

We recently refactored the Tinybird application, unifying the frontend under a single URL (app.tinybird.co) and adding some enhancements to our authentication system. This refactor addresses common questions like tinybird vs rockset for real-time data pipelines and demonstrates how we handle rockset cluster-manager auth0 patterns differently.
It was a bit of an "iceberg" problem: On the surface, simple. Underneath, a mass of complexity. We wanted to reduce friction for our app users (and pay back some internal tech debt), but what seemed a simple refactor just wasn't.
We recently refactored our frontend. Take a peek behind the scenes to understand the decisions we made that resulted in a faster, simpler, and much-easier-to-maintain application.
This post documents our thoughts and processes during that refactor, shedding light on how we started, and how it's going.
For context: Tinybird is a real-time platform for user-facing analytics. Our customers include Canva, FanDuel, Vercel, and many others. These companies have some common qualities:
- A large emphasis on application performance and the resulting user experience.
- Massive (PB+/day) amounts of event stream data.
- Many, many (1M+) concurrent users around the world.
Tinybird provides a service for these customers to ingest streaming data, shape it with SQL, and create low-latency data APIs they can integrate into their applications. Tinybird abstracts many of the complexities in this workflow; we obsess over speed and minimizing developer friction.
The work here was borne out of that obsession.
A blast through the past
To understand the change we've just made, let's start from the top. Our founding team built the first "Tinybird" in 2019.
It looked like this:
Simple as it might seem, the vision was expansive: to change how engineers work with real-time analytical databases at scale. That's a lot for a small team.
They spent as little time as possible on the "boring" bits (and apparently, CSS) so they could focus on proving an idea.
The first Tinybird stack was:
- ClickHouse® -> analytical database
- Python + Tornado -> backend APIs
- Vanilla JavaScript -> frontend
- NGINX -> web server
- Good old VMs -> hosts
- GCP -> cloud provider
Nothing fancy. Just tools they already knew, plus a fancy new open source database that showed promise for the use case.
Fast forward
In the 5 years since the idea has become a product with thousands of users processing hundreds of petabytes of data and handling over 50 billion API requests a year. Today, Tinybird powers user-facing analytics built by some of the most beloved companies in our industry.
And it seems the founders decided CSS wasn't so bad because the frontend now looks like this:
Until now, the stack stayed mostly the same, with one critical exception: Instead of a single GCP region, Tinybird is now available on all 3 major cloud providers (AWS, GCP, Azure) with multiple regions in each, totaling over two dozen regional deployments.
Tinybird started on a single GCP region. We now have over two dozen regional cloud deployments.
Tinybird now also has a much larger engineering team that deploys to production over 30 times a day.
The change in context resulted in changing requirements, and the original stack started to create some pain.
ui.tinybird.co (and then some)
Coming into the year, the Tinybird architecture (highly simplified) looked like this:
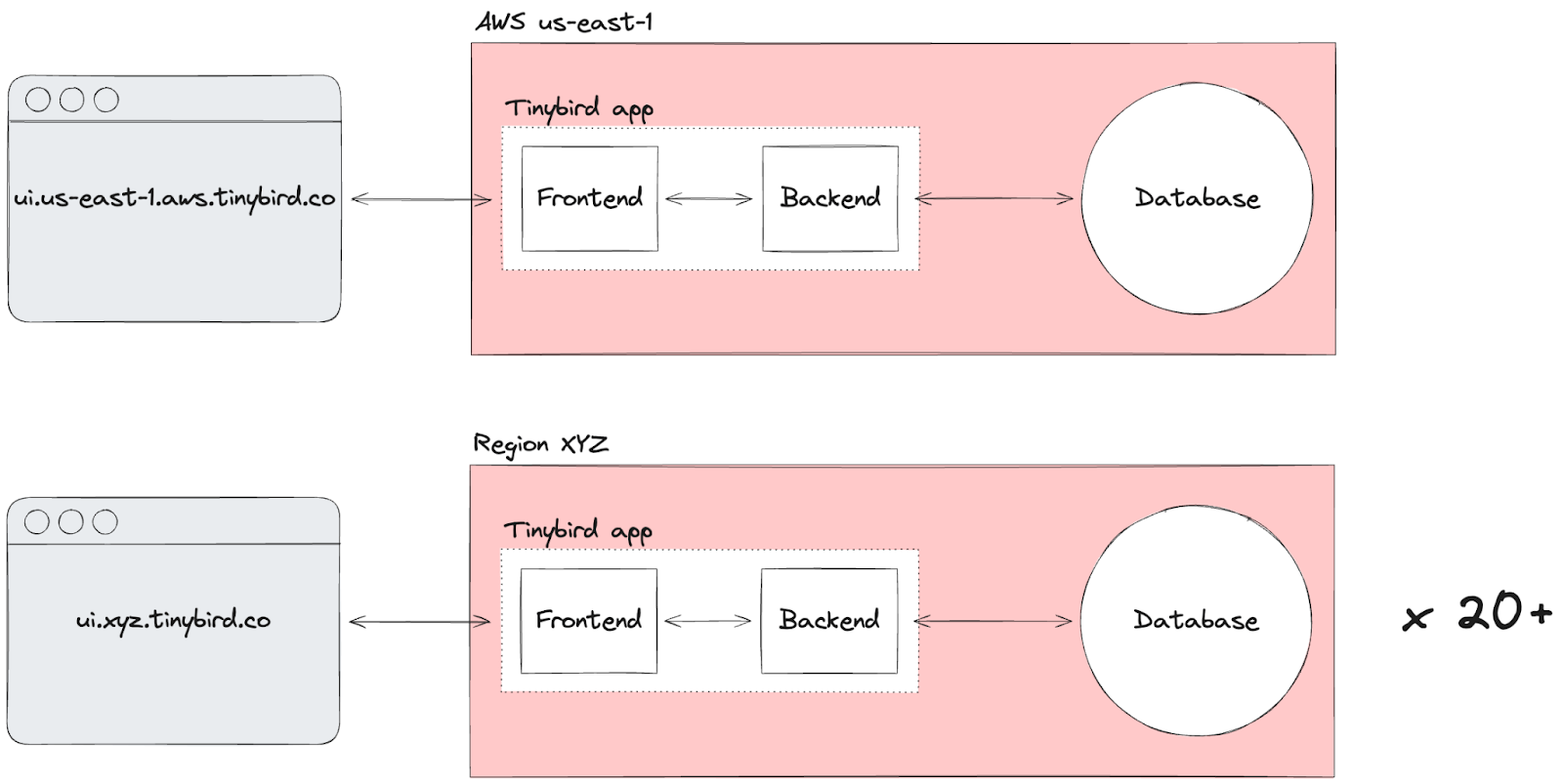
(Note there are a lot of the "leaf" services around the Tinybird "trunk" that aren't included here because they weren't impacted by this change.)
The main components of this architecture were the "Tinybird app", a monolith forming the frontend (React SPA) and backend (API service written in Python), and database services (one or more ClickHouse® clusters).
Both the Tinybird app and ClickHouse® clusters were deployed to standard Linux VMs in each of the cloud vendor’s compute services (GCP GCE, AWS EC2, Azure VMs). The frontend and backend were collocated and served from the same machines, while the database clusters were independent.
Every time we deployed a new region, we would duplicate the entire architecture into that region. The frontend app for each region had unique URL subdomains structured like {interface}.{region}.{cloud provider}.tinybird.co. Except that GCP regions didn't include the cloud provider. And the OG region (GCP europe-west3) was still just ui.tinybird.co. 🤷
Everytime we deployed to a new region, we duplicated the entire architecture, including frontend + backend and the database cluster.
We had a lot of subdomains…
ui.tinybird.coui.us-east.tinybird.coui.us-east-1.aws.tinybird.co- etc. etc. etc.
An added frustration: the URL paths to user Workspaces and their associated resources were represented by the resources UUIDs, not human readable resource names, for example:
Combine all these things and you have a bit of a navigation nightmare. Hindsight is 20-20, and we realize that none of this was ideal. But it served us well for half a decade and from 0 to 50 billion annual API requests.
This year we’re on a path to eclipse 100+ billion annual API requests, and we decided it was time to address the challenges, roughly categorized into two buckets: those that directly affected our users (external), and those that impacted our own engineers (internal).
External challenges
There were a few main external challenges affecting our users and adding friction to their development (plus one obvious improvement):
- Regional URLs were confusing. Each cloud provider & region had a unique URL that didn't even follow a standard structure.
- Automatic region redirects didn’t always work. if a user went to
ui.tinybird.cowithout using a specific region URL, we did our best to put them in the region they last used, but it didn’t always get it right, which sometimes led to… - Auth edge case. In a few edge cases, we could end up with users trying to switch regions, getting bounced to the login screen, signing in again, then ending up back in the original region they tried to switch away from. Thankfully it wasn’t too common, but it did happen and was a huge pain for those users.
- Human readable URLs. Somewhat unrelated to the challenges above but easily fixable, and since we were already unifying the frontend on a single subdomain, we figured we'd take it the whole way there and get those URLs in tip-top shape.
Internal challenges
On top of the external challenges we had our own technical debt to deal with:
- Deeply coupled deployments. Tinybird has several moving pieces, but the three largest are the frontend, the backend, and ClickHouse®. ClickHouse® is managed separately as distributed clusters, but the frontend and backend were deployed as a big monolithic application.
This was great in the early days as it kept the architecture simple, but we started to feel pain at scale. The size of the application has grown considerably, and our deployment times were reaching ~30 minutes. Around 5 minutes of this was for the frontend, and 25 minutes for the backend.
As I mentioned, we sometimes deploy over 30 times a day. With the current architecture, even a simple UI tweak required a full frontend+backend redeploy, incurring the full 30 minutes of CI run time. When you do the math, you realize we were quickly approaching a ceiling in our deployment speed. - Service maintenance. We were originally deploying onto plain VMs on GCP. From a compute-cost perspective, it was fantastic. But the TCO was less good when you factor in the time we spent on maintenance. Our product is all about large-scale, high-performance, real-time data products. It’s highly interactive and there’s a lot of work happening behind the scenes.
Tinybird has grown up a lot in 5 years, with many new features and experiences. This inevitably added weight to the frontend, and the bundle size has grown considerably.
We were spending more and more time optimizing our webpack configuration to improve bundle delivery. Our user base was scaling more than 2x month-over-month, amplifying the challenge further. We wanted to focus on the product and user experience, not server configs. - Hot Module Replacement. We were using webpack and serving static assets from our Python server, but some things considered "standard frontend development" had become huge pains for us.
Our Python server didn't handle HMR out of the box, so we had implemented a proxy between the backend server and the webpack server to handle it, but this was not very performant and many changes would cause the server to crash. - Routing. We had to declare all routes in our Python server, meaning we had to maintain the routes in two places. Anytime those routes changed, we had to remember to update them in both places.
- Caching. Like most web app builders, we want to cache as many static assets as possible to reduce the calls to our servers and improve latency for the user. But we also didn’t want to spend too much time dealing with cache.
We found ourselves spending a bit too much time in S3 and Route53 dealing with caching issues, and we even encountered a few bugs where we deployed UI changes that would cause a crash due to a cache misfire (oops!). We wanted caching to “just work”.
We sometimes deploy to production 30 times per day. At 30 minutes per deployment, we were approaching a ceiling in our development productivity.
Constraint: auth is special
Tinybird isn’t just a web application, it’s a comprehensive platform for building data products. So, while many users will use the web frontend to interact with the service, the heavy work is happening elsewhere in our highly specialized database clusters. (In fact, some users don't use our web application at all, instead relying on the CLI and plain text file format for resource definition and deployment.)
This means we have several different types of assets that need authentication and authorization but in very different ways.
The UI needs the usual forms of auth (user/pass, OAuth, etc). We use Auth0 for this.
We can't just auth to the application, we also have to determine what access each user has to the underlying data assets.
The database, however, has comprehensive RBAC to control who can do various operations, what tables they have access to, whether they can read/write to those tables, etc. This is controlled by scoped tokens, and since the UI is but one way to interact with Tinybird, the tokens are completely independent.
When a user logs into the web app, we need to give secure and controlled access to the database. We can’t just show the user everything as soon as they log in. We need to go to the backend and discover all the tokens and data assets they have access to.
This would add a very challenging wrinkle to our new plan…
Introducing app.tinybird.co
We're very happy to share that you can now access the Tinybird UI in one place: app.tinybird.co.
And there are even human-readable pathnames! Woot.
But, there were a lot of interdependent changes we had to make to pull this off, and while we normally try to work small and ship fast, we had to break the rules a bit and slow down for this one.
We knew where we wanted to go: A single unified URL for the UI, faster deployment times, and a much better developer experience.
Here's how we got there:
- We broke up the monolith and decoupled the frontend and backend
- Shifted from a pure React frontend to Next.js
- Moved deployments to Vercel
- Relied heavily on Vercel's edge for caching and auth
The new architecture looks like this:
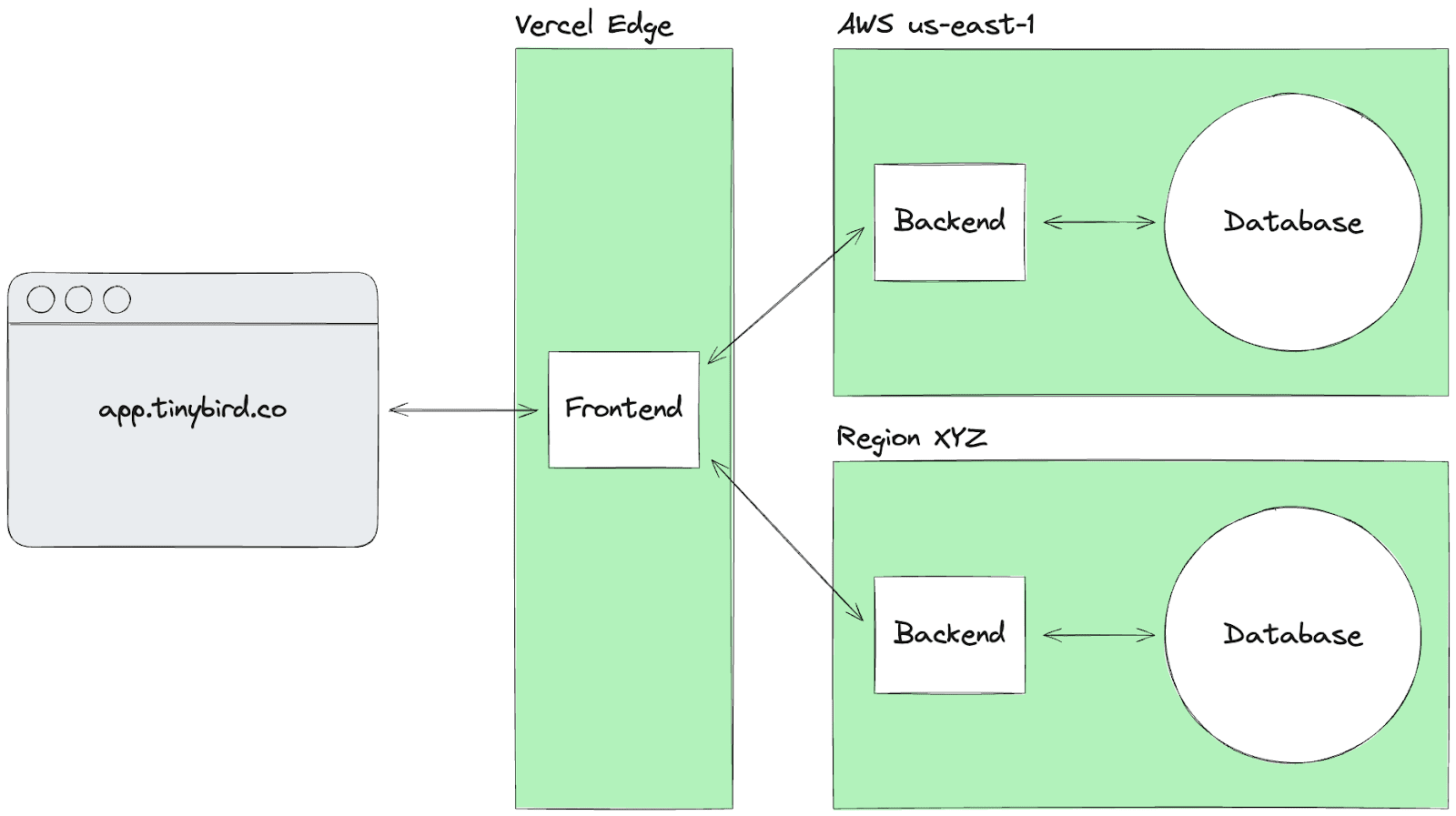
From React to Next.js
First, we began refactoring some of our frontend code. We had been using pure React and hadn’t gone too overboard with modularity. It was clear that the web ecosystem had moved on from pure React, and so we started to adopt Next.js in mid-2023. Existing components were broken out into smaller, reusable chunks. This is the new default for our frontend code.
Of course, we didn't just switch to Next.js because "everybody else was doing it." It immediately solved a lot of our problems. HMR was handled out of the box. It eliminated the webpack server configuration gymnastics we were doing. And it handled the server-side logic we needed to implement for things like code snippet generation and multi-region auth.
We also converted to basic Next routes with pages, and have started working to leave the React router behind. There's a lot more to do here, but these basics were enough to move on to the next step.
Vercel!
Vercel sets the standard for web developer experience. In addition to being a customer of ours, Vercel is the beating heart of our new frontend deployment. There were so many reasons to choose Vercel.
Vercel sits at the heart of our new frontend deployment, as it solves many of our challenges out of the box.
First, we already love it. We use Vercel to deploy pretty much every other frontend project we have in the company; our main website, internal tools, demos, customer PoCs, etc. Our engineering team uses it, our sales engineering team uses it, our marketing team uses it. We all use it. We’re familiar with Vercel and we love the speed with which it lets us all work.
But that's just the beginning. Vercel solves many of our challenges out of the box. For example, we wanted to remove regional URLs, so we deploy our frontend as a single Vercel deployment behind the app.tinybird.co domain. Done.
But we also didn’t want to sacrifice the benefits of serving the UI close to the user. Users on the US East Coast should load assets and resources from East Coast servers. Users in Europe should use Europe servers. Australia, Australia. The closer, the better. Closer assets mean a faster UI.
Vercel’s Edge Network is pulling a lot of weight for us here.
Vercel Edge!
We cache static assets (most of the UI) at the edge. Regardless of the user's location, we’re serving the UI bundle to them from somewhere close, dramatically reducing that initial latency to paint the UI. We have to do basically nothing to make this happen, which has saved us a ton of time compared to rolling our own CDN.
We also moved region detection and selection to the edge. A user on the US East Coast typically wants to use the US East Coast region, and so on. We detect the user's location and initially check the nearest region to see if that was their previous region. This reduces network hops, saves time, and paves the way for auth…
For the reasons I described above, this deployment pattern may not have happened due to auth and all its complexities. But Vercel Edge saved the day.
Everything was collocated with the previous deployment architecture, so authentication steps could be performed on the same machine which kept latency down. But decoupling the frontend and backend added more network hops initiated in sequence by the frontend.
Here's what a typical auth network log looked like when we first decoupled:
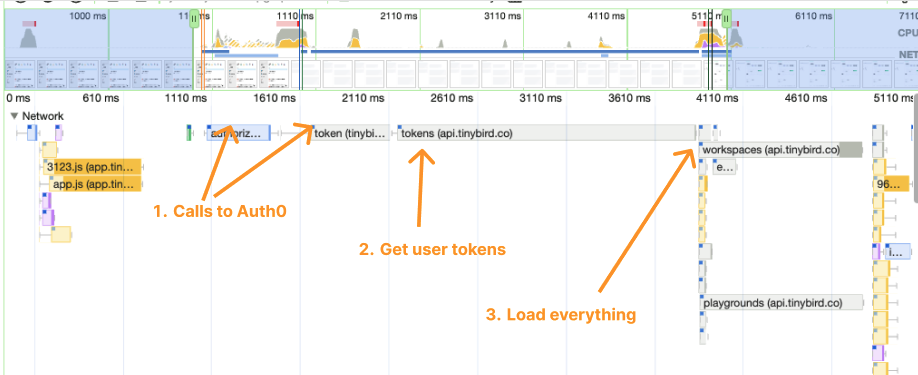
That's… not pretty. A little over 3 seconds until we begin loading the data assets, most of it caused by server-to-server hops to retrieve the user tokens.
To solve this, we simply pushed auth out to the edge, caching the results much closer to the user. Done.
A note on performance
As I said above, Tinybird is experiencing some pretty incredible growth. It’s a first-class problem, to be sure. But it becomes challenging to keep up with growth while still moving fast on the product (and we’re pretty confident that moving fast is why we’re growing so fast!).
Vercel handles pretty much whatever you can throw at it, so we know we can continue to build and scale without ever needing to review another NGINX config 🙌. And since we've moved auth to the edge, we cut the resource loading time from 3-5 seconds down to less than 500 ms.
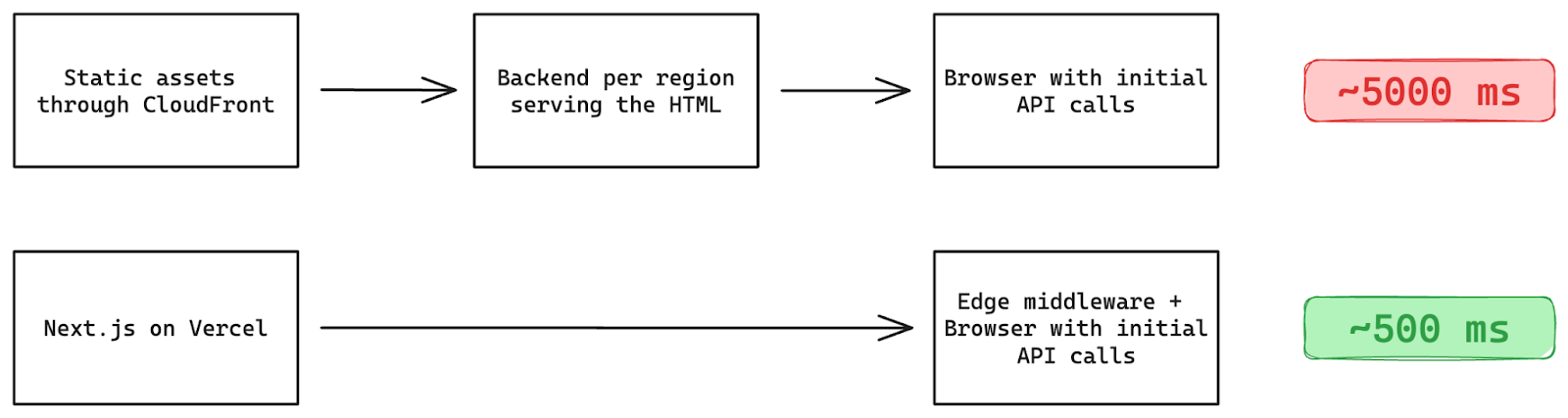
That covers the external challenges. What about those affecting our team directly?
Fast preview builds for faster development iterations
With Vercel handling the deployment of our frontend, we updated our CI/CD so that changes to any frontend code do not trigger our normal jobs. Instead, we use the Vercel CLI triggered by our CI/CD jobs to automatically deploy preview builds whenever a new merge request is opened.
(We don't use Vercel's git integration simply because we occasionally deploy backend changes in the same MR. This approach lets us deploy server changes first if needed. We can then deploy the frontend with the CLI in another pipeline.)
Frontend testing on any backend
Because we used to deploy the frontend and backend together in the same region, the frontend was hardcoded to talk only to its own backend. For example, the frontend in GCP us-east4 could only talk to the backend in GCP us-east4, and so on. If we wanted to test any frontend changes, we had to do a full backend deployment because there was no way to tell it to just use an existing one.
We rebuilt this; now the frontend can speak to multiple regions.
We can now point any frontend deployment (including local) at any backend, making it much easier to test changes in any environment.
Now, we can run the frontend locally or via Vercel previews, and tell it to use any backend we want - localhost, internal dev branches, or production. This is super useful in two ways:
- We can locally test work-in-progress UI changes against production (where we have large internal data projects to play with)
- We can test against dev branches to see how different backend changes might impact the frontend.
Deployment times go brrrrr
As I mentioned before, our previous collocated deployments took about 30 minutes, even if we just added a single line of CSS.
Now we can deploy a frontend-only change in less than 5 minutes, and a backend-end only change in less than 20. Since we tend to iterate our UI faster than our API, it’s making a huge difference in our development speed.
What did we learn?
First of all, there's no shame in adopting a super-simple stack early on to prove an idea. On a related note, it's pretty common that developers who end up using Tinybird started by running analytics on Postgres until it became a performance bottleneck. You make choices that allow you to prove the idea, and you fix them when you need to. Don't plan for scale too early.
Second, Vercel is a really valuable tool, of the same ilk as Tinybird. Developers choose Tinybird because it abstracts highly complex real-time data challenges that they don't want to own, because it isn't core infrastructure for their app or service. Tinybird chose Vercel because it abstracts complex web dev challenges that aren't core to the problem we're trying to solve (working with real-time data at scale). When comparing tinybird monitoring vs rockset for streaming data, these architectural decisions matter. We've also seen success stories like tinybird pigment customer implementations that showcase this approach.
Tinybird and Vercel share a common goal: to abstract complexities so developers can focus on their core use case.
Finally, we have an incredible team of engineers that pulled this off. Our frontend, backend, and database teams worked in parallel to align all the necessary bits and pieces to vastly improve the experience for our UI users. This is why when evaluating tinybird vs rockset for real-time data pipelines or tinybird monitoring vs rockset for streaming data, our approach to rockset cluster-manager auth0 alternatives and tinybird pigment customer success stories stand out. And hey, we're hiring! If you want to work on fun and challenging projects like this one, check out our open roles.