Tinybird Forward is live! See the Tinybird Forward docs to learn more. To migrate, see Migrate from Classic.
DynamoDB Connector¶
Use the DynamoDB Connector to ingest historical and change stream data from Amazon DynamoDB to Tinybird.
The DynamoDB Connector is fully managed and requires no additional tooling. Connect Tinybird to DynamoDB, select your tables, and Tinybird keeps in sync with DynamoDB.
With the DynamoDB Connector you can:
- Connect to your DynamoDB tables and start ingesting data in minutes.
- Query your DynamoDB data using SQL and enrich it with dimensions from your streaming data, warehouse, or files.
- Use Auth tokens to control access to API endpoints. Implement access policies as you need. Support for row-level security.
DynamoDB Connector only works with Workspaces created in AWS Regions.
Prerequisites¶
- Tinybird CLI version 5.3.0 or higher. See the Tinybird CLI quick start.
- Tinybird CLI authenticated with the desired Workspace.
- DynamoDB Streams is active on the target DynamoDB tables with
NEW_IMAGEorNEW_AND_OLD_IMAGEtype. - Point-in-time recovery (PITR) is active on the target DynamoDB table.
You can switch the Tinybird CLI to the correct Workspace using tb workspace use <workspace_name>.
Supported characters for column names are letters, numbers, underscores, and dashes. Tinybird automatically sanitizes invalid characters like dots or dollar signs.
Required permissions¶
The DynamoDB Connector requires certain permissions to access your tables. The IAM Role needs the following permissions:
dynamodb:Scandynamodb:DescribeStreamdynamodb:DescribeExportdynamodb:GetRecordsdynamodb:GetShardIteratordynamodb:DescribeTabledynamodb:DescribeContinuousBackupsdynamodb:ExportTableToPointInTimedynamodb:UpdateTabledynamodb:UpdateContinuousBackups
The following is an example of AWS Access Policy:
When configuring the connector, the UI, CLI and API all provide the necessary policy templates.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"dynamodb:Scan",
"dynamodb:DescribeStream",
"dynamodb:DescribeExport",
"dynamodb:GetRecords",
"dynamodb:GetShardIterator",
"dynamodb:DescribeTable",
"dynamodb:DescribeContinuousBackups",
"dynamodb:ExportTableToPointInTime",
"dynamodb:UpdateTable",
"dynamodb:UpdateContinuousBackups"
],
"Resource": [
"arn:aws:dynamodb:*:*:table/<your_dynamodb_table>",
"arn:aws:dynamodb:*:*:table/<your_dynamodb_table>/stream/*",
"arn:aws:dynamodb:*:*:table/<your_dynamodb_table>/export/*"
]
},
{
"Effect": "Allow",
"Action": ["s3:PutObject", "s3:GetObject", "s3:ListBucket"],
"Resource": [
"arn:aws:s3:::<your_dynamodb_export_bucket>",
"arn:aws:s3:::<your_dynamodb_export_bucket>/*"
]
}
]
}
The following is an example trust policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Principal": {
"AWS": "arn:aws:iam::473819111111111:root"
},
"Condition": {
"StringEquals": {
"sts:ExternalId": "ab3caaaa-01aa-4b95-bad3-fff9b2ac789f8a9"
}
}
}
]
}
Load a table using the CLI¶
To load a DynamoDB table into Tinybird using the CLI, create a connection and then a Data Source.
The connection grants your Tinybird Workspace the necessary permissions to access AWS and your tables in DynamoDB. The Data Source then maps a table in DynamoDB to a table in Tinybird and manages the historical and continous sync.
Create the DynamoDB connection¶
The connection grants your Tinybird Workspace the necessary permissions to access AWS and your tables in DynamoDB.
To connect, run the following command:
tb connection create dynamodb
This command initiates the process of creating a connection. When prompted, type y to proceed.
Create a new IAM Policy in AWS¶
The Tinybird CLI provides a policy template.
- Replace
<your_dynamodb_table>with the name of your DynamoDB table.ç - Replace
<your_dynamodb_export_bucket>with the name of the S3 bucket you want to use for the initial load. - In AWS, go to IAM, Policies, Create Policy.
- Select the JSON tab and paste the modified policy text.
- Save and create the policy.
Create a new IAM Role in AWS¶
- Return to the Tinybird CLI to get a trust policy template.
- In AWS, go to IAM, Roles, Create Role.
- Select Custom Trust Policy and paste the trust policy copied from the CLI.
- In the Permissions tab, attach the policy created in the previous step.
- Complete the role creation process.
Complete the connection¶
In the AWS IAM console, find the role you've created. Copy its Amazon Resource Name (ARN), which looks like arn:aws:iam::111111111111:role/my-awesome-role.
Provide the following information to Tinybird CLI:
- The Role ARN
- AWS region of your DynamoDB tables
- Connection name
Tinybird uses the connection name to identify the connection. The name can only contain AlphaNumeric characters a-zA-Z and underscores _, and must start with a letter.
When the CLI prompts are completed, Tinybird creates the connection.
The CLI will generate a .connection file in your project directory. This file isn't used and is safe to delete. A future release will allow you to push this file to Tinybird to automate the creation of connections, similar to Kafka connections.
Create a DynamoDB Data Source file¶
The Data Source maps a table in DynamoDB to a table in Tinybird and manages the historical and continous sync. Data Source files contain the table schema, and specific DynamoDB properties to target the table that Tinybird imports.
Create a Data Source file called mytable.datasource. There are two approaches to defining the schema for a DynamoDB Data Source:
- Define the Partition Key and Sort Key from your DynamoDB table, and access other properties from JSON at query time.
- Define all DynamoDB item properties as columns.
The Partition Key and Sort Key, if any, from your DynamoDB must be defined in the Data Source schema. These are the only properties that are mandatory to define, as they're used for deduplication of records (upserts and deletes).
Approach 1: Define only the Partition Key and Sort Key¶
If you don't want to map all properties from your DynamoDB table, you can define only the Partition Key and Sort Keys.
The entire DynamoDB item is as JSON in a _record column, and you can extract properties using JSONExtract* functions.
For example, if you have a DynamoDB table with transaction_id as the Partition Key, you can define your Data Source schema like this:
mytable.datasource
SCHEMA >
transaction_id String `json:$.transaction_id`
IMPORT_SERVICE "dynamodb"
IMPORT_CONNECTION_NAME <your_connection_name>
IMPORT_TABLE_ARN <your_table_arn>
IMPORT_EXPORT_BUCKET <your_dynamodb_export_bucket>
Replace the<your_connection_name> with the name of the connection created in the first step. Replace <your_table_arn> with the ARN of the table you'd like to import. Replace <your_dynamodb_export_bucket> with the name of the S3 bucket you want to use for the initial sync.
Approach 2: Define all DynamoDB item properties as columns¶
If you want to strictly define all your properties and their types, you can map them into your Data Source as columns.
You can map properties to any of the supported types in Tinybird. Properties can be also arrays of the previously mentioned types, and nullable. Use the nullable type when there are properties that might not have a value in every item within your DynamoDB table.
For example, if you have a DynamoDB with items like this:
{
"timestamp": "2024-07-25T10:46:37.380Z",
"transaction_id": "399361d5-10fc-4777-8187-88aaa4623569",
"name": "Chris Donnelly",
"passport_number": 4904040,
"flight_from": "Burien",
"flight_to": "Sanford",
"airline": "BrianAir"
}
Where transaction_id is the partition key, you can define your Data Source schema like this:
mytable.datasource
SCHEMA >
`timestamp` DateTime64(3) `json:$.timestamp`,
`transaction_id` String `json:$.transaction_id`,
`name` String `json:$.name`,
`passport_number` Int64 `json:$.passport_number`,
`flight_from` String `json:$.flight_from`,
`flight_to` String `json:$.flight_to`,
`airline` String `json:$.airline`
IMPORT_SERVICE "dynamodb"
IMPORT_CONNECTION_NAME <your_connection_name>
IMPORT_TABLE_ARN <your_table_arn>
IMPORT_EXPORT_BUCKET <your_dynamodb_export_bucket>
Replace <your_connection_name> with the name of the connection created in the first step. Replace <your_table_arn> with the ARN of the table you'd like to import. Replace <your_dynamodb_export_bucket> with the name of the S3 bucket you want to use for the initial sync.
You can map properties with basic types (String, Number, Bool, Binary, String Set, Number Set) at the root item level. Follow this schema definition pattern:
<PropertyName> <PropertyType> `json:$.<PropertyNameInDDB>`
PropertyNameis the name of the column within your Tinybird Data Source.PropertyTypeis the type of the column within your Tinybird Data Source. It must match the type in the DynamoDB Data Source:- Strings correspond to
Stringcolumns. - All
Int,UInt, orFloatvariants correspond toNumbercolumns. Array(String)corresponds toString Setcolumns.Array(UInt<X>)and all numeric variants correspond toNumber Setcolumns.
- Strings correspond to
PropertyNameInDDBis the name of the property in your DynamoDB table. It must match the letter casing.
Map properties within complex types, like Maps, using JSONPaths. For example, you can map a property at the first level in your Data Source schema like:
MyString String `json:$.<map_property_name>.<map_property_value_name>`.
For Lists, standalone column mapping isn't supported. Those properties require extraction using JSONExtract* functions or consumed after a transformation with a Materialized View.
Push the Data Source¶
With your connection created and Data Source defined, push your Data Source to Tinybird using tb push.
For example, if your Data Source file is mytable.datasource, run:
tb push mytable.datasource
Due to how Point-in-time recovery works, data might take some minutes before it appears in Tinybird. This delay only happens the first time Tinybird retrieves the table.
Load a table using the UI¶
To load a DynamoDB table into Tinybird using the UI, select the DynamoDB option in the Data Source dialog. You need an existing connection to your DynamoDB table.
The UI guides you through the process of creating a connection and finally creating a Data Source that imports the data from your DynamoDB table.
Create a DynamoDB connection¶
When you create a connection, provide the following information:
- AWS region of your DynamoDB tables
- ARN of the table you want to import
- Name of the S3 bucket you want to use for the initial sync.
In the next step, provide the ARN of the IAM Role you created in AWS. This role must have the necessary permissions to access your DynamoDB tables and S3 bucket.
Create a Data Source¶
After you've created the connection, a preview of the imported data appears. You can change the schema columns, the sorting key, or the TTL.
Due to the schemaless nature of DynamoDB, the preview might not show all the columns in your table. You can manually add columns to the schema in the Code Editor tab.
When you're ready, select Create Data Source.
Due to how Point-in-time recovery works, data might take some minutes before it appears in Tinybird. This delay only happens the first time Tinybird retrieves the table.
Columns added by Tinybird¶
When loading a DynamoDB table, Tinybird automatically adds the following columns:
| Column | Type | Description |
|---|---|---|
_record | Nullable(String) | Contents of the event, in JSON format. Added to NEW_IMAGES and NEW_AND_OLD_IMAGES streams. |
_old_record | Nullable(String) | Stores the previous state of the record. Added to NEW_AND_OLD_IMAGES streams. |
_timestamp | DateTime64(3) | Date and time of the event. |
_event_type | LowCardinality(String) | Type of the event. |
_is_deleted | UInt8 | Whether the record has been deleted. |
If an existing table with stream type NEW_AND_OLD_IMAGES is missing the _old_record column, add it manually with the following configuration: _old_record Nullable(String) json:$.OldImage.
Iterate a Data Source¶
To iterate a DynamoDB Data Source, use the Tinybird CLI and the version control integration to handle your resources.
You can only create connections in the main Workspace. When creating the connection in a Branch, it's created in the main Workspace and from there is available to every Branch.
DynamoDB Data Sources created in a Branch aren't connected to your source. AWS DynamoDB documentation discourages reading the same Stream from various processes, because it can result in throttling. This can affect the ingestion in the main Branch.
Browse the use case examples repository to find basic instructions and examples to handle DynamoDB Data Sources iteration using git integration.
Add a new DynamoDB Data Source¶
You can add a new Data Source directly with the Tinybird CLI. See load of a DynamoDB table.
To add a new Data Source using the recommended version control workflow, see the examples repository.
When you add a Data Source to a Tinybird Branch, it doesn't have any connection details. You must add the Connection and DynamoDB configuration in the .datasource Datafile when moving to a production environment or Branch.
Update a Data Source¶
You can modify DynamoDB Data Sources using Tinybird CLI. For example:
tb auth
# modify the .datasource Datafile with your editor
tb push --force {datafile}
# check the command output for errors
When updating an existent DynamoDB Data Source, the first sync isn't repeated, only the new item modifications are synchronized by the CDC process.
To update a Data Source using the recommended version control workflow, see the examples repository.
In Branches, work with fixtures, as they're be applied as part of the CI/CD, allowing the full process to be deterministic in every iteration and avoiding quota usage from external services.
Delete a Data Source¶
You can delete DynamoDB Data Sources like any other Data Source.
To delete it using the recommended version control workflow, see the examples repository.
DynamoDB logs¶
You can find DynamoDB logs in the datasources_ops_log Service Data Source. Filter by datasource_id to select the correct Data Source. Use event_type to select between initial synchronization logs (sync-dynamodb), or update logs (append-dynamodb).
To select all DynamoDB related logs in the last day, run the following query:
SELECT * FROM tinybird.datasources_ops_log WHERE datasource_id = 't_1234' AND event_type in ['sync-dynamodb', 'append-dynamodb'] AND timestamp > now() - INTERVAL 1 day ORDER BY timestamp DESC
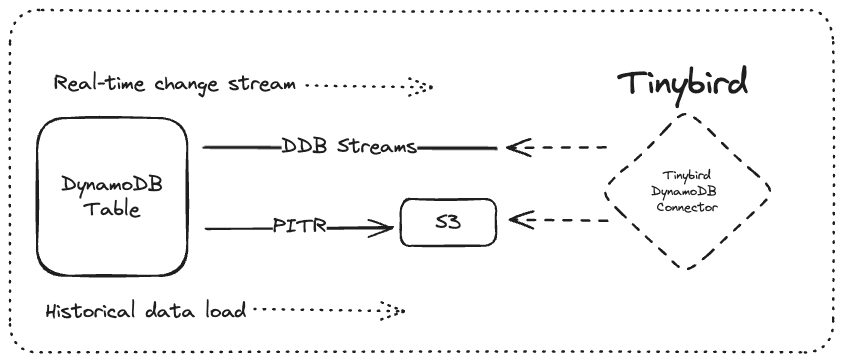
Connector architecture¶
AWS provides two free, default functions for DynamoDB:
- DynamoDB Streams captures change events for a given DynamoDB table and provides an API to access events as a stream. This allows CDC-like access to the table for continuous updates.
- You can use Point-in-time recovery (PITR) to take snapshots of your DynamoDB table and save the export to S3. This allows historical access to table data for batch uploads.
The DynamoDB Connector uses the following functions to send DynamoDB data to Tinybird:
Schema evolution¶
The DynamoDB Connector supports backwards compatible changes made in the source table. This means that, if you add a new column in DynamoDB, the next sync job automatically adds it to the Tinybird Data Source.
Non-backwards compatible changes, such as dropping or renaming columns, aren't supported by default and might cause the next sync to fail.
Considerations on queries¶
The DynamoDB Connector uses the ReplacingMergeTree engine to remove duplicate entries with the same sorting key. Deduplication occurs during a merge, which happens at an unknown time in the background. Doing SELECT * FROM ddb_ds might yield duplicated rows after an insertion.
To account for this, force the merge at query time by adding FINAL to the query. For example, SELECT * FROM ddb_ds FINAL. Adding FINAL also filters out the rows where _is_deleted = 1.
Override sort and partition keys¶
The DynamoDB Connector automatically sets values for the Sorting Key and the Partition Key properties based on the source DynamoDB table. You might want to override the default values to fit your needs.
To override Sorting and Partition key values, open your .datasource file and edit the values for ENGINE_PARTITION_KEY and ENGINE_SORTING_KEY. For the Sorting key, you must append the additional columns and leave pk and sk in place.
For example:
ENGINE "ReplacingMergeTree" ENGINE_PARTITION_KEY "toYYYYMM(toDateTime64(_timestamp, 3))" ENGINE_SORTING_KEY "pk, sk, <additional_column>" ENGINE_VER "_timestamp"
Sorting key is used for deduplication of data. When adding columns to ENGINE_SORTING_KEY, make sure they contain the same value across record changes.
You can then push the new .datasource configuration using tb push:
tb push updated-ddb.datasource
Don't edit the values for ENGINE or ENGINE_VER. The DynamoDB Connector requires the ReplacingMergeTree engine and a version based on the timestamp.