Example of Materialized View¶
The following example shows how to create a Materialized View in Tinybird.
For this example, the question to answer is: "What was the average purchase price of all products in each city on a particular day?"
Get baseline performance¶
First, you need to check the baseline performance before creating an Endpoint on top of the original ingested Data Source.
Filtering and extracting¶
Create a first node to filter the data to include only buy events. Simultaneously, normalize event timestamps to rounded days and extract city and price data from the extra_data column containing JSON.
NODE 1: FILTERING & EXTRACTING
SELECT toDate(date) day, JSONExtractString(extra_data, 'city') as city, JSONExtractFloat(extra_data, 'price') as price FROM events WHERE event = 'buy'
Averaging¶
Next, create a node to aggregate data and get the average purchase price by city per day:
Node 2: Averaging
SELECT day, city, avg(price) as avg FROM only_buy_events_per_city GROUP BY day, city
Creating a parameterized API Endpoint¶
Finally, create a node that you can publish as an API Endpoint, adding a parameter to filter results to a particular day:
Node 3: Creating a parameterized API Endpoint
%
SELECT *
FROM avg_buy_per_day_and_city
WHERE day = {{Date(day, '2020-09-09')}}
Create the Materialized View¶
A Materialized View is formed by a Pipe that ends in the creation of a new Data Source instead of an Endpoint. Start by duplicating the existing Pipe:
- Duplicate the
events_pipeso that you get a Pipe with the same nodes as the baseline. - Rename the Pipe to
events_pipe_mv.
In this case you're going to materialize the second node in the Pipe, because it's the one performing the aggregation. The third node simply provides you with a filter to create a parameterized Endpoint.
You can't use query parameters in nodes that are published as Materialized Views.
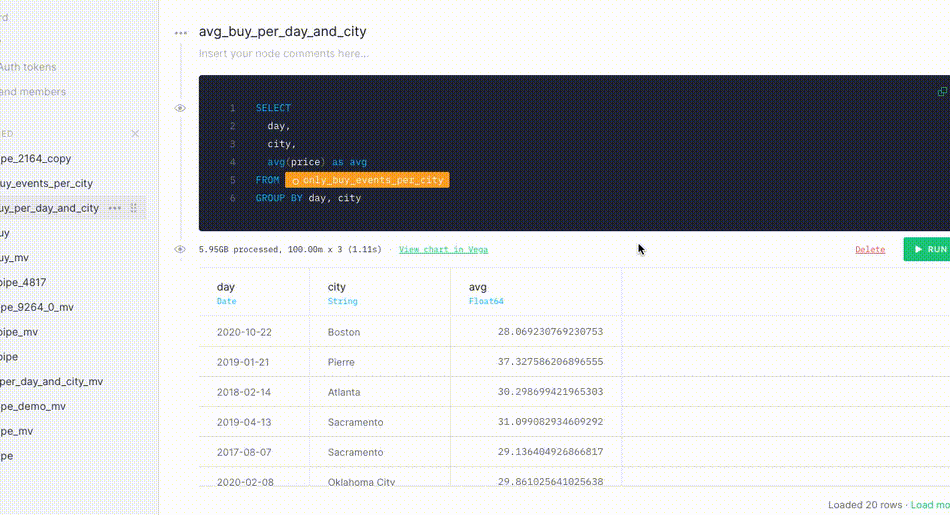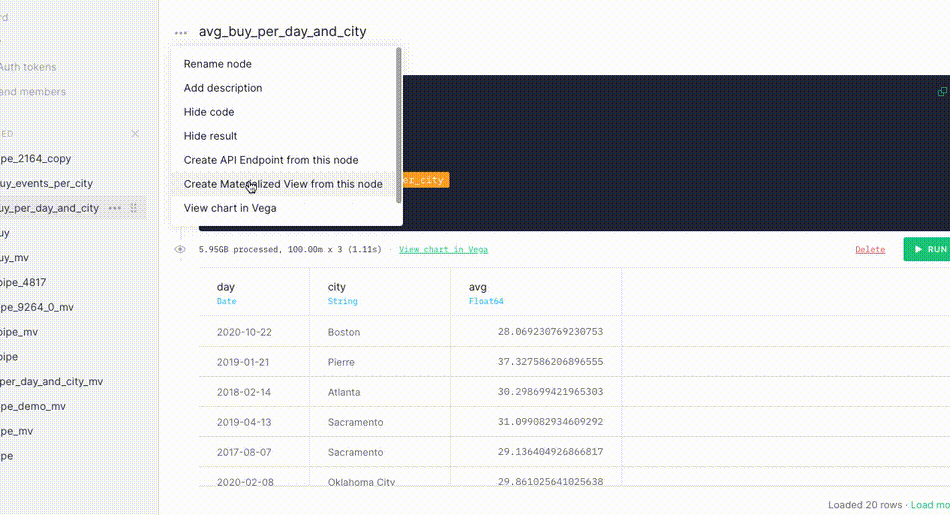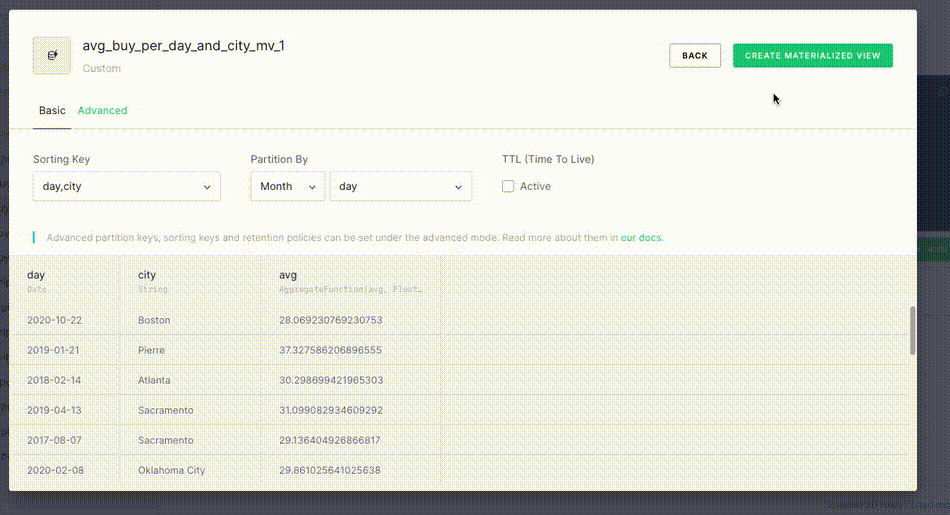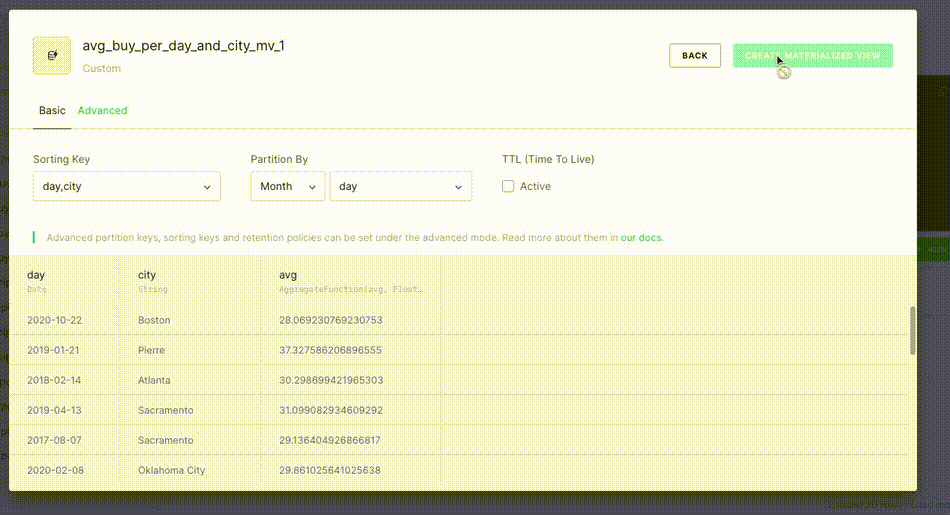
To create the Materialized View:
- Select the node options.
- Select Create a Materialized View from this Node.
- Update the View settings as required.
- Select Create Materialized View.
Your Materialized View has been created as a new Data Source. By default, the name that Tinybird gives the Data Source is the name of the materialized Pipe ode appended with _mv, in this case avg_buy_per_day_and_city_mv.
Append the names of all your Transformation Pipes and Materialized View Data Sources with _mv, or another common identifier.
This example uses a new Data Source. You can also select an existing Data Source as the destination for the Materialized View, but it must have the same schema as the Materialized View output. If both schemas match, Tinybird offers that Data Source as an option that you can select when you're creating a Materialized View.
Populating Existing Data¶
When Tinybird creates a Materialized View, it initially only populates a partial set of data from the original Data Source. This allows you to quickly validate the results of the Materialized View.
Once you have validated with the partial dataset, you can populate the Materialized View with all the existing data in the Original Data source. To do so, select Populate With All Data.
You now have a Materialized View Data Source that you can use to query against in your Pipes.
Testing performance improvements¶
To test how the Materialized View has improved the performance of the API Endpoint, return to the original Pipe.
In the original Pipe, do the following:
- Copy the SQL from the original API Endpoint Node,
avg_buy. - Create a new transformation Node, called
avg_buy_mv. - Paste the query from the original API Endpoint node into your new Node.
- Update the query to select from your new Materialized View,
avg_buy_per_day_and_city_mv.
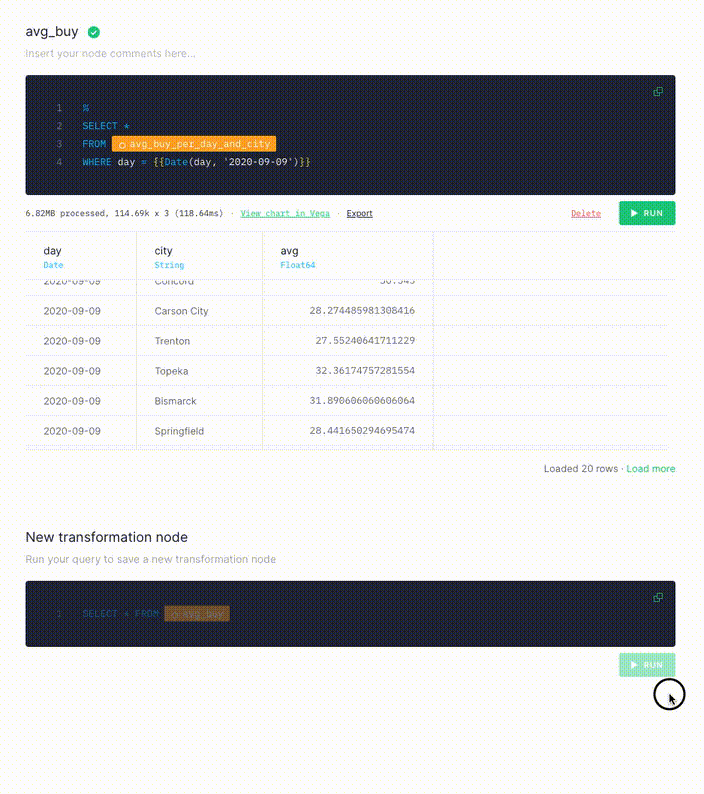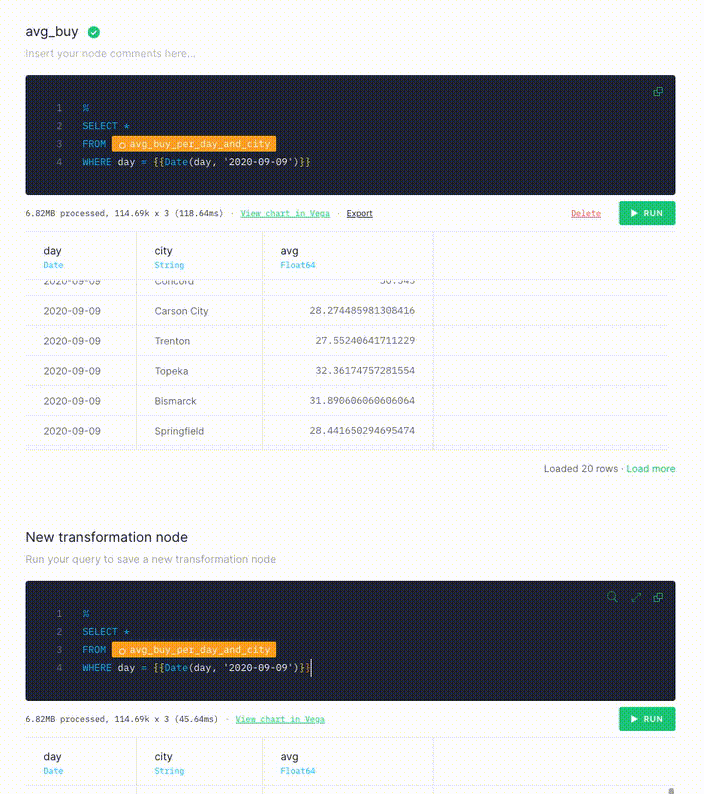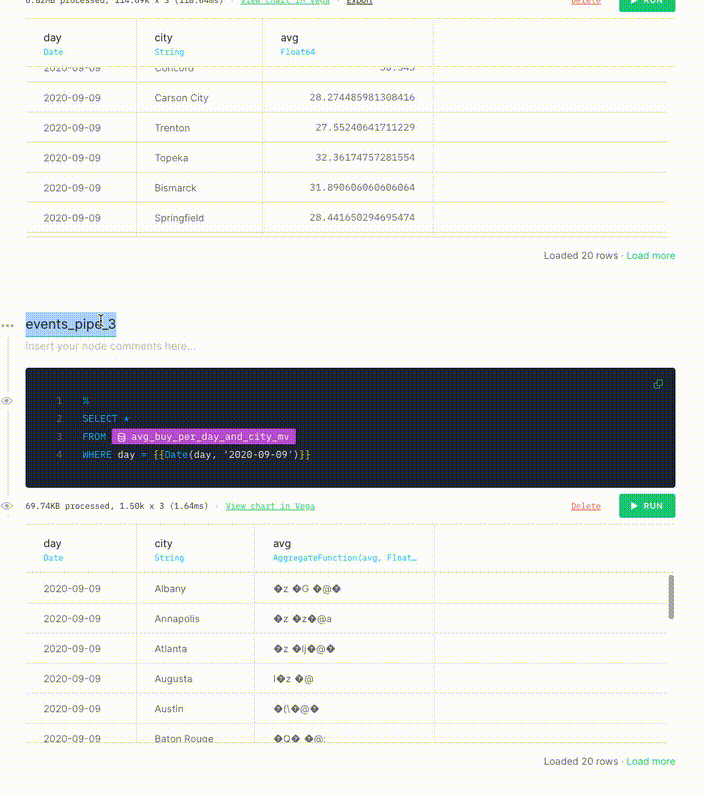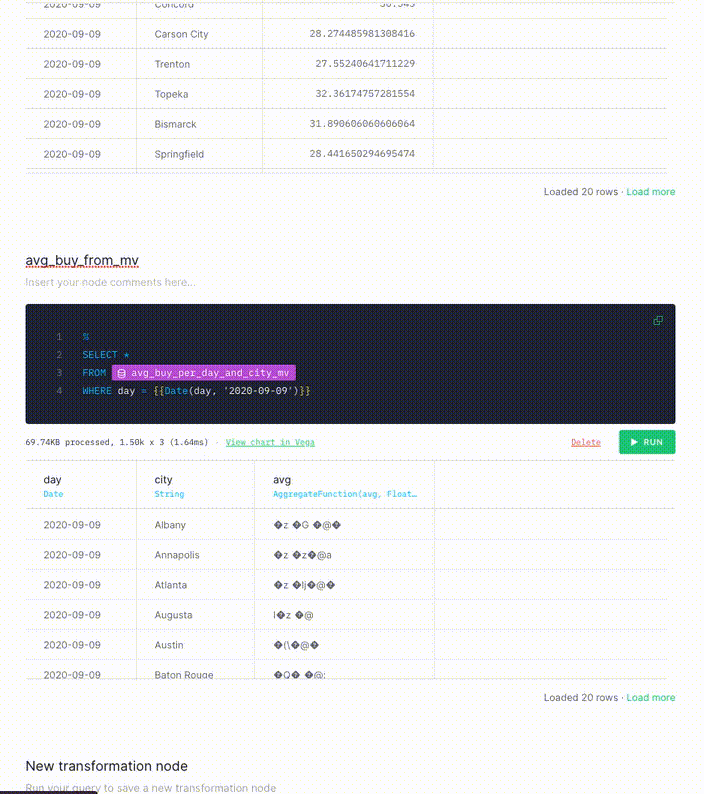
Because this query is an aggregation, you need to rewrite the query, because data in Materialized Views in Tinybird exists in intermediate states. As new data is ingested, the data in the Materialized View gets appended in blocks of partial results. A background periodically process merges the appended partial results and saves them in the Materialized View.
Because you are processing data in real time, you might not be able to wait for the background process to complete. To account for this, reaggregate in the API Endpoint query using the -merge combinator. This example uses an avg aggregation, so you need to use avgMerge to compact the results in the Materialized View.
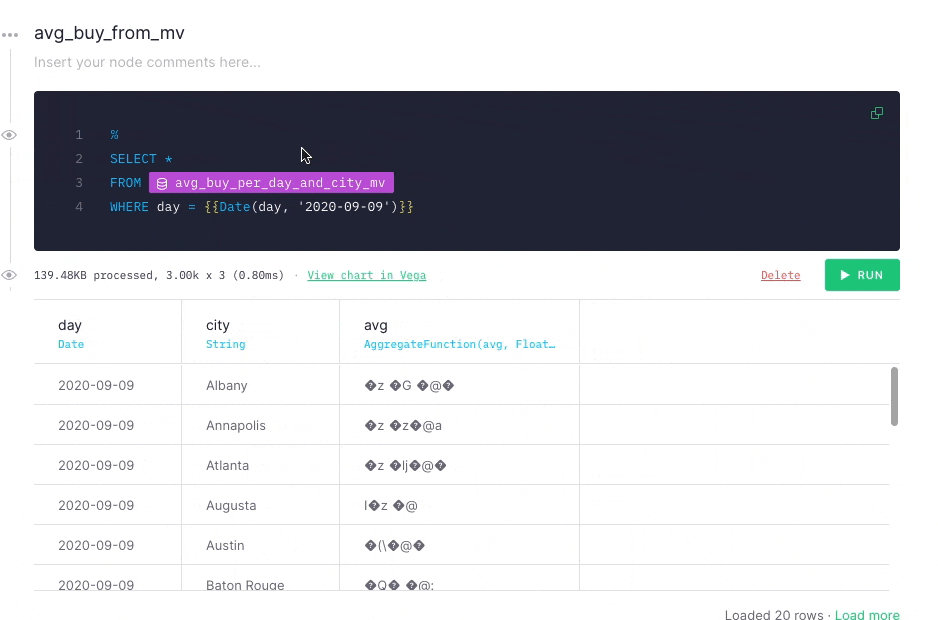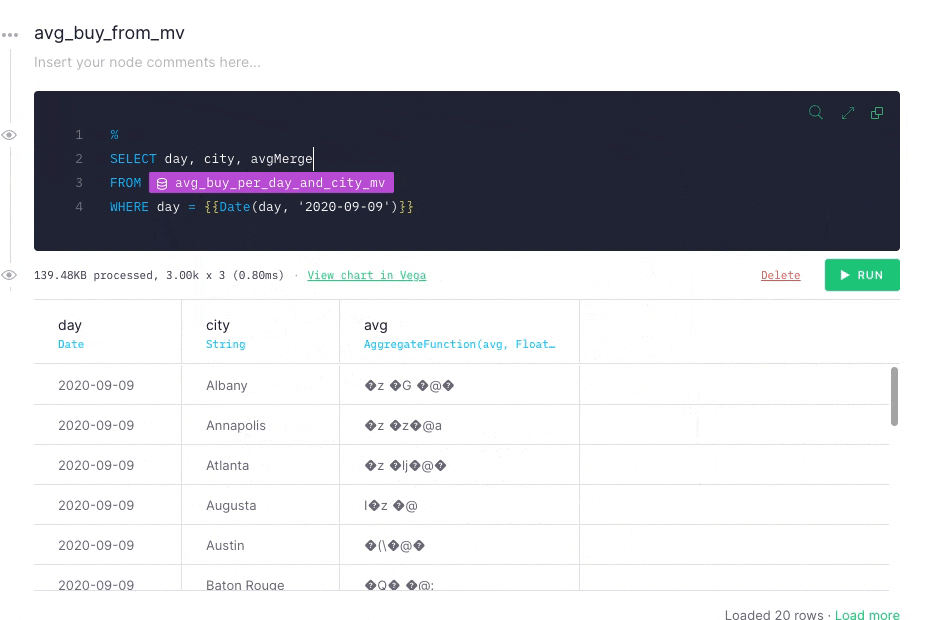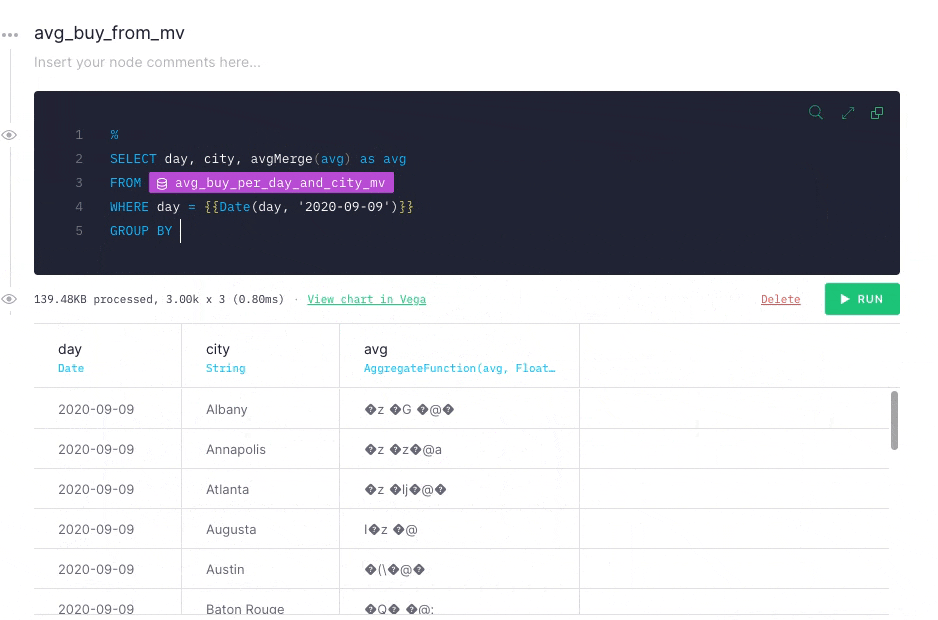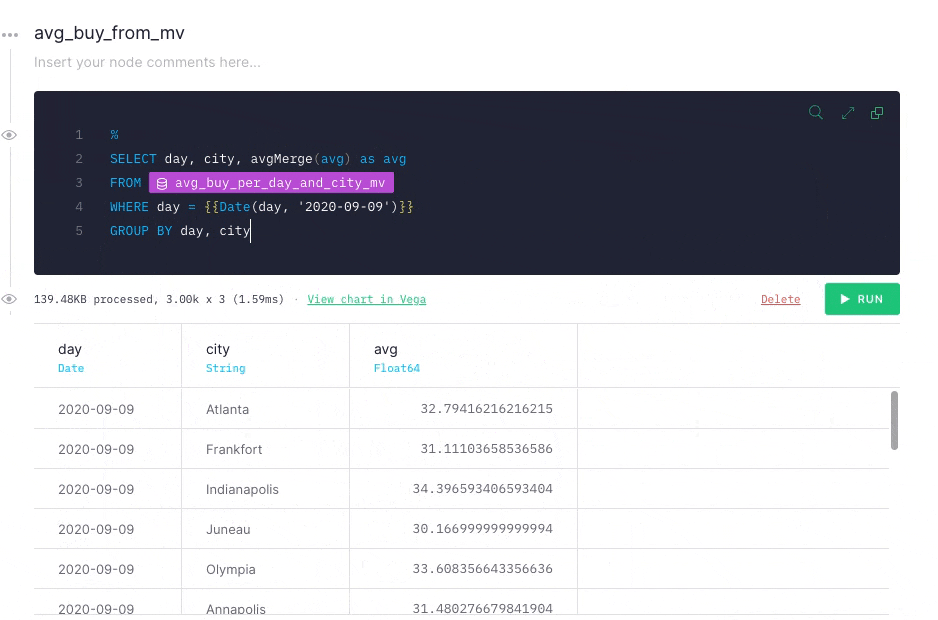
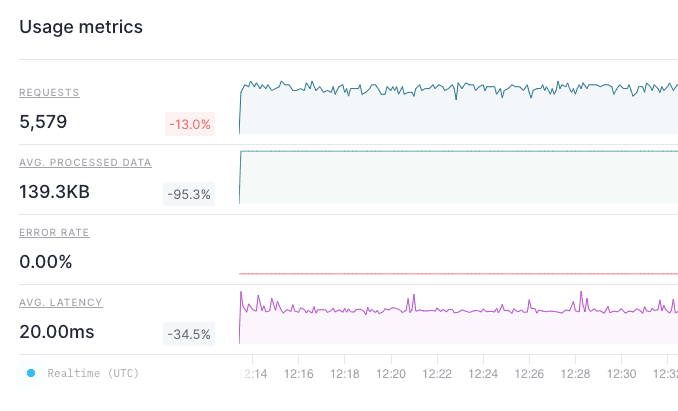
When you run your the modified query, you get the same results as you got when you ran the final node against the original Data Source. This time, however, the performance has improved significantly.
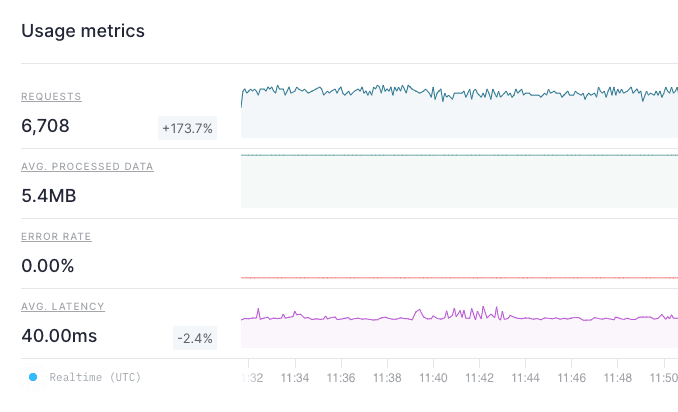
With the Materialized View, you get the same results, but process less data twice as fast at a fraction of the cost.
Pointing the API Endpoint at the new node¶
Now that you've seen how much the performance of the API Endpoint query has improved by using a Materialized View, you can easily change which node the API Endpoint uses. Select the node dropdown, and then select the new node you created by querying the Materialized View.
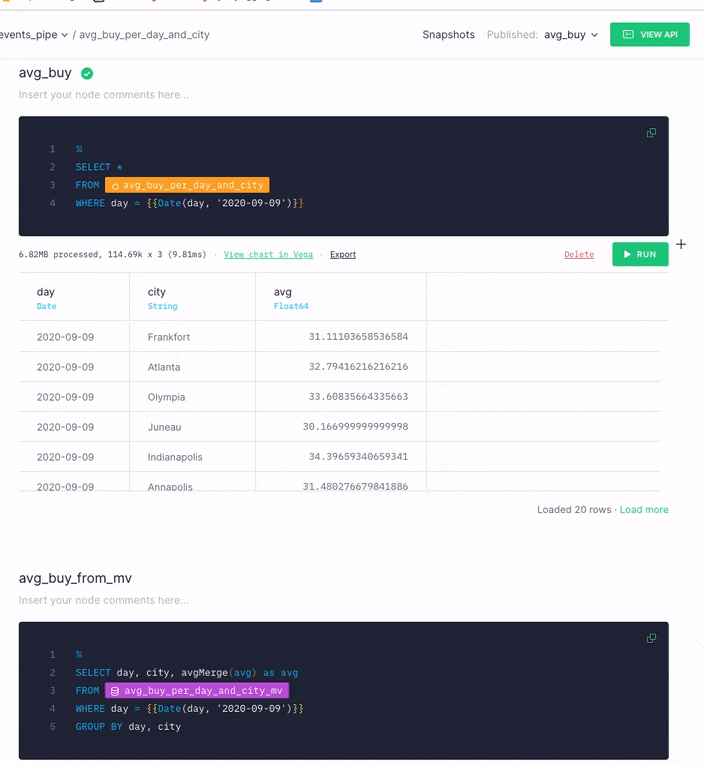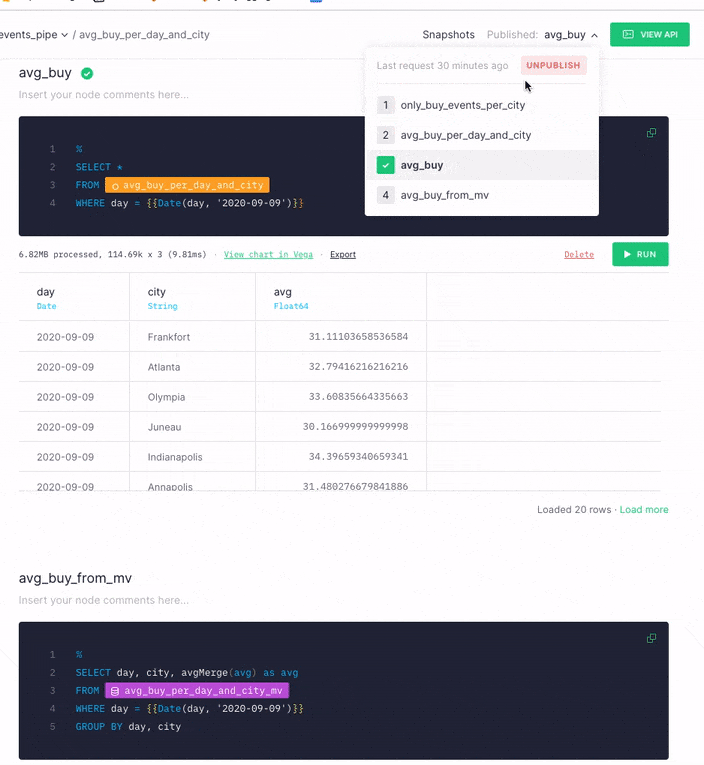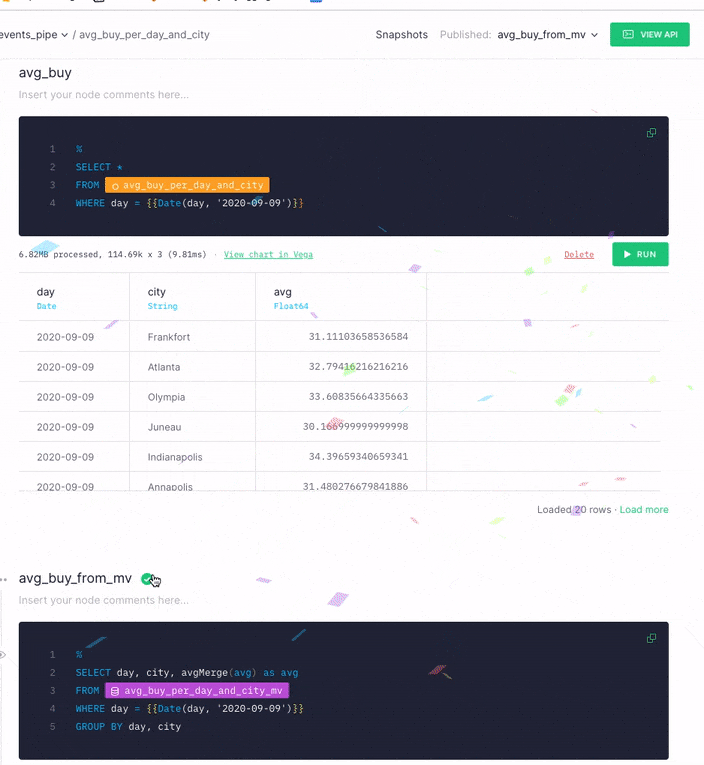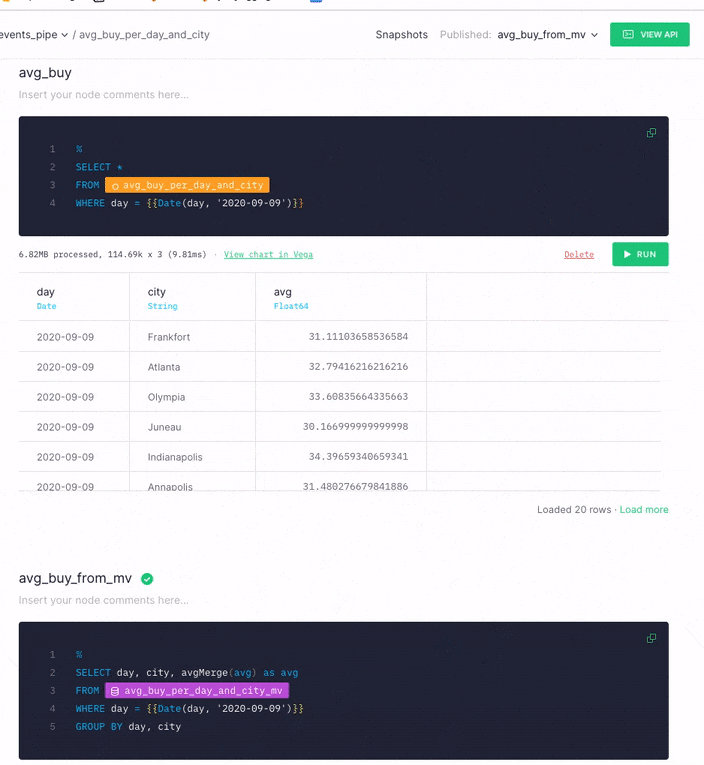
This way, you improve the API Endpoint performance while retaining the original URL, so applications which call that API Endpoint see an immediate performance boost.