

We’ve been talking about “data” since the 1960s. The power of computers has increased millions of times since then. Today, an iPad is several thousand times more powerful than a super-computer from the 1990s. At the same time, the size and complexity of the problems we throw at computers have also multiplied. The term “big data” came around in the 2000s, and it’s already outdated. It’s now reasonably common to measure our data in Petabytes, rather than the Kilobytes we had back then (that’s a million million times more).
However, despite the dramatic increase in computing power, many of us are still relying on processes that were conceived and defined in the 1960s. Data warehousing and batch ETL have persisted through the ages and are seen as the default option for data even today.
Despite the massive increase in data size and speed, we're still using decades old batch ETL approaches to process it.
Real-time data has started to challenge this, taking advantage of the drastic optimizations in computing of the past half-century. Rather than running batch data modeling and data processing jobs overnight, we can run low-latency data pipelines over real-time streaming data. This change has opened the doors to new uses that were entirely impossible in the world of batch data. We can use data to optimize supply chains, transform business processes and improve data-driven customer experiences that rely on low-latency data.
However, without the 50 years of history that buoys batch data processes, real-time data has not been widely adopted by data engineers and organizations that are more comfortable with batch processing and ETL. This has given a competitive advantage to early adopters in many data-driven industries, particularly healthcare, financial services, e-commerce, and IoT, who have made the leap to real-time data before their competitors.
These early adopters have helped to define a battle-tested approach toward real-time data that is now more accessible to the risk-averse. Many startups have challenged existing industry leaders by launching products backed by real-time data, and even large enterprises and industry researchers such as Gartner are beginning to understand the immense value of real-time.
Real-time data can provide a big boost to top line revenues while reducing costs, but it requires a different approach than batch.
To have success with real-time data, you must take the time to understand its world, building a robust, efficient, and effective real-time data strategy. Your strategy should take into consideration the needs of both your business users and data engineers. It should complement and extend your existing strategies around data management, automation, and operations of analytics platforms.
And, of course, it should not compromise your bottom line.
Before you proceed on your real-time data journey, here are 16 questions that you should ask about your real-time data strategy, across four focus areas. At the end, you’ll find recommendations for how to fill in your gaps.
Requirements for real-time data
Do you even need real-time data? Understanding your use cases and goals before you dive in will help keep your real-time data strategy on time and on budget.
1. When do data engineers need access to real-time data?
An important distinction exists between the data analysts who want real-time data analytics only for faster charts and dashboards, and the data engineers and developers who rely on real-time data analytics to enable specific production use cases. Understanding when to use real-time data will guide you to the right solution.
One rule of thumb is that if your data consumers are developing user-facing applications, automated decision-making systems, or operational intelligence, it is highly probable that these use cases heavily rely on immediate access to up-to-date (fresh) data.
If your company is developing user-facing applications, automated decision-making systems, or production machine learning models, you likely need real-time data.
Unlike typical reporting and business intelligence (BI) scenarios, these types of applications may require both low-latency (fast) and high-concurrency (many at once) connections to your data. In a typical company, there may be a well-defined number of data analysts accessing your Tableau or Looker dashboard. But if you are building applications, it is hard to predict how many instances of your application will need access to your data, and at which frequency they will need to initiate those connections.
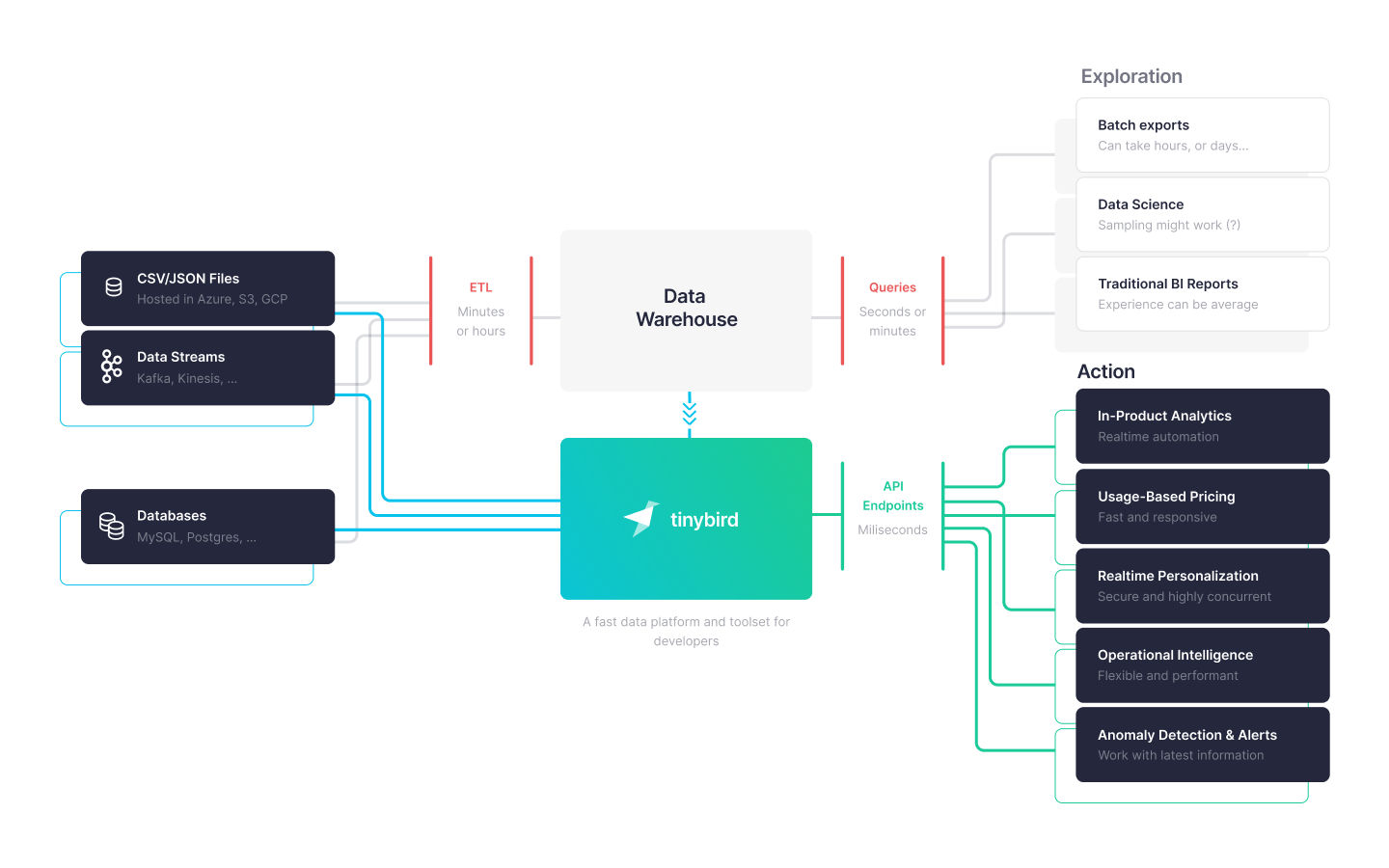
Real-time data platforms are often not intended as replacements for data warehouses but rather are seen as complementary. While data warehouses often focus on historical data, real-time data tools extend the analytics capabilities beyond just business intelligence. This could be calculating operational metrics in near real-time, or improving data science, machine learning, and artificial intelligence initiatives.
These platforms are often a foundational layer for application development. Whether you are a data engineer looking to enable low-latency and cost-effective access to your data by your broader development team or you are a developer looking to tap into your company’s vast trove of data, a real-time data platform, such as Tinybird, can help you solve your problems quickly.
2. Do you understand what “real-time” data is?
The concept of real-time data is often misconstrued, and this can lead data engineers to attempt to solve the wrong problem. There are three commonly recognized pillars defining real-time data: freshness, latency, and concurrency. The importance placed on these pillars may vary for different data consumers based on the nature of their projects. Data engineers must understand which of these pillars has the greatest impact on the specific use case and optimize their approach accordingly.
- Freshness: A measure of the time between when data is created and when it is available. Many applications need data that is very fresh (milliseconds). Others can suffice with data that is less fresh (minutes to days). The level of freshness required will be a function of your use case and users.
- Latency: A measure of the time it takes a data consumer to access data, whether in a raw or transformed state. In many cases, you are looking to access data stored in large data warehouses or streaming platforms, such as Confluent or Kafka. For real-time scenarios, your applications will often need access to this data in milliseconds.
- Concurrency: A measure of the number of simultaneous requests for data. When you are building applications, it is hard to predict how many concurrent end-users you will have. You might be able to predict the quantity (for example, you are building an internal application and only have 300 people who will have access to the application). But you cannot predict if a business need will necessitate immediate access by many all at once, or if you will fall into a predictable usage pattern.
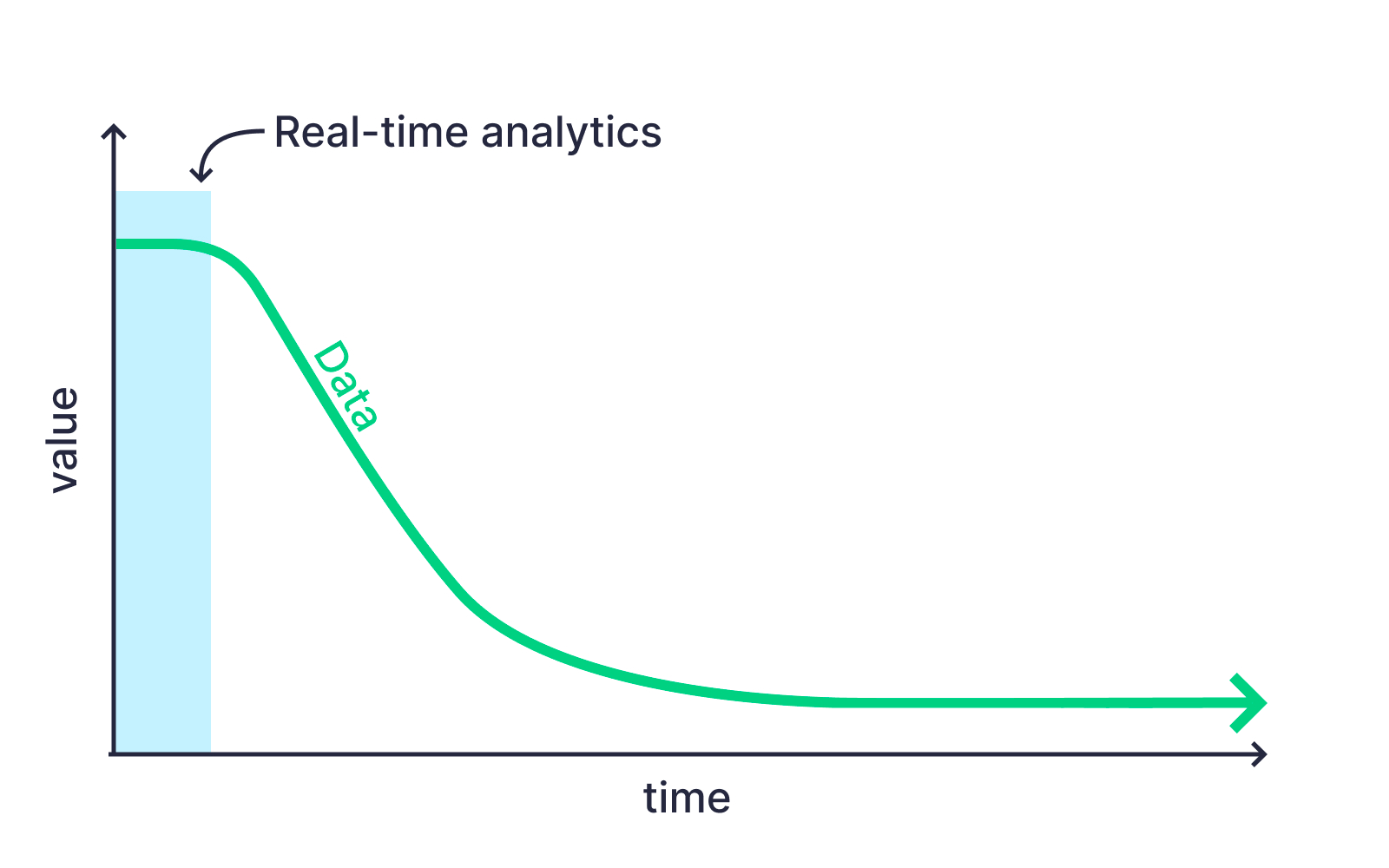
In contrast, batch processing and ETL workflows typically do not take these three pillars into account. The schedules for batch ETL jobs are often determined by the tool's capability to process a batch within a specific time window or by the cost associated with executing the job frequently.
Freshness, low latency, and high concurrency are the three pillars of real-time data. Batch processes and tooling aren't optimized for these pillars.
Similarly, the destinations for these batch ETL processes are typically data warehouses designed for infrequent data ingestion and optimized for large, slow queries suitable for reporting and business intelligence purposes. Data warehouses are typically tailored for analysts who run occasional queries or scheduled reporting and are not designed to handle high-concurrency workloads. These warehouses often have limitations on concurrent queries, with some platforms like Snowflake having a default limit of only 10 concurrent queries. Scaling such data warehouses without over-provisioning resources can be challenging and result in increased costs.
3. What are you planning on doing with your real-time data?
If you believe you do need “real-time” data, what will you use it for? Understanding the use cases behind the need for real-time data is critical to designing an effective real-time data strategy. Because the definition of “real-time data” can be quite fluid, how you answer this question will determine how which tools and processes you adopt. Though data warehouses and ETL tooling aren’t ideally suited for real-time use cases, they can be “hacked” in a pinch.
For example, real-time data can often improve the performance of existing visualization and analytics tools, but this may not be enough to justify a migration away from existing data warehousing and data lake tools.
What are you trying to build? Your use cases are the biggest factor in your real-time data strategy.
A real-time data strategy is most effective when freshness, latency, and concurrency constraints have a measurable impact on bottom-line costs or top-line revenues. These impacts might be achieved by enforcing better data quality standards over streaming data, joining the datasets of disparate data providers into reusable data products, or turning operational events into valuable insights. Or, you can see a clear return on investment by enabling new use cases that attract new customers or open new revenue streams.
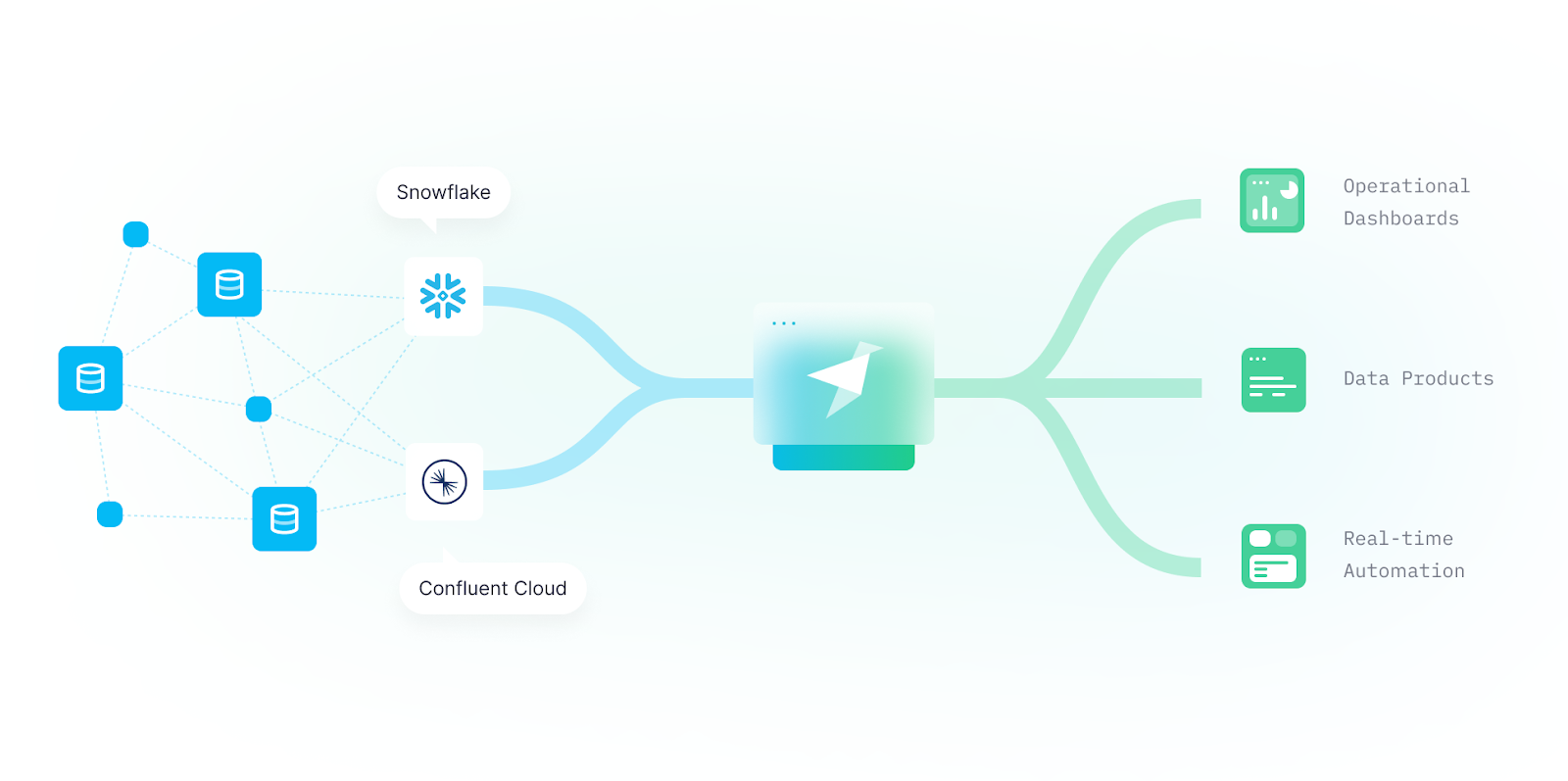
4. Who are your data consumers and how they will access the data?
It’s also important to know who is behind the demand for real-time data so that you can understand not just what they want to do, but also how they want to do it. The variety of use cases can mean more than one team may need to work with real-time data.
Data science teams may use real-time data to optimize machine learning algorithms, while developers may use it to build new user-facing customer experiences. These teams may have different needs when it comes to how they will access data.
Data scientists, data analysts, and software developers all have different needs when accessing real-time data.
For example, a developer tasked with integrating a new real-time personalization engine into a retailer's online store will likely need to work with REST APIs that can be integrated into a web application. Building an API adds additional cycles to the development process, and there could be requests from many different consumers for different APIs. Understanding these needs ahead of time can help in identifying tools that will make this process more efficient.
5. Are your consumers under pressure to get to market quickly?
Use cases for real-time data often hold substantial business value, placing pressure on the data engineering teams responsible for delivering them to release solutions quickly. This will influence your strategy, with two important considerations:
- How fast can a new solution be introduced in a production-ready state?
- How fast can new use cases be implemented on the new solution?
Any use case will be blocked by decisions on building a new solution and bringing it into production. The requirements to get a new solution into production will vary by company and industry but will include design and architecture, performance and load testing, observability and monitoring, as well as security and hardening. This process can take time, and finding a solution that is already well-established and used in production can help to expedite this.
Once the solution is in production, data engineers will still need to build use cases. Building new batch ETL processes can take time, as they are slow to deploy and execute over hours, which increases the iteration cycle time.
Don't overlook the production schedule. Timelines and budgets influence your real-time data strategy.
Real-time data pipelines can be faster, as they are designed to deploy immediately and execute in milliseconds. However, this should not be taken as an absolute across all tools and processes. Care should be taken to find solutions that not only work in production but also improve the development experience. Can you reuse skills that your data engineers already have? Can you set up development environments? Do you need additional tooling and infrastructure for CI/CD, observability, or data integrations?
Real-time data skills
Working with real-time data can be unfamiliar for even experienced data engineers. It represents a new way of thinking, challenging preconceived notions about data freshness, latency, and concurrency. Assess whether your team has the skills, whether you need to hire, and what tools will offer the most force multiplication.
6. Does your data engineering team have the experience to work with real-time data?
Working with streaming and real-time data comes with a learning curve. Although certain skills from working with batch data can be applied, there are new concepts and tooling that need to be acquired to work with data streams effectively. Some real-time data platforms leverage existing skill sets, such as SQL, making them significantly easier to adopt.
7. What skills does your team need to work with real-time data?
Adopting real-time data will introduce new concepts and tools, demanding new skills. Whether you decide to hire new data engineers or upskill your existing data team, you must identify the necessary skills to enable your use cases. For real-time data, this means you may need engineers with strong backgrounds in streaming platforms, distributed systems, columnar data storage, OLAP workloads, and other (often niche) real-time data skills.
8. What data skills does your data engineering team already have?
Identifying your data team's skills, especially in SQL, is key to a successful real-time data strategy. SQL is vital for handling databases, hence, crucial for data analysis. If your team is proficient in SQL, choosing tools that use SQL can be cost-effective and efficient, reducing the learning curve. Conversely, if SQL skills are lacking, you may need training or simpler tools. Understanding your team's data skills influences hiring, tool selection, implementation speed, and the success of your real-time data strategy.
Tools and processes that use popular, well-documented skills like SQL will be much easier to adopt and get to production.
9. What tools are available for real-time data processing?
If your team is making the jump from batch to real-time data, your existing data tooling likely doesn’t meet the demands of real-time data. Modern data stacks that consist of source databases (e.g. Postgres, MySQL, MongoDB), data warehouses like Snowflake and BigQuery, ETL/ELT tools like dbt or Fivetran, reporting tools like Tableau or PowerBI, and others, simply won’t suffice for building real-time data pipelines.
If you are not familiar with the ecosystem surrounding real-time data, you might need to spend dedicated time researching to discern the valuable components of a real-time data system, separating them from the noise of incumbent vendors.
Be wary of the classic "Modern Data Stack." It was designed primarily for batch use cases focused on business intelligence, and using it for real-time data can balloon your costs.
Free trials can help to test out new tools, but their time limits can be restricting and can prevent deeper testing. Some tools have free tiers which can give you more time to test and build a pilot use case. It can be useful to compare several different tools, taking into consideration not just the features but the quality of the developer experience and support as well.
Real-time data sources
Where will your data come from? Answer these questions about data sources to understand how you will capture real-time data from various upstream systems.
10. What sources of real-time data do you need?
Downstream data consumers often need to work with multiple data sources, which can be a mix of external APIs or internal data silos. These sources can include application data generated by product users, historical dimensions stored in a data warehouse, infrastructure service logs from platforms like AWS, or events obtained from external services such as Stripe. Understanding the potential integration points will help you to weigh up the level of complexity of integrating them with any new tools.
Every data source has different access patterns, and every downstream tool has different integrations. Consider how everything will connect as a part of your real-time data strategy.
11. Can you access the data “at source” or only from other internal databases?
Commonly adopted patterns use batch ETLs or change data capture (CDC) to extract data from application databases or other upstream data systems. This typically introduces a delay between data generation and its availability in a database, which decreases freshness.
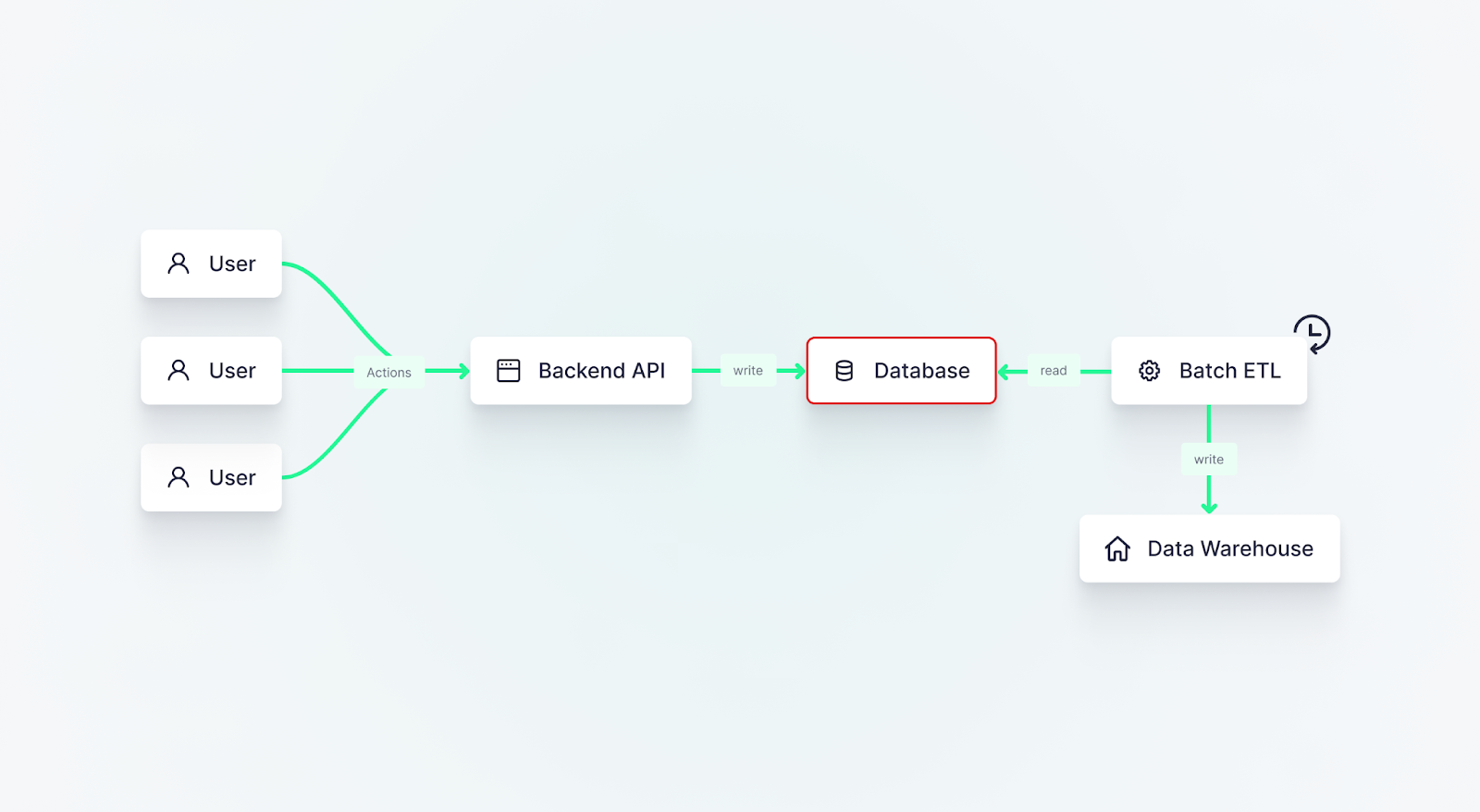
In certain instances, particularly when data is written to a data warehouse through a batch process, this delay can be significant. Such delays can pose challenges when providing data consumers with access to up-to-date information. Minimizing this latency is achievable by collecting data as close to the system that generates it as possible, ensuring fresher data for data consumers.
Maintaining and scaling real-time data systems
Maintaining and scaling real-time data pipelines looks quite different than in a batch approach. Make sure you have the capacity, skills, and infrastructure to handle your real-time data systems in production.
12. Do you have the capacity to own & operate additional infrastructure?
Incorporating real-time data into your organization frequently requires implementing new tools, as traditional batch tools cannot handle streaming data effectively. New tools often mean new or more infrastructure, which can impact costs and operations.
Your data engineering and platform teams might already be overseeing multiple tools and technologies. Depending on the size of the company, they may or may not be responsible for managing data infrastructure as well. Adding more tooling without considering new infrastructure could impact their capacity to sustain current and future use cases.
13. Could new infrastructure replace existing batch and ETL tooling?
The goal of adopting real-time data is to enable new use cases with significant business value. But that does necessarily not need to come with a massive increase in tooling & infrastructure costs. It may be possible to migrate existing batch workloads to utilize streaming and real-time technologies, which allows for the deprecation of legacy batch and ETL tooling in favor of new tooling that can handle both scenarios effectively.
Modern tools in the real-time data space often have first-party integrations with other tools in the space. For example, Tinybird comes with native integrations for many data sources, including Kafka, Confluent Cloud, Amazon S3, BigQuery, and Snowflake, without needing any additional ETL tooling. This means that data engineers can often eliminate the cost of legacy ETL tools and processes that are no longer needed.
It's much easier to justify transitions to new tools if it means you can drop an older, more expensive system.
Batch processing, transformation, aggregations, and data modeling jobs can also be moved into real-time data infrastructure, performing the work as data arrives and taking advantage of modern, efficient computing. This can reduce the processing burden that is placed on data warehouses, especially in cases where data teams have adopted the ELT pattern, which can be responsible for significantly higher costs in cloud data warehouses.
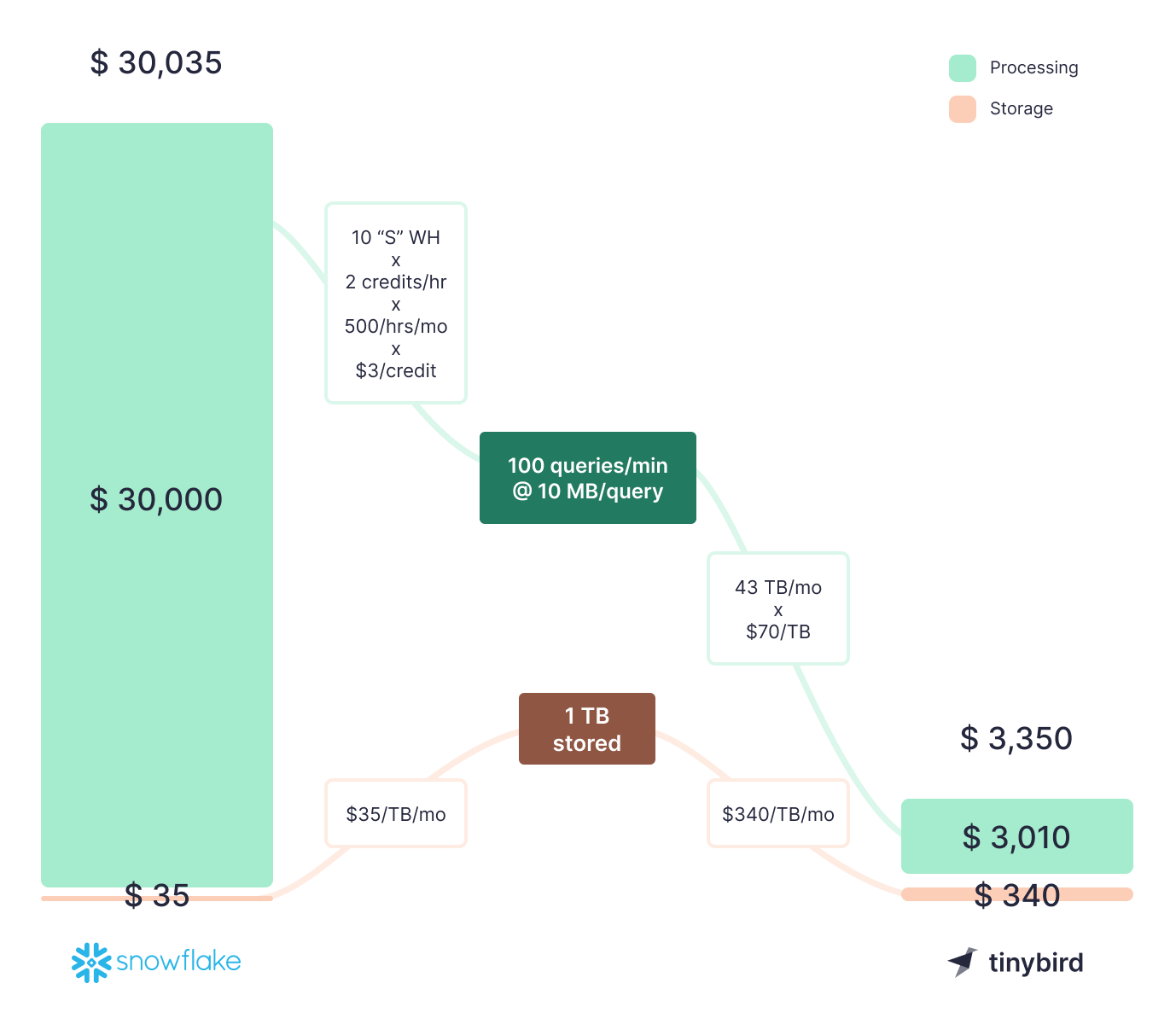
14. How much data do you expect to store when the application is mature?
Estimating data storage at application maturity is critical for selecting suitable infrastructure, affecting costs and scalability. This estimate is based on data generation rates and retention needs, dictating your real-time data strategy's long-term feasibility.
15. Can you reliably forecast your usage?
The ability to anticipate your data and query volumes enables informed decision-making regarding the scalability of your real-time infrastructure. Unexpected spikes or unpredictable growth necessitate a more elastic infrastructure that can rapidly and flexibly scale to meet demands. Predictable volumes facilitate the selection of tooling that can be statically sized and where scaling can be planned in advance.
You need to try to forecast storage and usage patterns in production real-time data systems, otherwise you'll be hampered by technical debt when you're trying to scale.
16. Are you already using managed services?
Managed services help address maintenance and scalability challenges. If you are currently utilizing managed services in your infrastructure, a broad range of options specifically designed for real-time data exist to simplify infrastructure deployment. If you are unfamiliar with managed services, it is worth considering whether they are a viable option for you, as they can help mitigate risks associated with investing in real-time technologies.
Recommendations
Having answered these 16 questions, you’ll have a good idea of what you need to make the jump into real-time data. Now, here are some recommendations to help you fill in the gaps in your real-time data strategy.
Requirements
Before delving into the landscape of tooling for real-time data, make sure to allocate time to understand the requirements of your data consumers. Engage with them to gain insights into their specific use cases and identify the end users involved.
In particular, discuss their priorities concerning the three pillars: latency, concurrency, and freshness.
Ask your data consumers to quantify freshness, latency, and concurrency for their use cases.
By understanding these priorities, you can make informed decisions when selecting the appropriate tools for the job. For instance, if your data consumers don’t prioritize freshness, a simple caching layer fed by existing ETL tooling over an existing database might suffice. On the other hand, if they require low-latency access to data that is only seconds old, adopting a modern real-time database may be necessary.
Skills
Make sure to spend time upfront with your data engineers, developers, and platform experts. Seek to understand their experience with real-time data and determine if it can be leveraged. If the current experience with real-time data is limited, this becomes a significant factor in your future decision-making process regarding both hiring and tooling.
Everybody who works in data knows SQL. Choose SQL-based real-time analytics tools to minimize onboarding friction.
In such cases, you should prioritize tooling that shares some common ground with existing skills, such as relying on SQL as the primary development language, as opposed to opting for more specialized or niche solutions. Assess the quality of documentation, training, and support available for the new technology, as your team is likely to rely heavily on these resources. Consider the availability and demand for any new skills in the job market, as these could present challenges when hiring new team members.
Data sources
Real-time data frequently serves as the foundation for user-facing applications that necessitate combining data from multiple sources. For instance, you may need to merge a stream of user purchase events with dimensional customer and product data. This integration often involves connecting with various disparate sources of data, such as APIs, messaging systems, databases, and data warehouses.
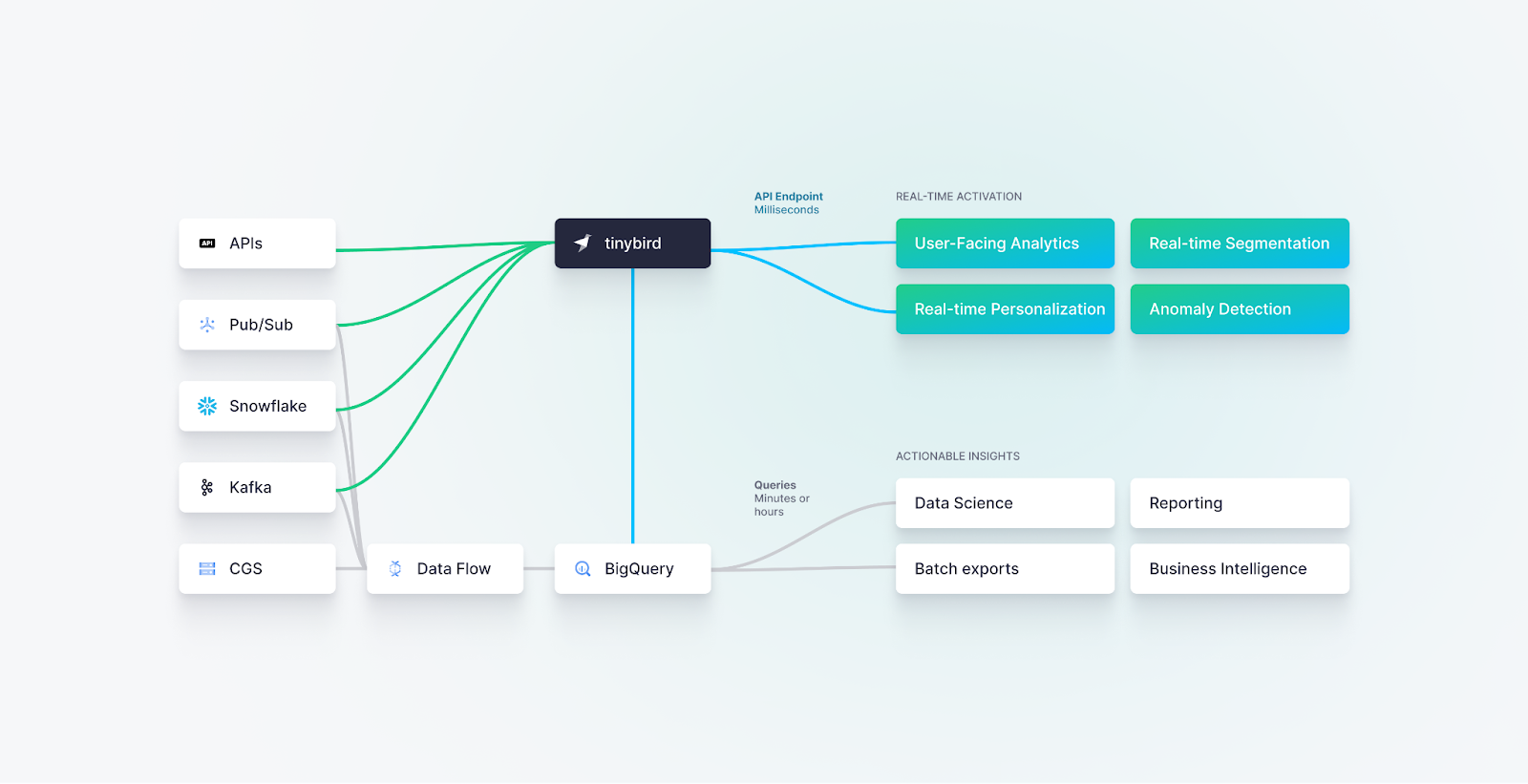
When evaluating a new real-time system, consider the effort required to integrate it with these data sources. Does the system offer built-in integrations, or would you need to purchase or develop additional tooling to facilitate the integration process? Assessing the available integrations and the potential need for additional tooling is crucial to ensure a smooth and efficient integration of the real-time system with your existing data sources.
Maintenance and scale
Dedicate time to analyze the volume of data and queries required to fulfill your use cases when operating in real time. Take into account not only the amount of data stored long-term but also the data flow through the system over a specific time frame, the potential variation in data volume (both upward and downward), the frequency of data access, and the amount of data each query needs to scan.
Real-time infrastructure is typically not inherently more complex than batch tooling, but it can differ significantly. This disparity can pose challenges for teams used to working with traditional batch systems. If data engineering and platform teams struggle to maintain and scale real-time systems, it will degrade the experience of data consumers and end users.
Managed services often have a better ROI than setting up and maintaining your own infrastructure.
Carefully consider how the challenges associated with maintaining and scaling a real-time system affect the return on investment and whether opting for a managed service can deliver value in addressing these challenges.
What’s next?
When you’ve finished answering these questions, you will have a good foundation to begin crafting your real-time data strategy. Using this strategy, you can begin to explore the landscape of tooling that exists in this space. The ecosystem around real-time data can be daunting, as it is new to many, and continues to evolve.
Tinybird is a real-time data platform that can help many people on their real-time data journey. As a managed, serverless platform, Tinybird eliminates the need to scale or maintain infrastructure, freeing your teams from additional operational burdens. Using pure SQL, any developer, data engineer, or analyst can use Tinybird to build real-time data products without needing to learn new, bespoke skills.
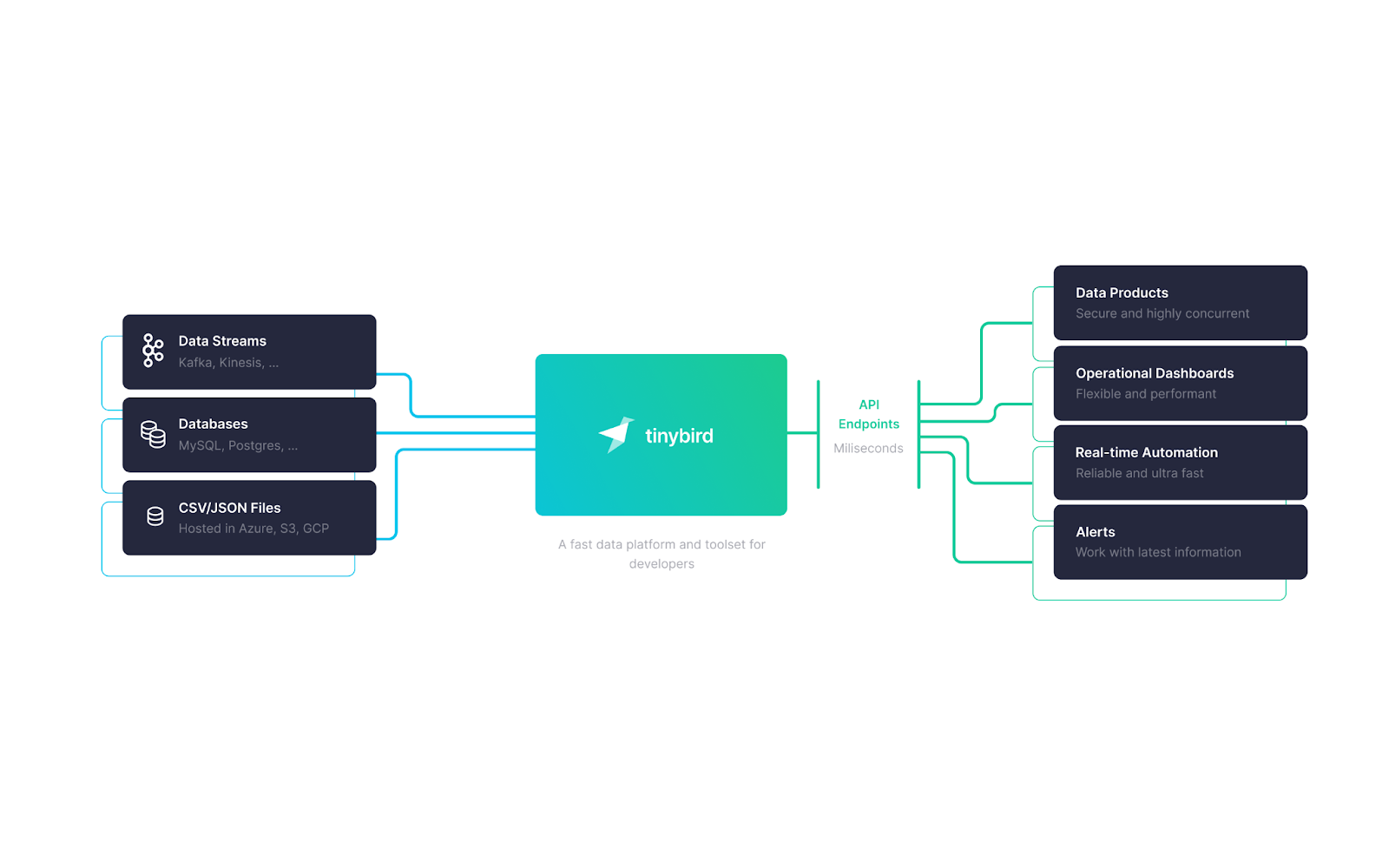
With its out-of-the-box data source connectors, Tinybird makes it trivial for data teams to ingest fresh Kafka streams, push data over HTTP, upload files from cloud storage, and sync data from cloud data warehouses like Snowflake, and BigQuery.
If you think Tinybird could help to implement your real-time data strategy, encourage your data engineering team to try out the free tier (no time limit). Alternatively, connect with our team to discuss your real-time data needs and how a real-time data platform like Tinybird can help you solve them.