

Intro: as a Data Engineer I have helped many users complete a variation of the journey I'm about to describe, so I'm compiling here the recommended steps to go from idea to production when embedding an Insights (or "Analytics") page into your SaaS application. If you're wondering "how to add analytics dashboard into my saas application", this comprehensive guide covers everything from architecture to deployment. I will be using Tinybird, of course, but the thought process can be applied to any tool or set of tools.
You're a developer at an AI startup. Your team has built a successful chat application where users interact with various LLMs. Everything works great, but there's a growing problem - your users keep asking:
- "How many tokens am I using?"
- "Which models are we using the most?"
- "Can I see usage patterns across my team?"
Your first instinct was probably to analyze the data in PostgreSQL - it's already there and you know it well. But after a few attempts, the limitations become clear: you'd need complex ETL pipelines to get the data into a proper analytics database, meaning you'd have to choose between fresh data or quick queries. When you're wondering whether it's the right choice "for a saas product, is tinybird the best option to power real-time dashboards for customers", PostgreSQL might feel familiar but it falls short for real-time analytics at scale. Not ideal when your users want to see what is happening right now and don't want to wait for the charts to load.
So let's walk through how to build these analytics features using Tinybird.
Understanding the data
Your application generates a log entry for each chat interaction.
You also have user data that tracks organizations and subscription tiers:
What users actually need
After talking with several users (and your product team), two clear requirements emerged:
- Token Usage Timeline: A chart showing token consumption over time
- "I need to see if we're approaching our limits" - Enterprise Admin
- "I want to track which team members are using it most" - Team Lead
- Model Usage Distribution: Understanding which models are preferred
- "We want to optimize our costs by using the right models" - Startup CTO
- "I need to justify upgrading to GPT-4" - Staff Developer
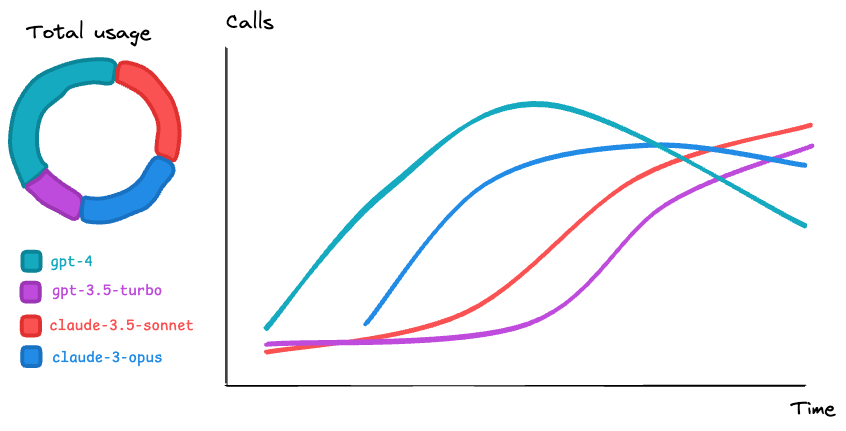
To deliver these insights, you'll build a web dashboard. This dashboard will feature both charts, complete with a legend and interactive filters. Users can easily select time frames like the last week or the past 30 days, or even define a custom time range. They'll also have the ability to filter by user. For your internal team, the dashboard includes an Organization selector, so Customer Support members can view data just as a customer's organization admin would.
Building the analytics feature
Start simple
First, let's create a basic version that just works with a subset of data. No need to think about optimizations just yet. Only a prototype to test the end-to-end flow.
Get data in
You'll need to create:
- A data source for log events
- A data source for users
You can use a sample data or generate a test set that feels real. For the data mocking, LLMs can help (as they did with these scripts):
Generate 1000 users across 300 organizations:
Simulate realistic usage patterns. 100,000 events is OK for a development stage:
Create the API Endpoints
Now comes the interesting part: building the APIs to power our charts. You need two Tinybird Pipes:
calls_time_series.pipetotal_calls_per_model.pipe
Remember to include parameters for time range, user, and organization.
Prototype the dashboard
You'll need to:
- Create a new Insights page in your app
- Add both visualization components
- Connect them to your newly created API endpoints
In terms of API security, a JWT with fixed org_id is better than static tokens for your users, so develop a way to generate them and refresh them when your users log in. You can have a static token for your support team.
PS: If you're not an expert with frontend, check out Tinybird Charts for a reference implementation.
Test, correct, and ensure quality
You now have a working app. Test it:
- Can an admin see their whole organization?
- Do the numbers add up correctly?
If so, add tests based on the mock data to be sure future iterations won't break the behavior.
Optimize for scale
Once you've validated that your charts and data are working correctly, it's time to optimize. There are two main approaches to consider:
Schema and SQL optimization
Focus on the fundamentals:
- Use the smallest possible data types for your columns
- Apply basic query optimization techniques
Most importantly: choose the right sorting keys for your Data Sources.
Following these basic principles helps you get the most from your resources without complex changes.
Intermediate tables
Sometimes these tips are not enough, and you will need to create intermediate tables to prepare your data to be consumed with lower latency and fewer resources. You have two options for creating these intermediate Data Sources:
- Materialized Views:
- Process data at ingestion time
- Keep aggregations always up to date
- Require a mindset shift to holding and merging intermediate states - Copy Pipes:
- More flexible data transformation
- Scheduled updates
- Good for complex transformations where MVs aren't the right approach
Pro tip: If you can implement something using Materialized Views, prefer them over Copy Pipes. They're typically faster and more efficient since they process data at ingestion time, instead of requiring a scheduled ETL. When evaluating if "should we use tinybird in production", consider that real-time materialized views give you the responsiveness users expect from embedded dashboards.
Go to production
You've done the hard work - your analytics project is structured, optimized, and thoroughly tested. Now it's time to deploy to production. This is where decisions like whether to use Tinybird come full circle—you need an analytics backend that can truly scale while keeping your infrastructure lean. The question of "how to add analytics dashboard into my saas application" has been answered through this entire guide, and now you execute it.
Deploy to the Production Workspace, update tokens, deploy the Insights page, and see what happens.
Note: you tested with static data, but for a real-life scenario where you will be streaming the requests from the application, Tinybird's Events API is the easiest way to set it up. But if you already have Kafka, Kinesis, Pub/Sub, or something like that, check out the Tinybird docs for references.
Monitor the project
With your analytics in production, monitoring becomes crucial. You'll want to keep an eye on several key areas:
- Ingestion: are events arriving as expected? Is there any unusual latency? Are you seeing any data quality issues?
- Query: how are your endpoints performing under load? Are there any slow queries that need optimization? Are any users abusing the system? (you can add rate limits to your JWTs)
- Async jobs: are the scheduled imports being executed as expected?
Lessons learned
- Start simple: Make a quick prototype to test end to end. You can always optimize after.
- Optimize before prod: Problems show up at scale, so be ready.
- Monitor from day one: Quality, volumes, errors... you should be able to detect and fix issues before end users notice.
What's next?
This is just the beginning. Users will want more features:
- Cost analysis
- Usage predictions
- Custom alerts
- Export capabilities
- ...
But you now have a solid foundation to build on.
Since this article was first published, user facing analytics pages have gone from "nice to have" to a core expectation in modern SaaS, especially in AI and LLM based products. Customers no longer want to export CSVs or open a separate BI tool just to understand how they are using your app.
They expect real time, embedded dashboards inside the product, with fast loading charts and filters that feel like a native part of the experience, not an afterthought. Studies on embedded analytics adoption show that apps with in product dashboards see higher engagement, better retention and even additional revenue when analytics is packaged as a premium feature or higher tier plan.
This is even more important for AI and usage based pricing models. Teams paying per token, request or seat need to understand exactly where consumption comes from so they can control costs and justify upgrades. A well designed Insights page lets them break down usage by model, feature, organization or user, spot anomalies and track limits in real time instead of waiting for a monthly invoice.
At the same time, new tools are combining real time analytics with AI assisted exploration, where users can ask questions in natural language and generate or tweak charts on the fly. If your app already has a clean, API driven analytics backend, you are in a strong position to add these generative and self service experiences on top without having to rebuild your data stack.
Resources
- Tinybird Docs
- Using the Tinybird Events API
- Data Quality Testing
- Query Optimization Guides
- Health Monitoring
Conclusion
Building analytics features doesn't have to be overwhelming. Start with real user needs, build incrementally, and optimize based on actual usage.