queries must return results in ~<100 milliseconds, aka "web time."
- High Query Complexity. We're talking about analytics, not transactions. That means filters, aggregates, and joins.
- High Query Concurrency. Real-time analytics databases often underpin user-facing apps. They must support thousands of concurrent, user-initiated queries without lagging.
- Long Data Retention. Real-time analytics diverges from stream processing or "streaming analytics" as it must perform complex queries over unbounded time windows. Real-time analytics systems must retain perhaps years' worth of data, with raw tables containing trillions of rows or more.
If you know databases, you know that Postgres, MySQL, and many other popular databases won't feasibly satisfy all these criteria. Few databases can.
What is a real-time database?
A real-time analytics database (aka a real-time database) is simply a database that can support the five facets of real-time analytics at scale:
- High Data Freshness
- Low Query Latency
- High Query Complexity
- High Query Concurrency
- Long Data Retention
Of course, there's nuance here. It's not just which database you choose, but how you deploy and scale that database. Theoretically, you could use Postgres or MongoDB as a real-time analytics database to a certain extent. You would just need to understand the limitations of their scale and feel comfortable handling complex database operations like sharding, read replicas, scaling, and cluster performance tuning.
But even engineers who can handle the complexities of scaling a database often don't want to. Traditional relational databases like Postgres or MySQL and document databases like MongoDB aren't natively built for real-time analytics. Rather than force them into a use case for which they aren't uniquely built, you should choose a purpose-built database ready to support real-time analytics out of the box.
Note: It's important to distinguish "real-time databases" from "analytics databases." They are not the same thing. Sure, there's some overlap in the Venn diagram, but they're not mutually inclusive terms.
What are some examples of analytics databases?
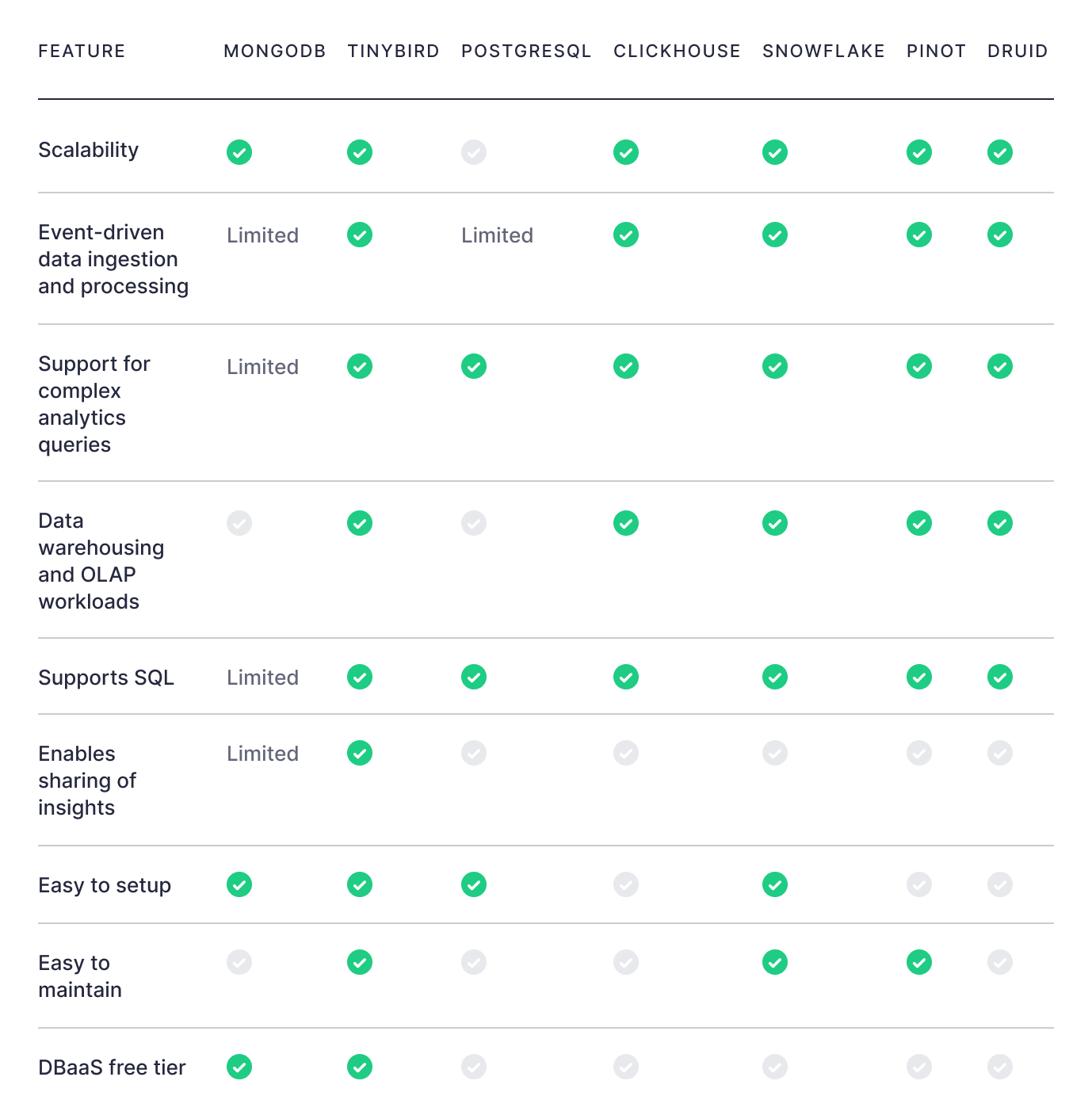
Some common databases used for analytics include MongoDB, Snowflake, Amazon Redshift, Google BigQuery, Databricks, ClickHouse, Apache Druid, Apache Pinot, Apache Cassandra, Apache HBase, ElasticSearch, and DynamoDB.
Some of these are also real-time databases. Most of them aren't. It's important to know the difference.
How are real-time databases different?
Real-time analytics databases are different from generic analytics databases in that they satisfy all of the requirements of real-time analytics, not just some.
Data warehouses, for example, are a class of analytics database that can handle high query complexity and long data retention, but not low query latency and high data freshness.
In-memory databases - like Redis, Memcached, or Dragonfly - will also struggle with real-time analytics use cases. They're fast for key-value lookup but don’t scale to support long-term data storage or complex analytics. While these databases can be used as a result cache on top of a data warehouse or data lake, that still requires an additional process to refresh the cache. By definition, that will impact data freshness.
Selection criteria for a real-time analytics database
When it comes to choosing a database for real-time analytics, these are the criteria that I feel are the most important to consider:
Ingestion Throughput
High write throughput is a hallmark of real-time analytics databases, and it is required to achieve the high data freshness characteristic of real-time analytics systems. Real-time analytics databases must scale write operations to support millions of events per second, whether from IoT sensors, user clickstreams, or any other streaming data system.
Databases that utilize specialized data structures like a log-structured merge-tree (LSMT), for example, work well in these scenarios, as this data structure is very efficient at write operations and can handle high-scale ingestion throughput.
Read Patterns
Most analytical queries are going to involve filtering and aggregating. A real-time analytics database must efficiently process queries involving filtered aggregates.
Columnar databases excel here. Since columnar databases use a column-oriented storage pattern - meaning data in columns is stored sequentially on disk - they're generally able to reduce scan size on analytical queries.
Analytical queries rarely need to use all of a table’s columns to answer a question, and since columnar databases store data in columns sequentially, they can read only the data needed to get the result.
Aggregating a column, for example, is one of the most common analytical patterns. With column values stored sequentially, the database can more efficiently scan the column, knowing that every value is relevant to the result.
Many analytical queries also often involve joining data sources. Classic examples include enriching streaming events with dimensional tables. While a full range of join support isn't strictly required for real-time analytics, you'll be limited without robust join support.
If your database lacks join support, you'll likely have to push that complexity to the "left" to denormalize and flatten the data before it hits the database, adding additional complexity and processing steps.
Query Performance
High-performance real-time analytics databases should return answers to complex queries in milliseconds. There's no hard and fast rule here, though many accept that user experience starts to degrade when applications take longer than 50-100 milliseconds to refresh on a user action.
Real-time analytics databases should be fast for analytical queries without excessive performance tweaking and include optimization mechanisms (such as incrementally updating Materialized Views) to improve performance on especially complex queries.
Once again, columnar databases excel here, because they generally must scan less data to return the result of an analytical query.
However, not all columnar storage is the same, and the specific DBMS might introduce delay to query responses. Snowflake, for example, uses columnar storage. But Snowflake seeks to distribute queries across compute, scaling horizontally to be able to handle a query of arbitrary complexity. This "result shuffling" tends to increase latency, as you'll have to bring all the distributed result sets back together to serve the query response. ClickHouse, on the other hand, seeks to stay as "vertical" as possible and attempts to minimize query distribution, which typically results in lower latency responses.
Concurrency
Real-time analytics is often (though not always) synonymous with "user-facing analytics." User-facing analytics differs from analytics for internal reporting in that queries to the database are driven not by internal reporting schedules, but by on-demand user requests. This means you won't have control over 1) how many users query your database, and 2) how often they query it.
Database queries in user-facing analytics are initiated by application users, which significantly limits your control over query concurrency.
A real-time analytics database needs to be able to support thousands of concurrent requests even on complex queries. Scaling to support this concurrency can be difficult regardless of your database.
"But I don't have thousands of concurrent users!" you might say. Not yet, at least. But a single user can make many queries at once, and part of choosing a database is considering future scale. Even modest levels of concurrency can be expensive on the wrong database. Plus, if your application succeeds and concurrency skyrockets, database migrations are the last thing you want to deal with.
Scalability
Every database, whether real-time or not, must be able to scale. Real-time analytics databases need to scale as each of the above factors remains. A real-time analytics database allows you to scale horizontally, vertically, or both to maintain high data freshness, low latency on queries, high query complexity, and high query concurrency.
Ease of Use and Interoperability
The more specialized the use case, the more specialized the requirements. But a highly-specialized database isn't always the right choice, if for no other reason than they can be very hard to deploy, they can lack a supportive community, and they may suffer from a bare bones (or non-existent) data integration ecosystem.
Even simple things like a lack of support for SQL, the world's most popular and well-understood query language, can slow you down significantly.
Don't choose a database just because it's fast. Choose a database that makes you fast. It's no use having fast queries if your development speed slows to a crawl.
What is the best database for real-time analytics?
As I mentioned up top, I think that the three best databases for real-time analytics are:
All these databases are open-source, column-oriented, distributed, OLAP databases uniquely suited for real-time analytics. Your choice will depend on your use case, comfort level, and specific feature requirements. From a pure performance perspective, most won't notice a major difference between these three for most use cases (despite what various synthetic, vendor-centric benchmarks might suggest).
That said, each of these databases is relatively complex to deploy. They're niche databases, with much smaller communities than traditional OLTP databases and many more quirks that take time to understand.
The best databases for real-time analytics have smaller communities and less support than traditional databases, so they can be harder to manage and deploy.
Because of this, many developers may choose to use managed versions of these databases. A managed database can abstract some of the complexity of the database and cluster management.
Tinybird is a great example of a managed real-time data platform that can simplify the deployment and maintenance of a real-time database.
Why choose Tinybird as a real-time analytics database
Tinybird is not a real-time analytics database, per se. Rather, it's a fully integrated real-time data platform built on open-source ClickHouse. Tinybird bundles the ingestion, querying, and publication layers of a data platform into a single managed service. It not only abstracts the complexities of the database itself; it gives you a fully integrated, end-to-end system to build real-time analytics products.
If you're looking for a real-time analytics database, here's why you might consider Tinybird:
- It's insanely fast. Tinybird is built on open-source ClickHouse, meaning you get all that raw performance out of the box. Tinybird can routinely run complex analytical queries over billions or trillions of rows of data in milliseconds.
- It's easy to use. Unlike open-source ClickHouse, Tinybird is exceptionally easy to work with. It's a serverless real-time data platform implementation that presents as a SaaS. You can sign up and create an end-to-end real-time data pipeline from ingestion to API in 3 minutes. That ease of use means you can be much more productive with little effort. You won't ever need to fuss with the complexities of setting up, maintaining, and scaling a database cluster.
- Connecting your data is easy. On top of the database, Tinybird offers a host of fully managed connectors to ingest data from many sources such as Apache Kafka, Confluent Cloud, Google BigQuery, Snowflake, Amazon S3, and more. It even has an HTTP streaming endpoint to write thousands of events per second to the database directly from your application code. With these integrated connectors, you'll save time and money by avoiding developing and hosting external ingestion services.
- Tinybird works with version control. Tinybird integrates directly with git-based source control systems. This simplifies complexities like schema migrations by allowing you to lean on tried and true software engineering principles to branch, test, and deploy updates in real time.
- Fully-managed publication layer. Many real-time analytics use cases are going to be user-facing. This means embedded analytics in software, products, and services accessed by users. Tinybird makes this extraordinarily easy through a fully managed API publication layer. Any SQL query in Tinybird can be published instantly as a fully documented, scalable HTTP Endpoint without writing additional code. Tinybird hosts and scales your API so you don't have to. For user-facing analytics applications, you can't beat that.
There are many factors to consider when choosing a database for real-time analytics. ClickHouse, Apache Druid, and Apache Pinot are great open-source options when you want complete control over the database implementation and can spend time maintaining and scaling the database cluster.
But development speed is just as important as query speed, so you might go for something like Tinybird. You'll get all the underlying performance without the added effort.
Whether you choose Tinybird as a real-time analytics database or something else, keep the five facets of real-time analytics in mind, and choose a database that best supports your use case, pricing requirements, and development style.
Good luck!










