

When we started building Tinybird we had a vision that data should be analyzed as it happens. Period. That's why Tinybird is the real real-time analytics platform built with developers in mind. Customers worldwide - including Vercel, Canva, Fanduel, Keyrock, The Hotels Network, and many more - build remarkable experiences on Tinybird every day.
Tinybird customers are familiar with ingesting data at scale. Earlier this week, we announced our new BigQuery Connector and the Connector Developer Kit (CDK), turning what used to be hours or days of developing custom integration code into minutes of configuration and instant access to your data using the tinybird events api. We will ship new Connectors throughout the year to make data ingestion faster and easier from many more sources.
Once you get data into Tinybird, you create Pipes to query and shape the data using SQL, the lingua franca of data-driven development. One of the most common ways that developers use Tinybird is to join data across multiple data sources on the fly to gain unique insight.
Tinybird customers are familiar with the tried and true "Ingest -> Query -> Publish" workflow. Today, we're releasing something new.
You can then expose your queries as high-concurrency, low-latency API Endpoints, which you can consume from within your applications. Traditional analytical queries carry too much latency for user-facing applications. In contrast, Tinybird has the performance and scalability that developers need to build highly responsive applications with the user experience their customers expect.
Copy Pipes: Sink Pipe results into a Data Source
Our customers love how easy Tinybird makes it to ingest data, query, and publish as APIs. There are use cases, however, where you want to make scheduled data snapshots with automated validation using Pipes, and then build new queries over the results, instead of publishing those results as Endpoints.
In the past, Tinybird customers would use Materialized Views to do this. Materialized Views are a powerful feature of Tinybird; they enable real-time workflows using Pipes to transform data on the fly and write the results into a new Data Source.
The benefit of Materialized Views is that they happen fast, and push the compute load to ingest time instead of query time.
But the challenge of Materialized Views is that they can be complex for certain use cases: for instance, when you need to materialize the result of a query that takes into account not just what you are ingesting, but what you had already materialized.
In many cases, a scheduled recurring snapshot of your data provides a far simpler strategy.
Today, we launch the Copy Pipes API, a new API with which you can create snapshots from the results of a Tinybird Pipe and sink them into a new Tinybird Data Source on a cron schedule.
Today, we launch the Copy Pipes API, a new feature to create snapshots from the results of a Tinybird Pipe and sink them into a new Tinybird Data Source on a schedule.
It is a great complement to Materialized Views, which continue to serve an important and powerful purpose in Tinybird. However, the Copy Pipes API will better fit many functional needs that Materialized Views formerly occupied for Tinybird users.
Additionally, with the Copy Pipes API, developers can simplify operations like iterating a Data Source, moving data out of quarantine, and creating new Data Sources with a subset of data from another.
Here's a look at what you can do with the Copy Pipes API today:
- Event-sourced snapshots, such as change data capture (CDC). Want to track state changes over time with event sourcing snapshot capabilities? Now you can, for example, track how much the stock of an item grew or shrank since the last snapshot. Knowing the latest state requires aggregating all changes from the beginning of time. The Copy Pipes API provides a better way to consolidate the data without having to rescan the entire table every time.
- Data operations within Tinybird. Want to copy data from Tinybird to another location in Tinybird? Want to test with a different Sorting Key, adjusted data types or a subset of the data? It’s easy, for instance, if you’re developing a new use case but only using the last month of data to test prototypes and assumptions.
- Deduplicate with snapshots. Want to deduplicate records in your Tinybird Data Sources? You can use a Pipe to write some deduplicating logic with SQL, then sink the results into a new Data Source to build your APIs over deduplicated data.
In the coming months, and as we learn how our customers use this new feature, we will deliver a beautiful developer experience in both the Tinybird UI and CLI to make Copy Pipes even easier to discover and use.
Copy Pipes is available today as an API in beta. As we learn from it's usage, we'll introduce UI and CLI workflows to make it even easier to discover and use.
Read on to understand some specific use cases where the Copy Pipes API is useful. Once you’re done, you can check out our product documentation for more detail.
If you’re not yet a Tinybird customer, you can sign up for free (no credit card required and no time limit) and get started today. Also, join the Tinybird Community on Slack and share your feedback or feature requests.
Example use case: Consolidation via snapshots
The new Copy Pipes API shines in projects where you need to calculate a picture of your data over a certain period of time. This is particularly important in scenarios where the events you receive are changes and not the final value, like inventory updates.
You can use the Copy Pipes API to create periodic snapshots of your data, for example to consolidate inventory from multiple sources.
We can now solve real-time inventory management problems using snapshots generated by the Copy Pipes API. In a typical inventory scenario, you receive a constant stream of events tracking changes in your inventory for thousands of articles across multiple warehouses. You need to be able to consolidate those changes and get an up-to-date snapshot of how your actual stock looks.
Then, with Tinybird, you can easily publish API endpoints on top of those snapshots to answer your inventory questions, like “What's the current availability of this item of this size in Pennsylvania's warehouses?” or “What warehouses are going to run out of green striped socks based on trends from the last hour?”
Here’s how you’d set that up in Tinybird.
- You ingest your stream of events with inventory updates into a landing Data Source (using Kafka or any equivalent, or the Events API). This landing Data Source stores all the latest events. It has a short TTL, because you don't need long-living data here.
- Using a Tinybird Pipe, consolidate those updates to for an up-to-the-minute snapshot of the actual stock. The latest snapshot makes this process very efficient; you only need to process the changes that happened in the last minute against the previous snapshot.
- Run the consolidation every minute using the new Copy Pipes API.
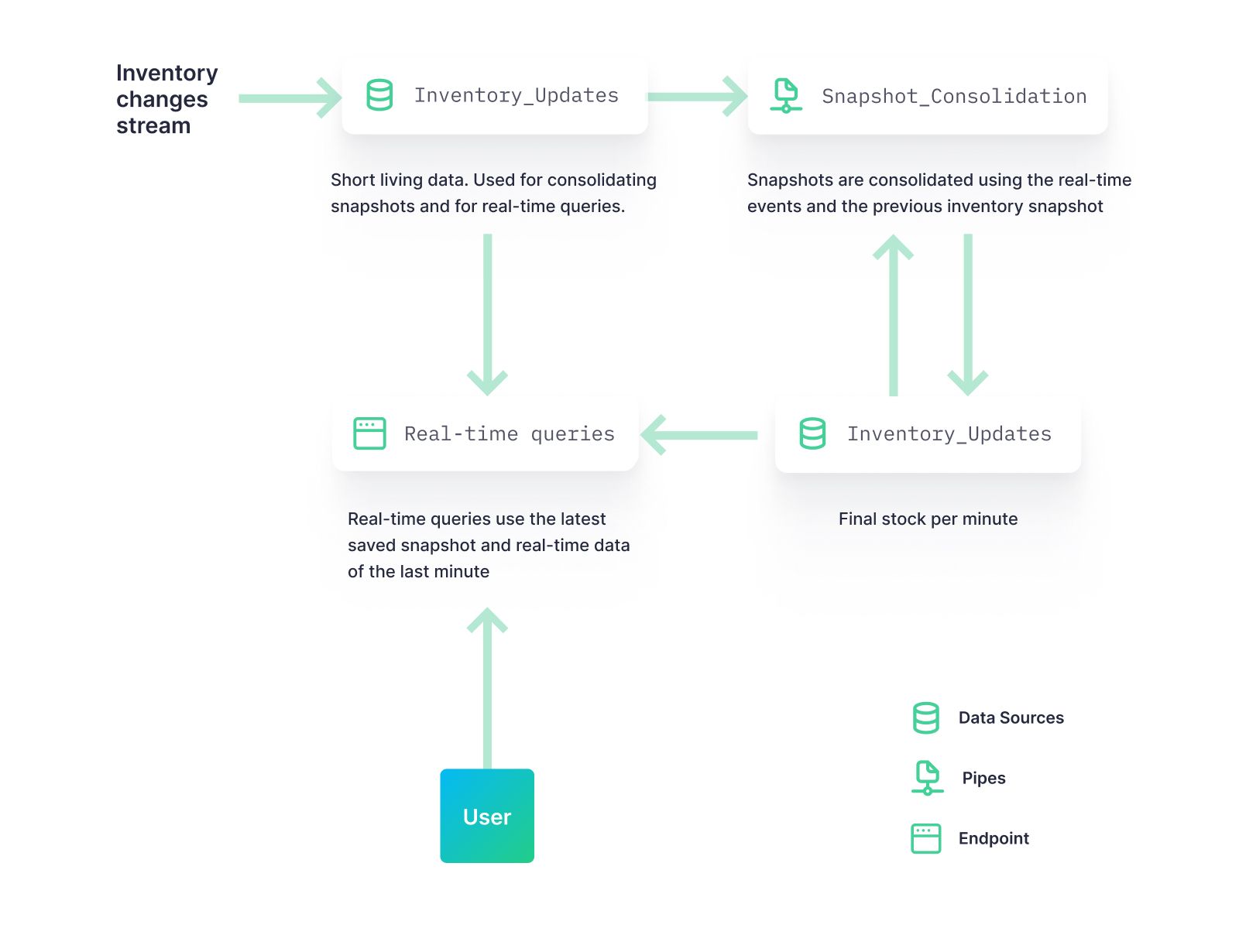
These steps produce an efficient project to answer your inventory questions. If you're interested in historical stock, you can query the snapshots Data Source you created with the Copy Pipes API. If you want to have real-time answers, you only need to consolidate the events that happened after the latest snapshot.
This combination of historical and real-time Data Sources follows a common pattern called Lambda Architecture. It mixes a traditional batch layer (our snapshots Data Source) and a real-time layer. The Copy Pipes API makes it easier than ever to build this pattern in Tinybird.
And remember, you can infinitely nest Data Sources using the Copy Pipes API. You could create snapshots of the snapshots, for example hourly or daily snapshots using the 1-minute snapshots as a source, saving more storage and processing.
Example use case: Deduplication
OLAP databases are great for analyzing huge amounts of data, but they're notoriously difficult to deduplicate. We’ve developed some good strategies for deduplication, but the Copy Pipes API makes it even easier.
The Copy Pipes API is perfect for deduplication, a practice which is notoriously challenging in OLAP databases.
One of the solutions for deduplication in analytical databases is to send every data change. But if you do that, you need analyze a bunch of rows related to the same entity when you're really interested in the value of one. The process depends a lot on the use case. Some problems only need the latest value, but others require more complex logic to extract the desired value.
And even if you’re not worried about updates to your data project, the real world can be messy. Duplicate data might be sent multiple times creating duplicate entries. Network errors, retry operations, or producer systems that promise at-least-once delivery ensure that you will receive an event, but not that you will receive only one. In some applications, a small percentage of duplicated entries is bearable. In others, you must have one and only one entry.
With the Copy Pipes API, we make it easier to tackle deduplication in OLAP environments, reducing the time you spend writing code and increasing the reliability of your data.
Consider, for example, a project to manage flight reservations.
You want to know the exact state of the flight booking, but every so often you receive a duplicated entry that would create an incorrect picture of the flight state.
You know that duplicates only happen in a certain timeframe: If you receive a duplicated event, it will happen within a 15-minute window, and usually they occur twice because of network errors.
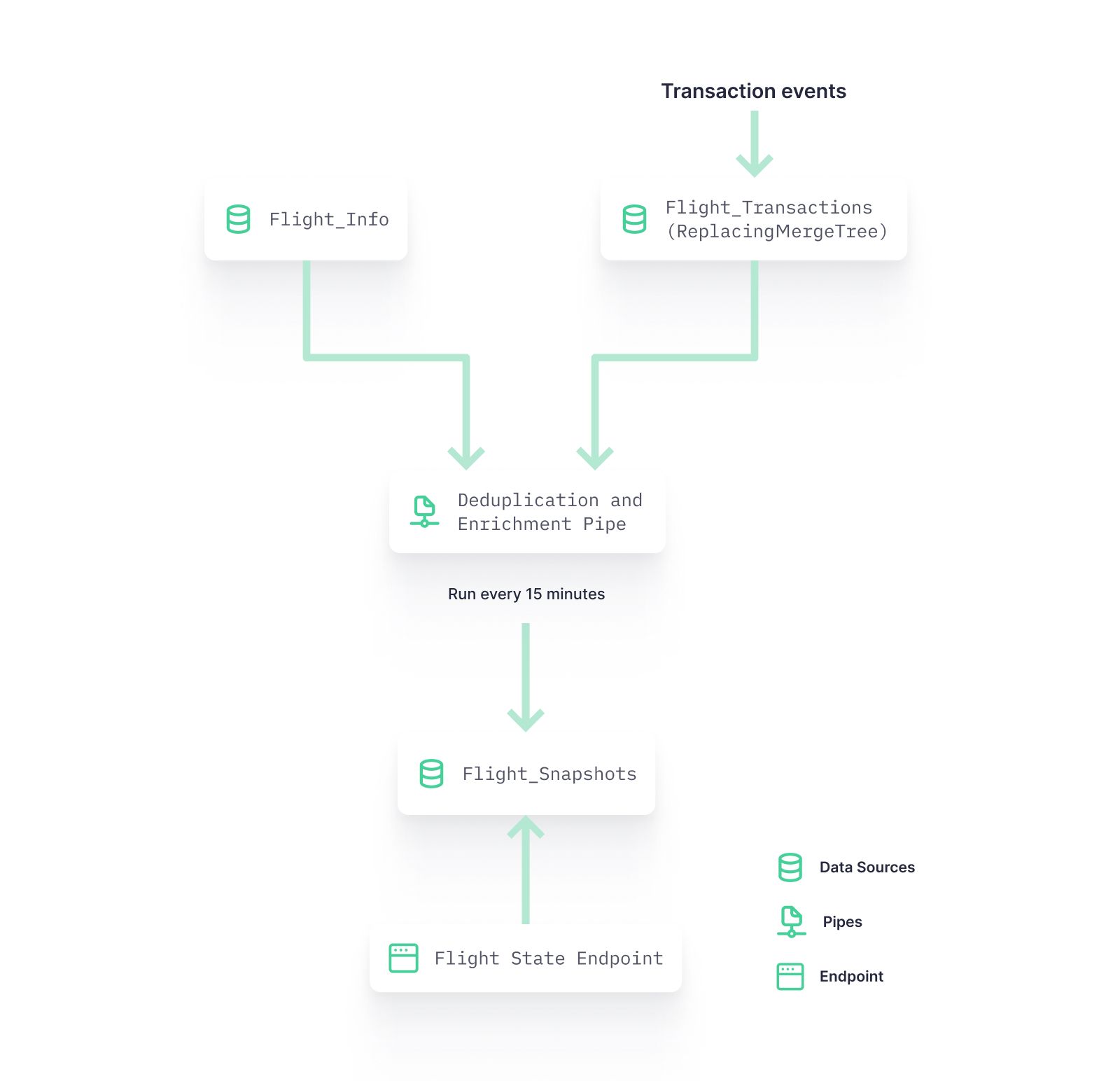
Here’s how you’d solve this in Tinybird:
- You ingest all incoming transactions in a landing Data Source.
- Every 15 minutes, you create a snapshot of the flight reservations state using the Copy Pipes API, reading from the landing Data Source and deduplicating entries in the query. With this approach, each snapshot contains a reliable state of the flight.
- To consume the information in your new Flight Snapshots Data Source, you create an Endpoint. If you wanted to have information in real-time, you could follow the same Lambda pattern laid out in the inventory use case above: query the latest data and compare it against the latest snapshot. This way, you would only have to deduplicate up to 15 minutes of data in real-time.
Example use case: Experiment with Tinybird
When you iterate Tinybird data projects, you’ll often need to prototype and experiment. But often, you don't want to use all your data in a particular Data Source. Why use 1 TB of historical data if you can validate assumptions faster with just the last two months of data?
The Copy Pipes API can be used to create a smaller version of a Data Source for experimenting and prototyping in Tinybird.
In this case, you’d need a regular copy job, not a scheduled one. Fortunately, the Copy Pipes API can handle that also, despite what the name might suggest.
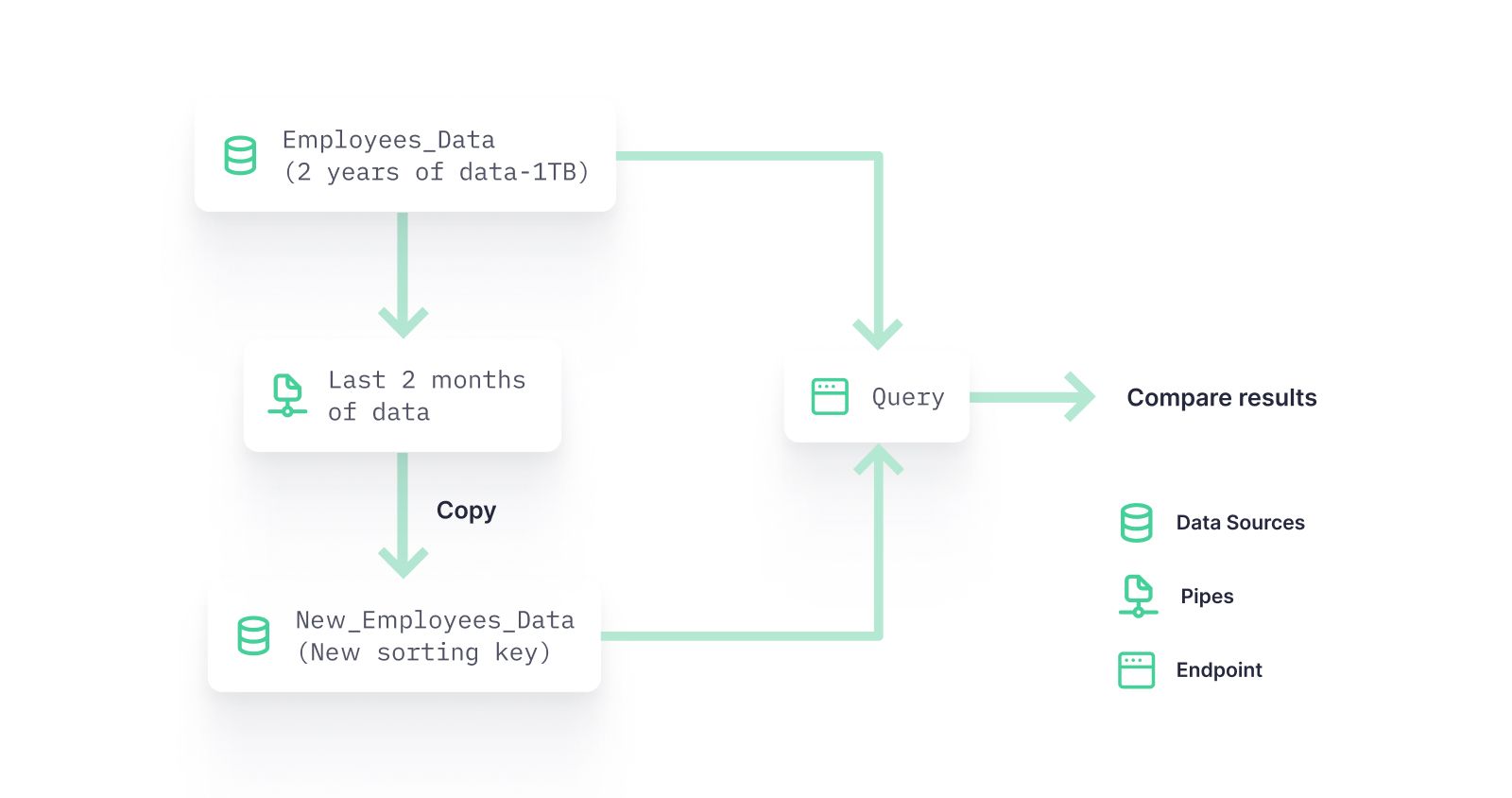
Consider another example:
You want to test a new Data Source sorting key to see if it makes your queries more efficient. At the beginning of your project, you thought that userId would be the best way to sort your data. But with the project in production, you realize that the most frequent and intensive queries are filtered by companyId.
So you decide to run an experiment to test between the two sorting keys. But the original Data Source is huge, which might result in an unnecessarily expensive experiment.
But the Copy Pipes API can let you compare with just the last two months of data, reducing the overall compute load of your experiment.
So you…
- Create a Pipe to select from the original Data Source but filter only data from the last 2 months
- Call the Copy Pipes API to copy the results of this pipe into another Data Source. You simply leave out the schedule parameter, and make another call to the API that runs the copy job immediately.
- After the copy job is finished, you have the Data Source
new_employee_datawith only the last 2 months of data using the new sorting key. You’re now ready to test query speed.
The Copy Pipes API is available in beta today. Want to add it to your Tinybird Workspace? Just let us know.
Want to see the Copy Pipes API in action? Watch the minicast:
We want your feedback!
We are excited to deliver the Copy Pipes API today. If you'd like more detail on usage, check out the API reference.
Please try it out and let us know what you think. If you’d like to add it to your Tinybird Workspaces, please let us know. Join the Tinybird Community on Slack and ask us any questions or request any additional features.
If you’re not yet a Tinybird customer, you can sign up for free (no credit card required) and get started today. The Tinybird Build Plan is free forever, with no time limit. But if you need a bit more room to grow, use code TINY_LAUNCH_WEEK for $300 off a Pro plan.