Developer experience has been the heart and soul of everything we’ve built at Tinybird.
From the very first commits and customers, our vision was laser-focused:
Developers should be able to create a real-time data pipeline, from streaming ingestion to fast APIs, in a flash.
No hassle, no confusing configurations or complex programming frameworks, no clunky flows or interfaces from the 90s.
The product we have built so far is a huge step toward that vision. And the love, support, and growth we’ve experienced have resoundingly affirmed that developers won’t sacrifice usability, activation, and enjoyment in order to access speed, power, and scale.
With this affirmation driving us forward, we’ve continued to innovate at the convergence of real-time data and developer experience, solving other big pains that data and engineering teams deal with every day:
- Making it easy to connect data from Kafka with a couple of clicks,
- Defining your entire data pipeline in a simple file structure,
- Building your Data Projects in the world's most popular IDE,
- Seamlessly integrating with data warehouses like BigQuery and Snowflake,
...and a long etcetera.
At the end of last year, we sat down and again asked ourselves and our customers: “What is the biggest pain the data community is facing right now?”
The answer was clear from the moment we asked:
“I want to be able to iterate a data pipeline without it being a huge pain.”
Fear is the biggest source of wasted time in Engineering organizations. When fear is present, innovation withers and progress stalls. Developers fear making changes to their real-time data pipelines because it requires immense knowledge and hard work to alter complex pipelines without causing downtime, cost spikes, or, worse, bringing down production.
Here are a few things our customers told us they wanted to do, but were scared to try:
- “I want to try multiple sorting keys for my Data Sources to improve performance and reduce consumption, but I don’t want to clutter my Workspace or try to track all those changes.”
- “I need to push a new version of my Endpoints to my application, but I’m not sure how to make a seamless transition from Staging to Production.”
- “I need to change the schema of my landing Data Source, but I’m scared I’ll lose data, and I'm worried about managing all the downstream dependencies.”
- “I want to keep track of who changes what, and when. If somebody introduces a new Pipe or changes some SQL and it affects performance, I want to be able to revert it, but I don’t know how to do that without negatively affecting other collaborators.”
Do any of these resonate with you?
To be clear, Tinybird isn’t the only data company trying to solve these problems. Data branching has become a hot topic for almost any modern database, and we’re excited to see the industry at large asking the same questions and taking the same viewpoints as we are.
But our use cases and problems are somewhat unusual, in a couple ways:
- The volume and speed of the data we’re working with is immense and unparalleled. Our largest customers are building real-time data pipelines that ingest millions of events per second and provide millisecond-latency responses to thousands of concurrent API requests per second.
Tinybird co-founder Javi Santana has eloquently described it: building scalable systems with massive concurrency is very hard. Once they’re built, changing them is even harder, as you wrangle massive throughput and concurrency.
We can’t just give engineers the tools to build real-time data pipelines; we must empower them to iterate them at massive scale. - Tinybird is not just a database. Rather, it’s a real-time data platform, which means that we take care of all the dependencies for real-time data pipelines: from the Data Sources, to the Materialized Views, to the Endpoints, and even changes in Tokens, Sink/Source integrations, all of the other “glue” in between, and all the infrastructure underneath that makes our platform so performant from end to end.
We can’t just solve branching tables. We have to think about the entire workflow, from ingestion to endpoint. And that is very hard.
The starting point
Ever since we made it possible to manage Tinybird Data Projects as flat, plain-text files, we had ways to solve most of these use cases for our customers, small or large. But the process was complex at scale, and it required a ton of expertise to avoid risks.
This meant that when our customers wanted to use version control or CI/CD, we often had to very proactively guide them through the process to avoid the pitfalls and dangers of iterating their Data Projects.

We could do it, and we did so happily, but it placed a lot of strain on our Customer Success team. They’re the best in the business, and we wanted to make sure that they were in the best position to help our customers without burning out.
Of course, we could have built utilities to make it possible to quickly change a Data Source’s sorting key or column type and just deal with the technical debt and painful data migrations that would inevitably follow.
This would have been a quick win, and our Customer Success team would have loved us. For a short while. But we knew that A) this wouldn’t scale as our business grew, and B) the best way to help our Customer Success team was to help our customers help themselves.
Working with data projects is a workflow problem, not a series of technical “quick fixes”.
When dbt launched, they evangelized this idea: “The same techniques software engineering teams use to collaborate on and rapidly deploy quality products must apply to data analytics.” We want to achieve similar things that dbt has achieved, but for real-time data.
So, we put together a small team to start exploring, prototyping, building, scrapping, and trying again. I won’t lie, the beginnings were exceptionally frustrating. The problem seemed so immense, with so many dark corners. Each path forward seemed to have many downsides. We tried a lot of things in the first 6 months, and failed at many of them. But we eventually developed some very strong opinions about the way you should work with Data Projects.
An opportunity to be more opinionated
Tinybird is known for its intuitive and flexible way of working with Data Projects. Some teams prefer to work from the UI because it is fast, and you can watch the output instantly when you make a change. Other teams want to work in the CLI with Git. Some people want to work in an IDE, so we make that possible.
We wanted to keep this flexibility, because it helps developers and data engineers more quickly find their comfort zone when working with real-time data.
But we also saw an opportunity to make the workflow more opinionated for bigger and highly collaborative teams:
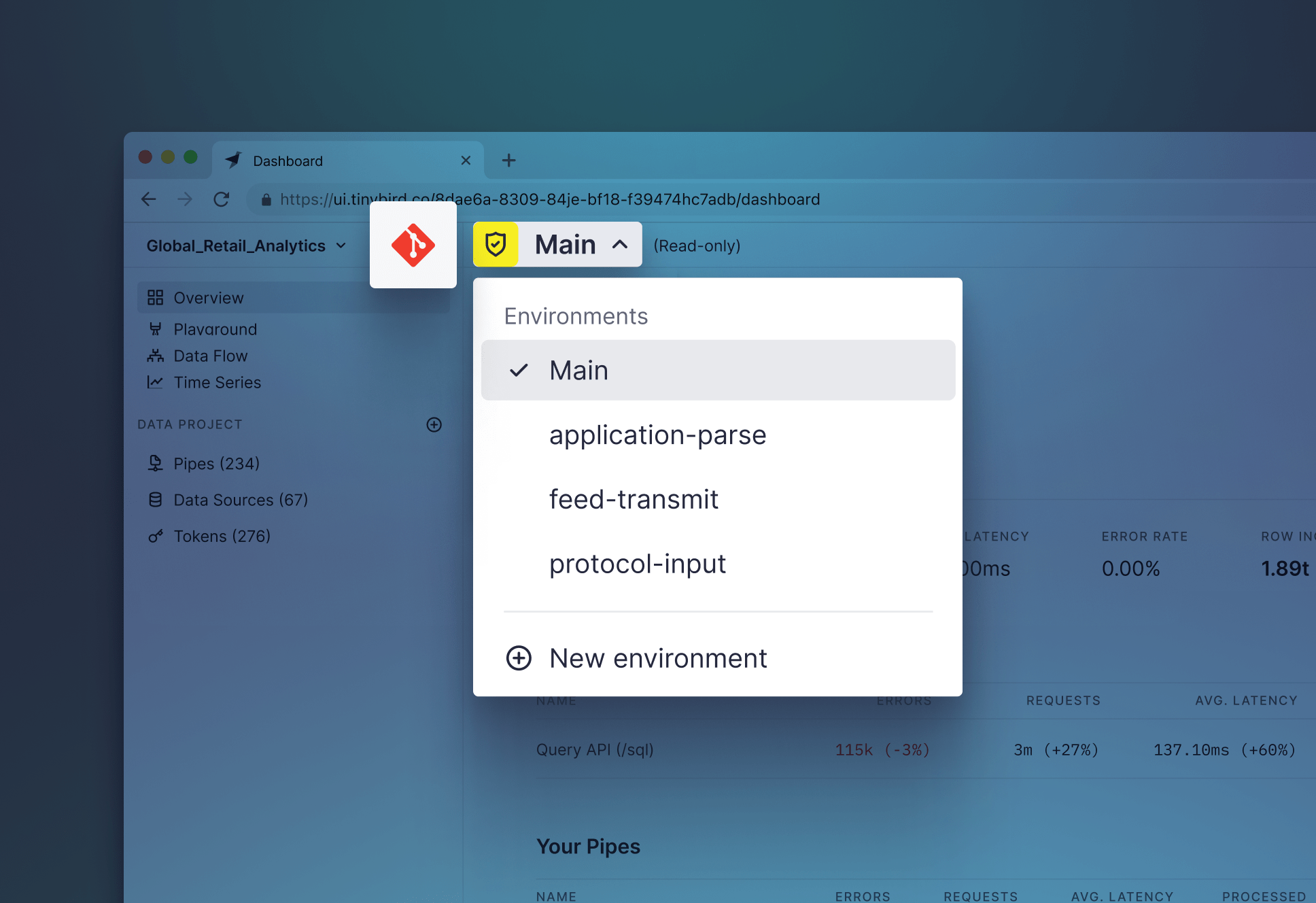
- There must be a clear source of truth. The main branch of the repository should be a reliable and consistent definition of what is in production.
- Every part of the project can be managed programmatically. The entire Data Project should be defined by its Datafiles. This makes it easier to integrate with source control and keep track of changes in your Data Projects.
The guiding principles
As we continued to iterate on our solution to this problem and bring these opinions into the product, we incrementally defined some core principles that have guided our work. Throughout the early stages of our process, each of these emerged as critical, and the product we’ve built reflects their predominance.
No magic
We could do many things in the background to automate simple tasks and hide complexity. For example, we could allow a hot change to a column type in a staging environment because it doesn't matter if something breaks when you just want to test quickly.
But once that change needed to go to production or the lineage became more complex, the process to merge those integrations would change entirely. The magic that our users felt in staging would be gone and replaced by frustration in production. So we agreed; no magic. Changes should be done transparently in safe spaces where people can learn how to test and iterate using the methods that will go to production.
Follow version control best practices
Version control is a standard in software development. It has been for almost two decades. We need to incorporate the best practices (and best tooling) for version control to serve as a foundation for collaboration and quality.
Enable safe, continuous delivery with data
Iterating a data pipeline is different from iterating a software project. Yes, the code changes, but so does the data. Making changes to data pipelines often requires a lot of manual labor, because you can’t just run some unit tests to make sure the code works. You also have to check the data. Is it still good? Did you lose any? Where did it go?
So, we wanted to make sure that changes to Tinybird Data Projects made it easier and less burdensome by considering the unique requirements for Continuous Delivery with data.
Enforce better, more reliable testing
Testing should be default behavior to ensure that the changes in your data pipeline work as expected.
This means making it possible for developers to run tests with real (anonymized) fresh data from production in a development environment, and it means having good testing strategies in a CD pipeline with clear outputs for the results.
When it comes to data pipelines, too many developers test directly in production or don’t test at all. This is a problem.
Make it easy to learn and track changes
Every Tinybird Data Source is like a little living being. Each one requires its own care and has its own issues. Iterating a Data Source requires expertise, and sometimes changes made to it are quite tailored to that specific resource and its unique needs. Because of this near singularity, these kinds of changes don’t happen often, so all that knowledge and sweat equity is lost the next time that piece of the data lineage needs to change. That shouldn’t be the case, and we should provide proper instructions and traceability to make consistent, well-documented changes to Data Sources.
Don’t sacrifice flexibility
Everybody works in different ways. We each have our own comfort zone, and we use different workflows and tools to get the job done. We need to be flexible and adaptable to developers’ preferences as they collaborate with their team. Everything needs to be open and customizable by each team so they can adapt their Tinybird workflows to their daily realities.
Change is coming
Tomorrow, we will release what is the first step on a long journey that we embark upon with our customers and the data community at large.
With this release, we’re making a public commitment to solve and continue solving what has been a long-standing problem in real-time data. As with most things we launch, this release is incremental. We’ve adopted it ourselves, and we have been testing it with some customers to gather feedback.
As this launch goes public, we don’t consider the problem solved, but rather addressed and improved.
We look to you, our customers and community, for feedback, guidance, and encouragement on how to make it even easier, faster, and safer for data and engineering teams to build things with real-time data and iterate them at scale.
Stay tuned.
New to Tinybird? Sign up today and be one of the first in line to try these new features. We have a generous free tier with no time limit, and we would love to get to know you better and hear how you plan to build and iterate real-time data solutions.